ERC-7201 (anteriormente EIP-7201) es un estándar para agrupar variables de almacenamiento mediante un identificador común llamado namespace (espacio de nombres), y también para documentar el grupo de variables a través de anotaciones NatSpec. El propósito del estándar es simplificar la gestión de variables de almacenamiento durante las actualizaciones.
Namespaces
Los namespaces son un enfoque común en los lenguajes de programación como una forma de organizar y agrupar identificadores relacionados, tales como variables, funciones, clases o módulos, para evitar conflictos de nombres. Solidity no tiene de forma nativa el concepto de namespaces, pero podemos simularlo. En nuestro caso, queremos agrupar las variables de estado del contrato en un namespace.
La idea de usar namespaces en Solidity no fue propuesta por primera vez por ERC-7201; también es utilizada por el patrón diamond proxy (ERC-2535). Para comprender la importancia del uso de namespaces en los contratos inteligentes actualizables, uno debe entender el problema que ERC-7201 pretende resolver.
Un problema con la herencia
Para fines de demostración, examinemos un contrato actualizable que consta de un contrato proxy y un contrato de implementación construido mediante la herencia entre un contrato padre y un contrato hijo. En el lado de la implementación, tenemos un contrato padre y un contrato hijo, cada uno conteniendo una variable de estado en su slot inicial. La estructura de almacenamiento de estos contratos de implementación se replicará en el contrato proxy, que podría ser un transparent proxy. Para simplificar, asumamos que cada variable ocupa exactamente un slot, lo que significa que solo estamos usando variables como uint256 o bytes32.

El problema surge cuando la disposición de las variables de estado en los contratos de implementación se altera durante una actualización. Consideremos un escenario donde el contrato padre requiere la adición de una nueva variable de estado. En consecuencia, la estructura de almacenamiento se modificará de la siguiente manera:

Este escenario presenta un desafío: donde antes existía variableB, ahora se colocará variableC. La actualización alteró la disposición del almacenamiento, provocando que la nueva variableC lea el valor antiguo de variableB, lo cual es una colisión de slots.
El enfoque del gap
OpenZeppelin abordó este problema insertando un “gap” al final de cada contrato en sus contratos actualizables hasta la versión 4. A continuación, podemos observar el código del contrato ERC20Upgradeable.sol v4.9.
![fragmento de código de la variable private __gap uint256[45]](https://static.wixstatic.com/media/706568_b9dbd4392cf641d296c29878da33df6d~mv2.png/v1/fill/w_740,h_197,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/706568_b9dbd4392cf641d296c29878da33df6d~mv2.png)
El tamaño de la variable __gap se calcula de manera que el contrato siempre utilice 50 slots de almacenamiento disponibles, por lo tanto, el contrato mostrado en la figura anterior tiene 5 variables de estado. Incorporemos este concepto a nuestro ejemplo.
Si el contrato padre con 5 variables de estado incluye un array con 45 slots vacíos como gap, la estructura de almacenamiento del contrato de implementación (y proxy) se asemejará a la imagen a continuación.

Ahora, hay 45 slots vacíos disponibles para ser usados por el contrato padre en caso de una actualización. Supongamos que el contrato padre requiere agregar una nueva variable de estado, variableN; en ese escenario, simplemente insertamos esa variable antes del gap y reducimos el tamaño del gap en uno, como ilustra la animación a continuación:


El gap facilita la inserción de nuevas variables en los contratos sin interrumpir la funcionalidad existente, actuando como un marcador de posición para futuras adiciones y evitando colisiones de almacenamiento. Cuando se utiliza este enfoque, es aconsejable incluir un gap en todos los contratos de implementación.
Si bien este enfoque mitiga el problema de insertar variables en el contrato padre, no resuelve por completo todos los problemas relacionados con la alteración del layout en los contratos de implementación. Por ejemplo, si creamos un nuevo contrato padre por encima del contrato padre actual, entonces todo lo que está debajo se desplazará hacia abajo según el número de variables de almacenamiento en el nuevo padre, por lo que depender únicamente de un gap no será efectivo.

Por lo tanto, es esencial encontrar un método para ajustar el layout de los contratos de implementación sin producir colisiones de slots.
La solución óptima implicaría asignar a cada contrato de implementación en la cadena de herencia su propia ubicación de almacenamiento dedicada.
Desafortunadamente, Solidity carece actualmente de un mecanismo nativo para hacer esto (un namespace para las variables en el contrato). Por lo tanto, las construcciones de esta naturaleza deben implementarse dentro de los límites de Solidity y YUL. Esto se puede lograr usando structs. Repasemos cómo funciona el layout de almacenamiento en Solidity y cómo establecer un layout raíz basado en namespaces.
Un layout raíz basado en namespaces
El layout de almacenamiento de un contrato generado por Solidity se puede resumir de la siguiente manera, donde L representa la ubicación en el almacenamiento, n es un número natural y H(k) es una función aplicada a un tipo específico de clave k, que puede ser, por ejemplo, la clave de un mapping o el índice de un array.
La fórmula anterior indica que las variables de estado se pueden encontrar:
- En la raíz, que por defecto es el slot 0.
- En cualquier elemento de la gramática más un número natural.
- Dentro del keccak de un cierto valor calculado de forma determinista a partir de una clave y donde la variable de estado se encuentra ubicada respecto a la raíz.
Lo que debemos entender es que todas las ubicaciones en el layout de almacenamiento dependen de la raíz. Solidity asigna el valor cero a la raíz para cualquier contrato.
Si queremos crear nuestra propia ubicación para almacenar las variables de un contrato, necesitamos “cambiar” la raíz basándonos en alguna etiqueta única para ese contrato. Es precisamente esta etiqueta lo que definimos como el namespace del contrato.
El concepto de namespaces en los contratos inteligentes tiene como objetivo garantizar que la raíz del layout de almacenamiento de un contrato que usa un namespace ya no se encuentre en el slot cero, sino en un slot específico determinado por el namespace elegido.

Lograr esto únicamente con Solidity no es factible ya que el compilador siempre usa el slot cero como la raíz para el layout de almacenamiento, pero podemos encontrar una forma usando structs y assembly, como veremos en breve.
Antes de eso, examinaremos la fórmula propuesta por ERC-7201 para calcular el valor de la nueva raíz a partir de un string que sirve como namespace.
Una fórmula propuesta para calcular raíces de almacenamiento basadas en namespaces
Si vamos a “cambiar” el slot de almacenamiento raíz de un contrato con un namespace, necesitamos definir una fórmula para calcular esta nueva raíz. La fórmula propuesta en este ERC es la siguiente:
keccak256(keccak256(namespace) - 1) & ~0xff
La justificación detrás de la fórmula es la siguiente:
- Restar 1 después de generar el keccak256 del namespace garantiza que la preimagen del hash permanezca desconocida.
- Calcular el hash keccak256 una segunda vez ayuda a prevenir posibles conflictos con los slots generados por Solidity, ya que la ubicación de las variables de tamaño dinámico en el almacenamiento está determinada por un hash keccak256.
- Realizar la operación AND NOT 0xff transforma el byte más a la derecha de la ubicación a 00. Esto prepara para una futura actualización cuando Ethereum cambie su estructura de datos de almacenamiento a Verkle Trees y se puedan calentar 256 slots adyacentes a la vez.
La fórmula propuesta anteriormente se utiliza para garantizar una propiedad crucial de la nueva raíz: que no colisione con un elemento gramatical original, es decir, el espacio posible de ubicaciones de almacenamiento que el compilador de Solidity podría asignar a una variable por defecto.
Si quieres intentarlo, un contrato de Solidity que calcula el valor de la ubicación raíz a partir de un namespace dado es el siguiente:
pragma solidity ^0.8.20;
contract Erc7201 {
function getStorageAddress(
string calldata namespace
) public pure returns (bytes32) {
return
keccak256(
abi.encode(uint256(keccak256(abi.encodePacked(namespace))) - 1)
) & ~bytes32(uint256(0xff));
}
}
Si introducimos openzeppelin.storage.ERC20 obtenemos el siguiente hash.
// keccak256(abi.encode(uint256(keccak256("openzeppelin.storage.ERC20")) - 1)) ^ bytes32(uint256(0xff))
bytes32 private constant ERC20StorageLocation = 0x52C63247Ef47d19d5ce046630c49f7C67dcaEcfb71ba98eedaab2ebca6e0;
De hecho, así es como OpenZeppelin establece la raíz de almacenamiento para el ERC20UpgradeableContract v5 como veremos en la próxima sección.
Campos de struct como variables
En la última sección, vimos cómo calcular la raíz de un contrato en función de su namespace. Ahora necesitamos poder agrupar variables de almacenamiento comenzando en esa nueva raíz. No podemos declarar variables de estado porque, al hacerlo, Solidity comenzará a asignar variables desde el slot 0, lo cual queremos evitar.
Para agrupar las variables, usamos un struct. Dentro de un struct, los campos siguen el orden normal de los slots de almacenamiento. Considera el siguiente contrato:
contract StructStorage {
// **ERC-7201 uses a struct to group variables together, but the struct is never
// actually declared, nor any other state variable.**
struct MyStruct {
uint256 fieldA;
uint256 fieldB;
mapping(address => uint256) fieldC;
}
// Contract functions...
}
Hipotéticamente, si declaráramos este struct como la primera variable de almacenamiento (lo cual ERC-7201 no hace), fieldA estaría en el slot 0, fieldB estaría en el slot 1, la base del mapping fieldC estaría en el almacenamiento 2, y así sucesivamente. Una fórmula para encontrar la ubicación en el almacenamiento donde se puede escribir un campo de una variable de tipo struct es la siguiente, donde la struct base es el slot donde el struct comienza a ocupar los slots de almacenamiento.
Ten en cuenta que es la misma fórmula de antes para el layout de almacenamiento; simplemente reemplazamos la raíz con la base del struct, es decir, el struct mantiene el layout de almacenamiento a través de sus campos. Esto significa que podemos usar la struct base como la nueva raíz.
En el ejemplo anterior, la struct base es el slot cero, pero podemos elegir otro slot para que sea la base del struct. Esto se puede hacer usando YUL, como se muestra en el ejemplo a continuación.
contract StructOnStorage {
// NO STATE VARIABLES
struct MyStruct{
uint256 fieldA;
mapping(uint => uint) fieldB;
}
function setMyStruct() public {
MyStruct storage myStruct; // Grab a struct
assembly {
myStruct.slot := 0x02 // Change its base slot
}
myStruct.fieldA = 100; // FieldA will be in the first slot from the base at 0x02, which is 0x02 itself
myStruct.fieldB[10] = 101; // The storage address of this mapping item will be calculated below
}
function getMyStruct() public view returns (uint256 fieldA, uint256 fieldBSingleValue) {
// keccak256(abi.encode(key, struct base + location inside the struct)
// The mapping is located in the second slot inside the struct, so struct base + 1
bytes32 locationSingleValue = keccak256(abi.encode(0x0a, 0x02 + 1));
assembly {
fieldA := sload(0x02) // Read storage at 0x02
fieldBSingleValue := sload(locationSingleValue)
}
}
}
Cuando usamos la declaración myStruct.slot := 0x02, cambiamos explícitamente la base del struct y podemos simular un layout de almacenamiento donde la raíz ya no está en el slot cero. Dentro del struct debemos colocar todas las variables que serían variables de estado como campos del struct. La struct base sirve como la nueva raíz para sus campos, precisamente lo que pretendíamos lograr.
Una desventaja de este método es que necesitamos indicar explícitamente la base del struct cada vez que guardamos o leemos sus campos.
Dado que siempre necesitamos hacer referencia a la base del struct, se recomienda crear una función de utilidad para hacer esto. En los contratos actualizables de OpenZeppelin, existe una función privada diseñada para crear un puntero a la base del struct. Por ejemplo, en ERC20Upgradeable.sol:

A continuación, vemos cómo todas las “posibles” variables de estado deben ser declaradas como campos de un struct.
abstract contract ERC20Upgradeable is Initializable, ContextUpgradeable, IERC20, IERC20Metadata, IERC20Errors {
/// @custom:storage-location crc7201:openzeppelin.storage.ERC20
struct ERC20Storage {
mapping(address account => uint256) _balances;
mapping(address account => mapping(address spender => uint256)) _allowances;
uint256 _totalSupply;
string _name;
string _symbol;
}
Veamos un ejemplo de cómo podemos usar la función de utilidad para recuperar un campo del struct, como el nombre del token del contrato ERC20Upgradeable.sol.
/**
* @dev Returns the name of the token.
*/
function name() public view virtual returns (string memory) {
ERC20Storage storage $ = _getERC20Storage();
return $._name;
}
Como se puede ver arriba, cuando queremos recuperar variables de almacenamiento, simplemente llamamos a _getERC20StorageLocation() que devuelve la raíz de almacenamiento del namespace como bytes32.
Lo mismo aplica cuando queremos actualizar un campo. El puntero $ se encuentra en la base del struct, por lo que podemos usar la sintaxis $.[field] para leer/actualizar los campos. En la imagen a continuación, vemos un fragmento del código de la función _update del contrato ERC20Upgradeable.sol, y cómo se usa para actualizar los balances durante una transferencia.
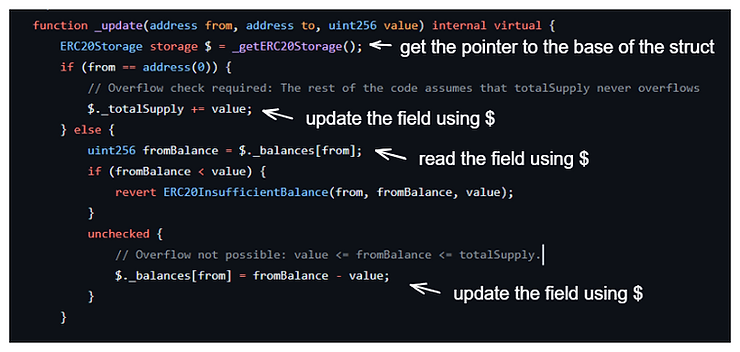
Resumen de cómo implementar un layout raíz basado en namespaces
Para implementar este patrón, simplemente sigue estos pasos:
- No uses variables de estado.
- Las que serían variables de estado deben definirse como campos en un struct.
- Elige un namespace único para el contrato.
- Usa una función para calcular la nueva raíz de este contrato a partir del namespace. ERC-7201 propone una función para ser utilizada.
- Crea una función de utilidad que devuelva una referencia a la struct base. Usa assembly para indicar explícitamente que el slot donde se ubica la base del struct es el slot calculado por la función definida en el punto anterior.
- Cada vez que leas o actualices un campo de un struct, usa la función de utilidad para apuntar a la base del struct.
En la siguiente sección, veremos cómo documentar la utilización de namespaces dentro de un contrato.
NatSpec para ubicación de almacenamiento personalizada
El Ethereum Natural Language Specification Format (NatSpec) es el método para realizar comentarios que actúan como documentación dentro de los contratos. Aquí tienes un ejemplo de un comentario NatSpec documentando una función:
/**
* @dev Returns the name of the token.
*/
Uno de los objetivos de ERC-7201 es proponer un método para documentar la utilización de namespaces en NatSpec:
@custom:storage-location <FORMULA_ID>:<NAMESPACE_ID>
FormulaID representa la fórmula utilizada para calcular la raíz de almacenamiento a partir del namespace, mientras que namespaceId se refiere al namespace específico bajo consideración. Lo que se anota es el struct, por lo que la anotación debe ir justo encima del mismo.
La fórmula propuesta en este ERC se etiqueta como erc7201, por lo que un NatSpec que utilice esta fórmula debe tener el formato:
@custom:storage-location erc7201:<NAMESPACE_ID>
Como ejemplo, en el contrato ERC20Upgradeable, el namespace elegido es openzeppelin.storage.ERC20, por lo que la anotación debería ser la siguiente
/// @custom:storage-location erc7201:openzeppelin.storage.ERC20
struct ERC20Storage {
...
}
Agradecimientos y Autoría
Este artículo fue escrito por João Paulo Morais en colaboración con RareSkills.
Nos gustaría agradecer a Hadrien Croubois (@Amxx) de OpenZeppelin por sus útiles comentarios sobre un borrador anterior de este artículo.
Publicado originalmente el 13 de junio