Introducción a Tornado Cash
Tornado Cash es un mezclador de contratos inteligentes de criptomonedas que permite a los usuarios depositar cripto con una dirección y retirar con otra billetera sin crear un enlace rastreable entre esas dos direcciones.
Tornado Cash es probablemente la aplicación de contrato inteligente de conocimiento cero (zero knowledge) más icónica, por lo que explicaremos cómo funciona a un nivel lo suficientemente bajo como para que un programador pueda reproducir la aplicación.
Se asume que el lector sabe cómo funcionan los Árboles de Merkle y que invertir un hash criptográfico es inviable. También se asume que el lector tiene al menos un nivel intermedio sólido en Solidity (ya que leeremos fragmentos del código fuente).
Tornado Cash es un contrato inteligente bastante avanzado, así que primero echa un vistazo a nuestro Tutorial de Solidity si todavía eres nuevo en el lenguaje.
Una advertencia rápida sobre Tornado Cash
Cuestiones legales
Tornado Cash está actualmente sancionado por el gobierno de los Estados Unidos, interactuar con él puede “manchar” tu billetera y causar que las transacciones desde ella sean marcadas más tarde al interactuar con exchanges centralizados.
Actualización para 2024: A partir del 28 de noviembre de 2024, la sanción ha sido levantada por el Tribunal de Apelaciones de EE. UU.
El hackeo a Tornado Cash
El 27 de mayo, los contratos inteligentes de gobernanza de Tornado Cash (no los contratos inteligentes que revisaremos aquí) fueron hackeados cuando un atacante aprobó una propuesta maliciosa que le dio la mayoría de los tokens de votación ERC20 para la gobernanza. Desde entonces han devuelto el control, quedándose con una cantidad relativamente pequeña para ellos mismos.
Cómo funciona el conocimiento cero (para programadores que odian las matemáticas)
Puedes entender cómo funciona Tornado Cash sin conocer los algoritmos de pruebas de conocimiento cero, pero debes saber cómo funcionan las pruebas de conocimiento cero. Contrario a su nombre y a muchos ejemplos populares, las pruebas de conocimiento cero (Zero Knowledge Proofs) demuestran la validez de un cálculo, no el conocimiento de un hecho determinado. No llevan a cabo el cálculo. Toman un cálculo acordado, una prueba de que el cálculo se llevó a cabo y el resultado del cálculo, para luego determinar si el probador realmente ejecutó el cálculo y produjo el resultado. La parte de conocimiento cero proviene de la característica opcional de que la prueba de cálculo puede representarse de una manera que no proporciona ninguna información sobre las entradas.
Por ejemplo, puedes demostrar que conoces los factores primos de un número sin revelarlos usando el algoritmo RSA. RSA no afirma “Conozco dos números secretos” de forma aislada; demuestra que multiplicaste dos números ocultos entre sí y generaste el número público. El cifrado RSA es en realidad solo un caso especial de las pruebas de conocimiento cero. En RSA, demuestras que conoces dos primos secretos que se multiplican entre sí para producir tu clave pública. En Zero Knowledge, generalizas esa “multiplicación mágica” a operaciones aritméticas y booleanas arbitrarias. Una vez que tenemos operaciones de conocimiento cero para operaciones elementales, podemos construir pruebas de conocimiento cero para cosas más exóticas como probar que conocemos la preimagen de funciones hash, raíces de Merkle (Merkle roots), o incluso una máquina virtual completamente funcional.
Otro punto: Una verificación de prueba de conocimiento cero no lleva a cabo el cálculo, solo verifica que alguien llevó a cabo un cálculo y produjo un resultado afirmado.
Otro corolario útil: Para generar, pero no verificar, una prueba de conocimiento cero de un cálculo, debes llevar a cabo el cálculo realmente.
Esto tiene sentido, ¿verdad? ¿Cómo podrías probar que conoces la preimagen de un hash sin aplicar realmente el hash a la preimagen? Por lo tanto, el probador lleva a cabo el cálculo en realidad y crea unos datos auxiliares conocidos como la prueba para demostrar que hizo el cálculo correctamente.
Cuando validas una firma RSA, no multiplicas los factores de la clave privada de otra persona para producir su clave pública, eso anularía el propósito. Simplemente verificas la firma y el mensaje se comprueba usando un algoritmo separado. Por lo tanto, un cálculo consiste en lo siguiente
verifier_algorithm(proof, computation, public_output) == true
En el contexto de RSA, puedes pensar en la clave pública como el resultado del cálculo, y la firma y el mensaje como la prueba de conocimiento cero.
El cálculo y el resultado son públicos. Acordamos que estamos usando una cierta función hash y obtuvimos un cierto resultado. La prueba “oculta” la entrada que se usó y solo prueba que la función hash se ejecutó y produjo el resultado.

Dada solo la prueba, un verificador no puede calcular el public_output. El paso de verificación no realiza el cálculo, solo verifica el cálculo afirmado que produce el resultado público basándose en la prueba.
No vamos a enseñar algoritmos de conocimiento cero en este artículo, pero siempre y cuando puedas aceptar que podemos probar que un cálculo tuvo lugar sin realizar el cálculo nosotros mismos, estamos listos para continuar.
Cómo funcionan las transferencias anónimas de criptomonedas: mezcla (mixing)
Fundamentalmente, la estrategia de anonimización de Tornado Cash es la mezcla (mixing), similar a otras criptomonedas anónimas como Monero. Múltiples usuarios envían su criptomoneda a una sola dirección, “mezclando” sus depósitos entre sí. Luego retiran de tal manera que el depositante y el que retira no pueden vincularse.
Imagina que 100 personas ponen billetes de un dólar en un montón. Luego aparecen 100 personas diferentes un día después y cada una retira un billete de un dólar. En este esquema, no tenemos idea de a quién intentaban enviar el dinero los depositantes originales.

Existe un problema obvio de que si cualquiera pudiera sacar el dinero en efectivo del montón, rápidamente sería robado. Pero si intentamos dejar algún metadato sobre quién tiene permitido retirar, entonces eso revelará a quién el depositante está tratando de enviarle el dinero.
La mezcla nunca puede ser totalmente privada
Cuando envías Ether a Tornado Cash, esto es completamente público. Cuando retiras de Tornado Cash, esto también es completamente público. Lo que no es público es que las dos direcciones involucradas estén asociadas entre sí (asumiendo que hay suficientes otros depositantes y personas retirando).
Todo lo que la gente puede decir sobre una dirección es “esta dirección obtuvo su Ether de Tornado Cash” o “esta otra dirección depositó en Tornado Cash”. Cuando una dirección retira de Tornado Cash, la gente no puede decir de qué depositante vino la criptomoneda.
Tornado Cash sin conocimiento cero: muchos OR lógicos de pruebas de preimagen de hash
Intentemos resolver este problema sin preocuparnos por la privacidad.
El depositante crea dos números secretos, los concatena y pone el hash de los mismos en la cadena (on-chain) al depositar el ETH (discutiremos más adelante por qué generamos dos números secretos en lugar de uno). Cuando varias personas depositan, hay varios hashes públicos guardados en un contrato inteligente de los cuales no conocemos la preimagen.
El que retira aparece, revela la preimagen (los dos números secretos) de uno de los hashes y saca su depósito.
Esto claramente falla porque muestra que el depositante le comunicó al que retira los números secretos fuera de la cadena (off-chain).
Sin embargo, si el que retira puede demostrar que conoce la preimagen de uno de los hashes sin revelar qué hash es y sin revelar la preimagen del hash, ¡entonces tenemos un mezclador de criptomonedas funcional!
La solución ingenua a esto es crear un cálculo en el que recorremos los hashes en un bucle:
zkproof_preimage_is_valid(proof, hash_{1}) OR
zkproof_preimage_is_valid(proof, hash_{2}) OR
zkproof_preimage_is_valid(proof, hash_{3}) OR
...
zkproof_preimage_is_valid(proof, hash_{n-1}) OR
zkproof_preimage_is_valid(proof, hash_{n})
Recuerda, el verificador no está realmente llevando a cabo el cálculo anterior, por lo que no sabemos cuál hash es el válido. El verificador (Tornado Cash), simplemente está verificando que el probador llevó a cabo el cálculo anterior y que devolvió verdadero (true). Cómo devolvió verdadero es irrelevante, solo que lo hizo; y solo puede devolver verdadero si el probador conoce una de las preimágenes.
Es importante notar en este punto: todos los hashes de depósito se conocen públicamente. Cuando un usuario deposita, envía el hash de los dos números secretos, y ese hash es público. Lo que estamos tratando de ocultar es de qué hash el que retira conoce la preimagen.
Pero este es un cálculo muy grande. Los grandes bucles for con muchos depósitos son costosos. [1]
Necesitamos una estructura de datos que pueda contener de forma compacta un montón de hashes en ella, y afortunadamente la tenemos: los Árboles de Merkle (Merkle Trees).
Usar árboles de Merkle para almacenar un montón de hashes
En lugar de iterar sobre todos los hashes, podemos decir “Conozco la preimagen de uno de los hashes” y “el hash está dentro del Árbol de Merkle”. Eso logra lo mismo que señalar una matriz muy larga de hashes y decir “Conozco la preimagen de uno de esos hashes”, excepto que es mucho más eficiente.
Las Pruebas de Merkle (Merkle Proofs) son logarítmicas con respecto al tamaño del árbol, por lo que no requieren demasiado trabajo adicional (en comparación con nuestro enorme bucle for de antes).
Cuando se deposita la criptomoneda, el usuario genera dos números secretos, los concatena, les aplica el hash y pone el hash en el árbol de Merkle.
En el momento del retiro, el que retira produce la preimagen de un hash de hoja (leaf hash), luego prueba que ese hash de hoja está en el árbol a través de una prueba de Merkle.
Esto, por supuesto, vincula al depositante con el que retira, pero si hacemos tanto la prueba de Merkle como la verificación de la preimagen de la hoja con conocimiento cero, ¡entonces el vínculo se rompe!
Las pruebas de conocimiento cero nos permiten probar que generamos una prueba de Merkle válida contra la raíz de Merkle pública, así como la preimagen de la hoja, sin mostrar cómo llevamos a cabo ese cálculo.
No es lo suficientemente seguro simplemente proporcionar una prueba de conocimiento cero de tener una prueba de Merkle y producir la raíz, el que retira también debe probar que conoce la preimagen de la hoja.
Las hojas del Árbol de Merkle son todas públicas. Cada vez que alguien deposita, proporciona un hash que se almacena públicamente. Dado que el árbol de Merkle es totalmente público, cualquiera puede calcular una prueba de Merkle para cualquiera de las hojas.
Por lo tanto, probar que una hoja está en el árbol no es suficiente para prevenir el robo mediante falsificación de pruebas.
El que retira también debe probar el conocimiento de la preimagen de la hoja en cuestión, sin revelar la hoja. Recuerda, la hoja en sí es el hash de dos números.
Puedes ver que el argumento _commitment en la función de depósito es público. La variable _commitment es la hoja que se agrega al árbol, la cual es el hash de los dos números secretos, que el depositante no publica.
/**
@dev Deposit funds into the contract. The caller must send (for ETH) or approve (for ERC20) value equal to or `denomination` of this instance.
@param _commitment the note commitment, which is PedersenHash(nullifier + secret)
**/
function deposit(bytes32 _commitment) external payable nonReentrant {
require(!commitments[_commitment], "The commitment has been submitted");
uint32 insertedIndex = _insert(_commitment);
commitments[_commitment] = true;
_processDeposit();
emit Deposit(_commitment, insertedIndex, block.timestamp);
}
Efectivamente, la prueba para el retiro consiste en probar que se ha llevado a cabo el siguiente cálculo:
processMerkleProof(merkleProof, hash(concat(secret1, secret2))) == root
donde processMerkleProof toma la prueba de Merkle y la hoja (leaf) como argumento, y hash(concat(secret1, secret2)) produce la hoja.
En el contexto de Tornado Cash, el verificador es el contrato inteligente de Tornado Cash que liberará los fondos a quien suministre una prueba válida.
El probador es el que retira, quien puede probar que llevó a cabo un cálculo de hash para producir una de las hojas. Generalmente, la única persona que puede retirar es la misma persona que depositó, ya que sería la única parte que puede probar que conoce las preimágenes del hash. ¡Por supuesto, este usuario debe usar una dirección diferente y completamente no asociada para el retiro!
El que retira lleva a cabo en la práctica el cálculo anterior (prueba de Merkle y generación del hash de la hoja), produce la prueba zk de que lo llevó a cabo correctamente y luego proporciona esta prueba al contrato inteligente.
El merkleProof y {secret1, secret2} están ocultos en la prueba, pero con la prueba del cálculo, un verificador puede validar que el que retira realmente ejecutó el cálculo para producir correctamente la hoja y la raíz de Merkle.
Así que resumamos:
- El Depositante:
- Genera dos números secretos y crea un hash de compromiso (commitment hash) a partir de su concatenación
- Envía un hash de compromiso
- Transfiere criptomoneda a Tornado Cash
- Tornado Cash:
- Durante la etapa de depósito:
- añade el hash de compromiso al Árbol de Merkle
- Durante la etapa de depósito:
- El que retira:
- Genera una prueba de Merkle válida para la raíz de Merkle
- Genera el hash de compromiso a partir de los dos números secretos
- Genera una prueba zk (zk-proof) de los cálculos anteriores
- Envía la prueba a Tornado Cash
- Tornado Cash
- Durante la etapa de retiro:
- verifica las pruebas contra la raíz de Merkle
- transfiere la criptomoneda al que retira
- Durante la etapa de retiro:
Prevención de retiros múltiples
El esquema anterior tiene un problema: ¿qué nos impide retirar múltiples veces? Presumiblemente, tendríamos que “eliminar” la hoja del Árbol de Merkle para dar cuenta del depósito retirado, ¡pero eso revelaría de quién es el depósito!
Tornado Cash maneja esto al no eliminar nunca las hojas del Árbol de Merkle. Una vez que se agrega una hoja al Árbol de Merkle, se queda allí para siempre.
Para prevenir retiros múltiples, el contrato inteligente utiliza lo que se llama un “esquema de anulador” (nullifier scheme), que es bastante común en aplicaciones y protocolos de conocimiento cero.
Esquema de anulador (Nullifier Scheme)
Un esquema de anulador en conocimiento cero se comporta como un nonce exótico que proporciona una capa de anonimato.
Quedará claro por qué hay dos números secretos que componen una hoja, en lugar de uno.
Los dos números que entran en el hash de depósito son el anulador (nullifier) y un secreto (secret) y la hoja es el hash del concat(nullifier, secret) en ese orden.
Durante el retiro, el usuario debe enviar el hash del anulador, es decir, el nullifierHash, y la prueba de que concatenó el anulador y el secreto y le aplicó un hash para producir una de las hojas. El contrato inteligente puede entonces verificar (usando un algoritmo de conocimiento cero) que el remitente realmente conoce la prueba de preimagen del hash del anulador.
El hash del anulador se agrega a un mapeo (mapping) para asegurar que nunca se reutilice.
Por eso necesitamos dos números secretos. Si reveláramos ambos números, ¡entonces sabríamos a qué hoja apuntaba el que retira! Al revelar solo uno de los números constituyentes, es imposible determinar con qué hoja está asociado.
Recuerda, la verificación de prueba de conocimiento cero no puede calcular el anulador dada la entrada secreta, solo puede verificar que el cálculo, el resultado y la prueba son congruentes. Es por eso que el usuario debe enviar un nullifierHash público y una prueba de que lo calculó a partir del anulador oculto.
Puedes ver esta lógica en la función de retiro de Tornado Cash cuya captura de pantalla está a continuación.

Resumamos. El usuario debe probar
- que conoce la preimagen de la hoja
- que el anulador no ha sido usado antes (esto es un simple mapping en Solidity, no un paso de verificación zk)
- que puede producir el hash del anulador y la preimagen del anulador
Aquí están los posibles resultados:
- el usuario proporciona el anulador equivocado: la prueba zk para comprobar el anulador y la preimagen del anulador no pasará
- el usuario proporciona el secreto equivocado: la prueba zk para la preimagen de la hoja no pasará
- el usuario proporciona el hash del anulador equivocado (para eludir la comprobación en la línea 86): la prueba zk para el anulador y la preimagen del anulador no pasará
El Árbol de Merkle Incremental es un Árbol de Merkle eficiente en gas
Puede que hayas notado que nos saltamos un detalle en las explicaciones anteriores. ¿Cómo se puede actualizar un Árbol de Merkle en la cadena sin quedarse sin gas? Presumiblemente hay muchos depósitos, y recalcular todo sería prohibitivo.
El Árbol de Merkle incremental elude estas restricciones con algunas optimizaciones ingeniosas. Pero antes de llegar a las optimizaciones, necesitamos entender las restricciones.
Un Árbol de Merkle incremental es un Árbol de Merkle de profundidad fija donde cada hoja comienza como un valor cero, y los valores distintos de cero se agregan reemplazando las hojas con valor cero comenzando desde la hoja más a la izquierda hasta la hoja más a la derecha, una por una.
La animación a continuación demuestra un Árbol de Merkle incremental de profundidad 3, que puede contener hasta 8 hojas. Manteniendo nuestra terminología de dominio para Tornado Cash, llamamos a estos “compromisos” (commitments) etiquetados con la variable .
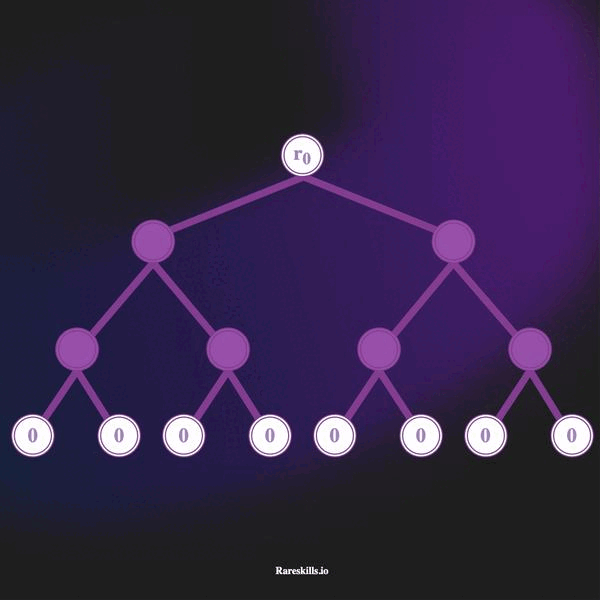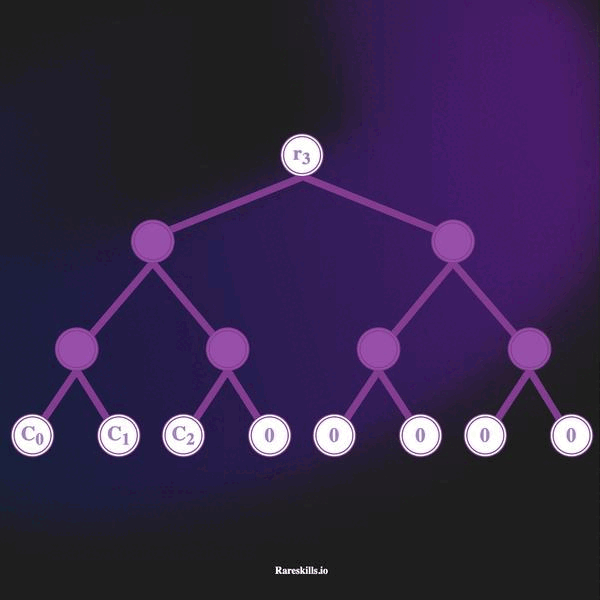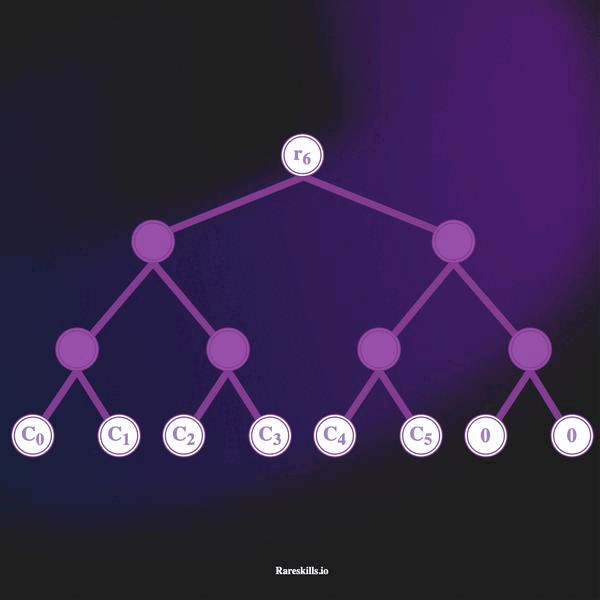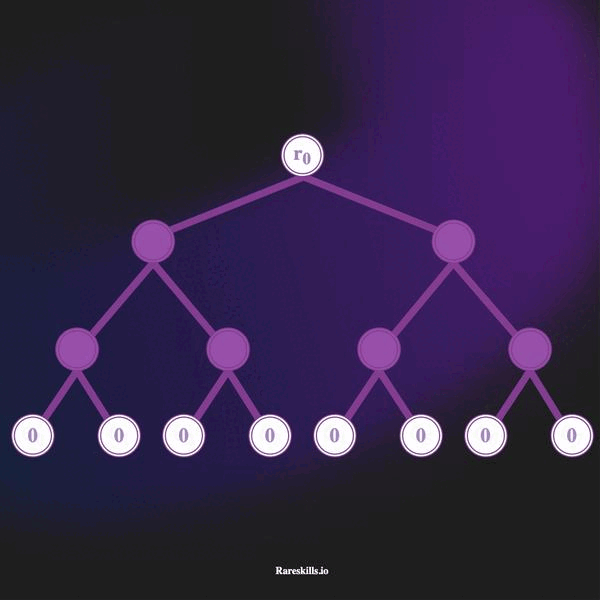
Aquí hay algunas características importantes de un árbol de Merkle incremental
- El Árbol de Merkle tiene una profundidad fija de 32. Esto significa que no puede manejar más de
2^32 - 1depósitos. (Esta es una profundidad arbitraria elegida por Tornado Cash, pero necesita ser constante). - El Árbol de Merkle comienza como un árbol donde todas las hojas son
hash(bytes32(0)). - A medida que se realizan depósitos, la hoja no utilizada más a la izquierda se sobrescribe con el hash de compromiso (commitment hash). Los depósitos se agregan a las hojas de “izquierda a derecha”.
- Una vez que se hace un depósito en el Árbol de Merkle, no puede ser removido.
- Con cada nuevo depósito, se almacena una nueva raíz. Tornado Cash llama a esto un “Árbol de Merkle con historial”. Así que Tornado Cash realmente almacena una matriz de raíces de Merkle, no una sola. Obviamente, la raíz de Merkle cambia a medida que se añaden miembros.
Ahora tenemos un problema: construir un Árbol de Merkle con 2^32 - 1 hojas en la cadena (on-chain) se quedará sin gas. Solo calcular el primer nivel requerirá más de 4 millones de iteraciones, lo que obviamente no funcionará.
Pero las restricciones de los Árboles de Merkle incrementales habilitan dos invariantes clave que permiten al contrato inteligente tomar un gran atajo computacional: todo lo que está a la derecha del nodo actual son subárboles de Merkle de altura predecible donde todas las raíces son cero, y todo lo que está a la izquierda del nodo actual puede ser almacenado en caché (cached) en lugar de ser recalculado.
Atajo ingenioso 1: todos los subárboles a la derecha del miembro más nuevo consisten en subárboles de Merkle con todas las hojas en cero
Los subárboles de Merkle con todas las hojas en cero tienen raíces predecibles que pueden ser precalculadas.
Dado que todas las hojas comienzan en cero, una cantidad significativa del trabajo destinado a construir el Árbol de Merkle incluirá calcular Árboles de Merkle donde todas las hojas son cero.
Mira la imagen a continuación y nota cuánto cálculo se repite cuando todas las hojas son cero:

La mayoría de los pares de hojas van a ser la concatenación de bytes32(0) y bytes32(0). Luego ese hash se va a concatenar con un hash idéntico del subárbol hermano, y así sucesivamente.
Tornado Cash precalcula el hash de un árbol de profundidad cero (solo el hash de una hoja bytes32(0)), la raíz de un subárbol con dos hojas de ceros, la raíz de un subárbol con cuatro hojas de ceros, la raíz de un subárbol con ocho hojas de ceros, y así sucesivamente.
Esto significa que podemos precalcular la raíz de Merkle para un Árbol de Merkle (con todas las hojas en cero) de altura 0, 1, 2, etc. hasta 31 (recuerda, la altura del Árbol de Merkle es fija).
Para cada altura posible de un subárbol de Merkle donde todas las hojas son cero, Tornado Cash lo precalcula. Aquí está la lista precalculada en el Árbol de Merkle con Historial de Tornado Cash:
/// @dev provides Zero (Empty) elements for a MiMC MerkleTree. Up to 32 levels
function zeros(uint256 i) public pure returns (bytes32) {
if (i == 0) return bytes32(0x2fe54c60d3acabf3343a35b6eba15db4821b340f76e741e2249685ed4899af6c);
else if (i == 1) return bytes32(0x256a6135777eee2fd26f54b8b7037a25439d5235caee224154186d2b8a52e31d);
else if (i == 2) return bytes32(0x1151949895e82ab19924de92c40a3d6f7bcb60d92b00504b8199613683f0c200);
else if (i == 3) return bytes32(0x20121ee811489ff8d61f09fb89e313f14959a0f28bb428a20dba6b0b068b3bdb);
else if (i == 4) return bytes32(0x0a89ca6ffa14cc462cfedb842c30ed221a50a3d6bf022a6a57dc82ab24c157c9);
else if (i == 5) return bytes32(0x24ca05c2b5cd42e890d6be94c68d0689f4f21c9cec9c0f13fe41d566dfb54959);
else if (i == 6) return bytes32(0x1ccb97c932565a92c60156bdba2d08f3bf1377464e025cee765679e604a7315c);
else if (i == 7) return bytes32(0x19156fbd7d1a8bf5cba8909367de1b624534ebab4f0f79e003bccdd1b182bdb4);
else if (i == 8) return bytes32(0x261af8c1f0912e465744641409f622d466c3920ac6e5ff37e36604cb11dfff80);
else if (i == 9) return bytes32(0x0058459724ff6ca5a1652fcbc3e82b93895cf08e975b19beab3f54c217d1c007);
else if (i == 10) return bytes32(0x1f04ef20dee48d39984d8eabe768a70eafa6310ad20849d4573c3c40c2ad1e30);
else if (i == 11) return bytes32(0x1bea3dec5dab51567ce7e200a30f7ba6d4276aeaa53e2686f962a46c66d511e5);
else if (i == 12) return bytes32(0x0ee0f941e2da4b9e31c3ca97a40d8fa9ce68d97c084177071b3cb46cd3372f0f);
else if (i == 13) return bytes32(0x1ca9503e8935884501bbaf20be14eb4c46b89772c97b96e3b2ebf3a36a948bbd);
else if (i == 14) return bytes32(0x133a80e30697cd55d8f7d4b0965b7be24057ba5dc3da898ee2187232446cb108);
else if (i == 15) return bytes32(0x13e6d8fc88839ed76e182c2a779af5b2c0da9dd18c90427a644f7e148a6253b6);
else if (i == 16) return bytes32(0x1eb16b057a477f4bc8f572ea6bee39561098f78f15bfb3699dcbb7bd8db61854);
else if (i == 17) return bytes32(0x0da2cb16a1ceaabf1c16b838f7a9e3f2a3a3088d9e0a6debaa748114620696ea);
else if (i == 18) return bytes32(0x24a3b3d822420b14b5d8cb6c28a574f01e98ea9e940551d2ebd75cee12649f9d);
else if (i == 19) return bytes32(0x198622acbd783d1b0d9064105b1fc8e4d8889de95c4c519b3f635809fe6afc05);
else if (i == 20) return bytes32(0x29d7ed391256ccc3ea596c86e933b89ff339d25ea8ddced975ae2fe30b5296d4);
else if (i == 21) return bytes32(0x19be59f2f0413ce78c0c3703a3a5451b1d7f39629fa33abd11548a76065b2967);
else if (i == 22) return bytes32(0x1ff3f61797e538b70e619310d33f2a063e7eb59104e112e95738da1254dc3453);
else if (i == 23) return bytes32(0x10c16ae9959cf8358980d9dd9616e48228737310a10e2b6b731c1a548f036c48);
else if (i == 24) return bytes32(0x0ba433a63174a90ac20992e75e3095496812b652685b5e1a2eae0b1bf4e8fcd1);
else if (i == 25) return bytes32(0x019ddb9df2bc98d987d0dfeca9d2b643deafab8f7036562e627c3667266a044c);
else if (i == 26) return bytes32(0x2d3c88b23175c5a5565db928414c66d1912b11acf974b2e644caaac04739ce99);
else if (i == 27) return bytes32(0x2eab55f6ae4e66e32c5189eed5c470840863445760f5ed7e7b69b2a62600f354);
else if (i == 28) return bytes32(0x002df37a2642621802383cf952bf4dd1f32e05433beeb1fd41031fb7eace979d);
else if (i == 29) return bytes32(0x104aeb41435db66c3e62feccc1d6f5d98d0a0ed75d1374db457cf462e3a1f427);
else if (i == 30) return bytes32(0x1f3c6fd858e9a7d4b0d1f38e256a09d81d5a5e3c963987e2d4b814cfab7c6ebb);
else if (i == 31) return bytes32(0x2c7a07d20dff79d01fecedc1134284a8d08436606c93693b67e333f671bf69cc);
else revert("Index out of bounds");
}
Al calcular la raíz de Merkle, siempre sabemos en qué “nivel z” (“z-level”) nos encontramos y podemos simplemente obtener la raíz precalculada del subárbol de Merkle donde todas las hojas son cero.
Un tecnicismo sobre las “raíces cero”
Tornado Cash en realidad no usa el hash(bytes32(0)) como el valor vacío, utiliza hash(“tornado”). Esto no afecta al algoritmo, ya que es solo una constante. Sin embargo, es más fácil discutir los Árboles de Merkle Incrementales usando la noción de que la “ceridad” (zeroness) sea cero en lugar de una constante curiosa.
Atajo ingenioso 2: todos los subárboles a la izquierda del miembro más nuevo consisten en subárboles cuyas raíces pueden almacenarse en caché en lugar de recalcularse
Considera el caso donde agregamos el segundo depósito. Ya hemos calculado el hash del primer depósito. Ese hash se almacena en caché en un mapping que Tornado Cash llama filledSubtrees. Un filledSubtree es simplemente un subárbol en el Árbol de Merkle donde todas las hojas son distintas de cero. Llamamos a eso fs en la animación a continuación:

El punto es que, en cualquier momento que necesites un hash intermedio a la izquierda, ya ha sido calculado para ti.
Esta buena característica es un subproducto de la restricción de que las hojas no pueden ser cambiadas o eliminadas. Una vez que un subárbol está lleno de compromisos en lugar de ceros, nunca necesita ser recalculado.
Ahora generalicemos esto. En lugar de ver el nodo a nuestra izquierda como el “primer depósito”, imagina que en sí mismo es la raíz de un subárbol.
En el caso más extremo, considera cuando colocamos la última hoja. A nuestra izquierda inmediata habrá un “árbol” que consta de la penúltima hoja (profundidad 0), a la izquierda de ese habrá un subárbol de profundidad 1, a la izquierda de ese habrá un subárbol de profundidad 2 (con 4 hojas), a la izquierda de ese habrá un subárbol de profundidad 3 (con 8 hojas), etc. No habrá más de 32 de estos árboles en el caso más extremo.
Combinando los atajos
Todo lo que está a nuestra izquierda es un subárbol lleno (incluso si es solo una hoja) y todo lo que está a nuestra derecha es siempre una hoja cero o un subárbol que consta de puras hojas cero. Dado que la raíz izquierda está almacenada en caché y la raíz derecha está precalculada a partir de un subárbol de altura de puros ceros, podemos calcular cualquier concatenación de hash intermedia en cualquier nivel de manera eficiente, y generar un Árbol de Merkle de profundidad 32 en la cadena con solo 32 iteraciones. Esto no es barato, pero es factible. ¡Sin duda es mucho mejor que 4 millones de cálculos!
¿Hash a la izquierda o hash a la derecha?
Pero a medida que “aplicamos hashes en nuestro camino hacia la raíz”, ¿cómo sabemos en qué orden concatenar los hashes de los subárboles?
Por ejemplo, tomamos un nuevo hash de compromiso y lo añadimos como hoja. En el nodo superior a nosotros, ¿lo concatenamos como new_commitment | other_value o other_value | new_commitment?
Aquí está el truco: cada nodo indexado como par es un hijo izquierdo, y cada nodo indexado como impar es un hijo derecho. Esto es cierto para los nodos hoja y para cada nivel del árbol. Puedes ver este patrón en el diagrama a continuación.

Tengamos una intuición para el patrón. Si se inserta la hoja cero, entonces solo vamos a aplicar hash hacia la derecha en el camino a la raíz. 0 ÷ 2 seguirá siendo cero, y cero es un número par usando la definición anterior. Debido a que cero es par, siempre aplicaremos hash hacia la derecha en nuestro camino a la raíz.
Ahora veamos el otro caso extremo. Cuando se inserta la última hoja, uno siempre debe aplicar hash a la izquierda en el camino a la raíz. Cada nodo en el camino hacia la cima es impar. Este patrón se generaliza a todos los nodos en el medio; comenzar con el índice de la hoja y dividir repetidamente por dos a medida que subimos por el árbol nos dirá si estamos en un hijo izquierdo o en un hijo derecho. La siguiente animación ilustra que aplicamos hash a la izquierda cuando estamos en un nodo impar y hash a la derecha cuando estamos en un nodo par:
Así que en cualquier nivel, sabemos dónde va nuestro hash en relación con el hermano.
Por lo tanto, hay dos datos que necesitamos:
- el índice del nodo que estamos insertando
- si el índice actual es par o impar
Aquí hay una captura de pantalla del código fuente de Tornado Cash usando esa información. El bucle for itera sobre los niveles para regenerar la raíz de Merkle basándose en la nueva hoja que se acaba de agregar.

En resumen, para actualizar la raíz de Merkle en la cadena (on-chain), nosotros:
- agregamos una hoja en un nuevo índice, estableciéndolo en
currentIndex - subimos un nivel y establecemos
currentIndexpara que seacurrentIndexdividido portwo(dos). Luego,- aplicamos hash a la izquierda con un
filledSubtreesi elcurrentIndexesodd(impar) - aplicamos hash a la derecha con un árbol de ceros
precomputed(precalculado) si elcurrentIndexeseven(par).
- aplicamos hash a la izquierda con un
Es bastante genial que un algoritmo no trivial como este pueda comprimirse en una pequeña representación en Solidity.
Tornado Cash almacena las últimas 30 raíces, ya que la raíz sigue cambiando con cada depósito
Cada vez que se inserta un elemento, la raíz de Merkle debe necesariamente cambiar. Esto podría crear un problema si alguien que retira crea una prueba de Merkle para la última raíz (recuerda, las hojas están todas disponibles públicamente) pero una transacción de depósito entra primero y cambia la raíz; entonces la prueba de Merkle ya no sería válida. El algoritmo verificador zk asegura que la prueba de la prueba de Merkle sea válida para la raíz, así que si la raíz cambia, la prueba no se verificará.
Para darle tiempo a la persona que retira para efectuar su transacción, puede hacer referencia a hasta las últimas 30 raíces.
La variable roots es un mapping de uint256 a bytes32. Cuando la prueba de Merkle ha alcanzado la raíz (el bucle se completa) se almacena en roots. El currentRootIndex se incrementa hasta el ROOT_HISTORY_SIZE, pero una vez que alcanza el valor máximo (30) sobrescribe la raíz en el índice cero. Por lo tanto, se comporta como una cola de tamaño fijo. A continuación se muestra un fragmento de la función _insert del código del Árbol de Merkle de Tornado Cash. Después de que la raíz se recalcula, se almacena de la manera descrita anteriormente.

Variables de almacenamiento para el Árbol de Merkle Incremental
Aquí están las variables de almacenamiento necesarias para que funcione el Árbol de Merkle con historial.
mapping(uint256 => bytes32) public filledSubtrees;
mapping(uint256 => bytes32) public roots;
uint32 public constant ROOT_HISTORY_SIZE = 30;
uint32 public currentRootIndex = 0;
uint32 public nextIndex = 0;
filledSubtreesson los subárboles que ya hemos calculado (es decir, todas las hojas son distintas de cero)rootsson las últimas 30 raícescurrentRootIndexes un número del 0 al 29 para indexar dentro derootsnextIndexes la hoja actual que se llenará si el usuario llama a Deposit.
Cómo la función pública deposit() actualiza el Árbol de Merkle Incremental
Cuando un usuario llama a deposit en Tornado Cash, se llama a _insert() para actualizar el Árbol de Merkle, y luego se llama a _processDeposit().
function deposit(bytes32 _commitment) external payable nonReentrant {
require(!commitments[_commitment], "The commitment has been submitted");
uint32 insertedIndex = _insert(_commitment);
commitments[_commitment] = true;
_processDeposit();
emit Deposit(_commitment, insertedIndex, block.timestamp);
}
_processDeposit() simplemente se asegura de que la denominación sea precisa (solo puedes depositar 0.1, 1 o 10 Ether dependiendo de la instancia de Tornado Cash con la que interactúes). El código para esa operación tan simple está a continuación.
function _processDeposit() internal override {
require(msg.value == denomination, "Please send `mixDenomination` ETH along with transaction");
}
Hash MiMC hiperoptimizado
Para calcular la raíz de Merkle en la cadena, uno debe usar un algoritmo de hash (obviamente) pero Tornado Cash no está usando el tradicional keccak256; en su lugar utiliza MiMC.
El porqué es esto está un poco fuera del alcance, pero la razón es que algunos hashes son computacionalmente más baratos para la generación de pruebas de conocimiento cero que otros. MiMC fue diseñado para ser “zk friendly” (amigable con zk) pero keccak256 no lo era.
“Zk friendly” significa que el algoritmo se mapea naturalmente a cómo los algoritmos de pruebas de conocimiento cero representan los cálculos.
Pero esto crea un curioso dilema, ya que el MiMC debe ser calculado en la cadena para recalcular la raíz cuando se agrega un nuevo nodo, y Ethereum no tiene contratos precompilados para hashes amigables con zk. (¿Tal vez podrías crear un EIP para esto?)
Por lo tanto, el equipo de Tornado Cash lo escribió ellos mismos en raw bytecode. Si observas la verificación del contrato en Etherscan para Tornado Cash, verás una advertencia:

Etherscan no puede verificar raw bytecode a Solidity, ya que el hash MiMC no fue escrito en Solidity.
El equipo de Tornado Cash desplegó el MiMC Hasher como un contrato inteligente separado. Para usar el hash MiMC, el código del Árbol de Merkle hace una llamada entre contratos a ese contrato. Como puedes ver en el código a continuación, estas son static calls (llamadas estáticas), ya que la interfaz lo define como pure, por lo tanto Etherscan muestra que no tiene historial de transacciones.
interface IHasher {
function MiMCSponge(uint256 in_xL, uint256 in_xR) external pure returns (uint256 xL, uint256 xR);
}
Sabemos que es una “interface” basado en el código en Tornado Cash referenciado anteriormente. (enlace a github).
En un issue de github de la librería circom, puedes ver la justificación de por qué el código no tiene una versión en Solidity, ni siquiera con bloques en assembly: la manipulación directa de la pila (stack) no es posible.
(Nota al margen: los algoritmos de criptografía de muy bajo nivel son un caso de uso fantástico para el lenguaje Huff, que puedes aprender con nuestros Puzzles del Lenguaje Huff).
Desplegar tu propia función hash como raw bytecode
El repositorio de circomlib js contiene herramientas en javascript para crear hashes de raw bytecode. Aquí está el código para generar MiMC y el Poseidon Hash.
Retirar de Tornado Cash
Para empezar, el usuario debe reconstruir el Árbol de Merkle localmente usando el script updateTree. Este script descargará todos los eventos de solidity relevantes y reconstruirá el Árbol de Merkle. Luego, el usuario generará una prueba de conocimiento cero de la prueba de Merkle y las preimágenes de compromiso de la hoja. Como se discutió anteriormente, Tornado Cash almacena las últimas 30 raíces de Merkle, por lo que este debería ser tiempo suficiente para que el usuario envíe su prueba. Si un usuario genera una prueba y espera demasiado tiempo, tendrá que regenerar la prueba.
El contrato de Tornado Cash verificará que:
- El
nullifierHashenviado no se haya utilizado antes - La raíz esté en el historial de raíces (últimas 30 raíces)
- La prueba de conocimiento cero sea correcta:
a. La preimagen del hash oculto genera la hoja
b. El usuario realmente conoce la preimagen delnullifierHash
c. El usuario creó una prueba de Merkle utilizando esa hoja que resulta en la raíz propuesta.
d. La raíz propuesta es una de las últimas 30 raíces (esto se verifica públicamente en el código de Solidity)
Aquí hay una visualización de los pasos anteriores:

Con esa comprensión, el código de la función withdraw de Tornado Cash a continuación debería explicarse por sí mismo.
function withdraw(bytes calldata _proof,
bytes32 _root,
bytes32 _nullifierHash,
address payable _recipient,
address payable _relayer,
uint256 _fee,
uint256 _refund
) external payable nonReentrant {
require(_fee <= denomination, "Fee exceeds transfer value");
require(!nullifierHashes[_nullifierHash], "The note has been already spent");
require(isKnownRoot(_root), "Cannot find your merkle root"); // Make sure to use a recent onerequire(
verifier.verifyProof(
_proof,
[uint256(_root), uint256(_nullifierHash), uint256(_recipient), uint256(_relayer), _fee, _refund]
),
"Invalid withdraw proof"
);
nullifierHashes[_nullifierHash] = true;
_processWithdraw(_recipient, _relayer, _fee, _refund);
emit Withdrawal(_recipient, _nullifierHash, _relayer, _fee);
}
El _relayer, _fee y _refund de arriba tienen que ver con el pago de tarifas a relayers de transacciones opcionales, lo cual explicaremos en breve.
La función isKnownRoot(root) valida que la raíz propuesta sea una de las últimas 30
Este es un simple bucle do-while que itera hacia atrás desde el índice actual (la última hoja activa) para ver si la raíz enviada a la función withdraw está en el historial de raíces. (enlace a github)
Debido a que solo hay una retrospectiva de 30, no tenemos que preocuparnos por bucles ilimitados que consuman demasiado gas.
/**
@dev Whether the root is present in the root history
*/function isKnownRoot(bytes32 _root) public view returns (bool) {
if (_root == 0) {
return false;
}
uint32 _currentRootIndex = currentRootIndex;
uint32 i = _currentRootIndex;
do {
if (_root == roots[i]) {
return true;
}
if (i == 0) {
i = ROOT_HISTORY_SIZE; // 30
}
i--;
} while (i != _currentRootIndex);
return false;
}
Código de Circom para definir el cálculo de la prueba de conocimiento cero
Esta sección describe el código de circom utilizado para generar los circuitos que verifican la prueba ZK. Si no estás familiarizado con Circom y deseas aprenderlo, consulta nuestros puzzles de conocimiento cero en Circom.
Sin embargo, intentaremos explicar el código de Circom a un alto nivel.
Circom no se ejecuta en la blockchain, es transpilado a un aterrador código de Solidity que puedes ver en el Verifier.sol de Tornado Cash. La razón por la que parece tan aterrador es que en realidad está ejecutando las matemáticas para la verificación de la prueba zk. Afortunadamente, Circom es mucho más legible.

Aquí tenemos tres componentes: HashLeftRight que combina hashes, DualMux (que es solo una utilidad para MerkleTreeChecker) y MerkleTreeChecker. El MerkleTreeChecker toma una leaf, una root y una proof. La proof tiene dos partes: los pathElements (la raíz de Merkle del subárbol hermano) y los pathIndices (un indicador para que el circuito sepa en qué orden concatenar los hashes para ese nivel).
La línea final, root === hashers[levels - 1].hash es donde finalmente se determina que la raíz coincide con la leaf y la proof.
Recuerda que el nullifierHash es el hash del nullifier y el commitment es el hash del nullifier y el secret. La representación en Circom de este cálculo se encuentra a continuación. Aunque puede ser difícil de leer, debería quedar claro que las entradas son el nullifier y el secret, y las salidas son el commitment y el nullifierHash.

Ahora podemos llegar al núcleo del algoritmo de conocimiento cero

Una señal privada (private signal) significa que está “oculta en la prueba” utilizando la nomenclatura de antes.
En el código anterior, el código verifica que el cálculo del hash del nullifier se haya realizado de manera válida. Luego, la preimagen de compromiso y la prueba de Merkle se proporcionan al Verificador del Árbol de Merkle mencionado anteriormente.
Si todo es correcto, el verifier devolverá true, denotando que la prueba es válida, y la dirección anónima podrá retirar el depósito.
Prevención de frontrunning durante el retiro
Los investigadores de seguridad pueden haber notado que el código en Solidity no tiene defensa contra el frontrunning. Cuando alguien envía una prueba de conocimiento cero válida a la mempool, ¿qué impide que alguien copie la prueba y sustituya la dirección de retiro por la suya propia?
Esto es algo que pasamos por alto por simplicidad, pero el archivo Withdraw.circom incluye señales ficticias que elevan al cuadrado el destinatario (y los otros parámetros necesarios para los relayers). Esto significa que la prueba zk también debe demostrar que el que retira elevó al cuadrado la dirección del destinatario y obtuvo el cuadrado de su dirección (recuerda, las direcciones son solo números de 20 bytes). Calcular el cuadrado de las direcciones y el hash del nullifier y el secret es un solo cálculo, por lo que equivocarse en cualquier parte de esto invalida toda la prueba.

¿Qué es un relayer y una tarifa (fee)?
Un relayer es un bot fuera de la cadena (off-chain) que paga el gas de otros usuarios a cambio de algún tipo de pago. Los que retiran de Tornado Cash generalmente quieren usar direcciones completamente nuevas para mejorar la privacidad, pero las direcciones completamente nuevas no tienen gas para pagar el retiro.
Para resolver esto, la persona que retira puede pedirle a un relayer que realice la transacción a cambio de recibir una parte del retiro de Tornado Cash.
La dirección de retiro del relayer también debe utilizar la misma protección contra frontrunning descrita anteriormente, y eso se puede ver en la captura de pantalla del código de arriba.
Resumen de un deposit() y un withdrawal()
Cuando se llama a deposit:
- El usuario envía
hash(concat(nullifier, secret)), junto con la criptomoneda que está depositando. - Tornado Cash valida que la cantidad depositada sea la denominación que acepta.
- Tornado Cash agrega el compromiso a la siguiente hoja. Las hojas nunca se eliminan.
Cuando se llama a withdraw:
- El usuario reconstruye el Árbol de Merkle basado en los eventos emitidos por Tornado Cash
- El usuario debe suministrar el hash del
nullifier(públicamente), la raíz de Merkle contra la que está verificando, y una prueba zk de que conoce elnullifier, elsecrety la prueba de Merkle - Tornado Cash verifica que el
nullifierno se haya usado antes - Tornado Cash verifica que la raíz propuesta sea una de las últimas 30 raíces
- Tornado Cash verifica la prueba de conocimiento cero
No hay nada que impida a un usuario enviar una hoja sin sentido sin ninguna preimagen conocida. En ese caso, la criptomoneda enviada permanecerá atascada en el contrato para siempre.
Una visión general rápida de la arquitectura del contrato inteligente
Los siguientes son los contratos inteligentes que componen Tornado Cash

Tornado.sol es un contrato abstracto que en realidad es implementado por ERC20Tornado.sol o ETHTornado.sol dependiendo de si el despliegue está destinado a mezclar ERC20s o una cierta denominación de ETH. Las diferentes denominaciones de ETH y los tokens ERC20 tienen su propia instancia de Tornado Cash.
MerkleTreeWithHistory.sol contiene la funcionalidad _insert() e isKnownRoot() que discutimos en detalle anteriormente.
Verifier.sol es el resultado de la transpilación a Solidity de los circuitos de Circom.
cTornado.sol es el token ERC20 para la gobernanza, y no es parte del protocolo principal.
Dónde Tornado Cash podría mejorar la eficiencia del gas
Tornado Cash en general está muy bien diseñado, pero hay algunas oportunidades para la optimización de gas.
- Tornado Cash realiza una búsqueda lineal para los subárboles de Merkle precalculados con todas las hojas en cero, pero esto podría hacerse en menos operaciones con una búsqueda binaria codificada (hard-coded)
- Tornado Cash a menudo usa uint32 para las variables de la pila; uint256 sería una mejor opción para evitar el casting implícito que hace la EVM.
- Tornado Cash tiene algunas constantes que se modifican innecesariamente para ser públicas. Las constantes públicas no son necesarias a menos que un contrato inteligente vaya a leerlas, y aumentan el tamaño del contrato inteligente.
- Los operadores de prefijo (++i) son más eficientes en gas que los operadores de sufijo (i++), y Tornado Cash podría cambiar esta operación sin afectar la lógica.
nullifierHasheses un mapping público, pero también está envuelto con una función view públicaisSpent(). Esto es redundante.
Conclusión
Y ahí lo tienes; hemos examinado el código fuente completo de Tornado Cash y hemos desarrollado una buena comprensión de lo que hace cada variable y función. Tornado Cash agrupa una cantidad impresionante de complejidad en un código fuente relativamente pequeño. Aquí hemos analizado varias técnicas no triviales, que incluyen:
- Usar pruebas de conocimiento cero para demostrar el conocimiento de la preimagen de un hash sin revelar la preimagen
- Cómo usar un Árbol de Merkle incremental en la cadena (on-chain)
- Cómo usar una función hash personalizada codificada desde raw bytecode
- Cómo funcionan los esquemas de anuladores (nullifier schemes)
- Cómo retirar de forma anónima
- Cómo prevenir que las dapps de pruebas de conocimiento cero sufran frontrunning
RareSkills
Este material es parte de nuestro Curso de Zero Knowledge. Para el desarrollo general de contratos inteligentes, consulta nuestro Bootcamp de Solidity para desarrolladores profesionales de Solidity. Ofrecemos el programa de formación de contratos inteligentes más riguroso y actualizado disponible en cualquier lugar.
Notas Aclaratorias
[1] Cualquiera que esté familiarizado con los circuitos ZK sabe que no podemos crear bucles for de longitud arbitraria. El circuito debe construirse para acomodar matrices muy grandes cuando se crea. Sin embargo, todavía es preciso decir que iterar (“looping”) sobre tantos hashes es computacionalmente costoso, ya que es equivalente a crear un circuito inviablemente masivo.
Publicado originalmente el 27 de junio de 2023