Si tenemos un Pedersen vector commitment que contiene un compromiso para un vector como , podemos probar que conocemos la apertura enviando al verificador, quien comprobaría que . Esto requiere enviar elementos al verificador (asumiendo que tiene una longitud de ).
En el capítulo anterior, mostramos cómo hacer esto con zero knowledge. En este capítulo, mostraremos cómo probar el conocimiento de una apertura enviando menos de elementos, pero sin la propiedad de zero knowledge.
Motivación
La técnica que desarrollamos aquí será un componente fundamental para probar un cálculo válido de un producto interno (inner product) con una prueba de tamaño , donde es la longitud de los vectores.
En el capítulo anterior, mostramos cómo probar que ejecutamos el producto interno correctamente, pero sin revelar los vectores o el resultado. Sin embargo, la prueba tiene un tamaño de debido al paso en el que el probador envía y .
La subrutina de este artículo será importante para reducir el tamaño de la prueba. Este artículo no se centra en zero knowledge porque el algoritmo discutido anteriormente ya tiene esta propiedad. Es decir, y no eran secretos desde un principio, por lo que no hay necesidad de ofuscarlos.
Planteamiento del problema
Dado un vector base acordado , el probador entrega al verificador un Pedersen vector commitment , donde es un compromiso no cegador (non-blinding commitment) a , es decir , y desea probar que conoce la apertura de este compromiso enviando menos de términos, en lugar de enviar el vector completo .
Una prueba menor que
Reducir el tamaño de la prueba se basa en tres ideas clave:
Idea clave 1: El producto interno es la diagonal del producto externo (outer product)
La primera idea clave que aprovecharemos es que el producto interno es la diagonal del producto externo (outer product). En otras palabras, el producto externo “contiene” al producto interno en cierto sentido. El producto externo, en el contexto de vectores 1D, es una matriz 2D formada multiplicando cada elemento del primer vector 1D por todos los elementos del segundo vector. Por ejemplo:
Esto podría parecer un paso en la dirección equivocada porque el producto externo requiere pasos para calcularse. Sin embargo, la siguiente idea clave muestra que es posible calcular indirectamente el producto externo en un tiempo de .
Idea clave 2: La suma del producto externo es igual al producto de la suma de los vectores originales
Una segunda observación es que la suma de los términos del producto externo es igual al producto de la suma de los vectores. Es decir,
Para nuestro ejemplo de los vectores y esto sería
Gráficamente, esto puede visualizarse como el área del rectángulo con dimensiones teniendo la misma “área” que
En nuestro caso, el vector es realmente el vector base de puntos de la curva elíptica, por lo que estamos diciendo que
Nota que nuestro Pedersen commitment original
está incrustado en los términos recuadrados del producto externo:
Por lo tanto, al multiplicar entre sí las sumas de las entradas del vector, también calculamos la suma del producto externo.
Dado que el producto interno es la diagonal del producto externo, hemos calculado indirectamente el producto interno multiplicando entre sí las sumas de las entradas de los vectores. Para probar que conocemos el producto interno, necesitamos probar que también conocemos los términos del producto externo que no forman parte del producto interno.
Para vectores de longitud , llamemos a las partes del producto externo que no forman parte del producto interno el producto no diagonal (off-diagonal product).
A continuación, marcamos los términos que componen el producto no diagonal con y los términos que componen el producto interno con :
Ahora podemos plantear formalmente la identidad en la que confiaremos en adelante. Si , entonces:
La identidad también se cumple si uno de los vectores es un vector de puntos de una curva elíptica (incluso si sus logaritmos discretos son desconocidos).
Para los casos donde , probar el conocimiento de un producto interno significa que el probador necesita convencer al verificador de que conoce el “área” de la región sombreada en púrpura a continuación.
Transmitir esta información de manera sucinta cuando es más complicado, por lo que volveremos a esto más adelante.
En el caso de , el área son simplemente las no diagonales.
Idea clave 3: Si , entonces el producto interno es igual al producto externo
Un caso especial importante es cuando tenemos un vector de longitud . En ese caso, el probador simplemente envía al verificador (que tiene una longitud de ) y el verificador simplemente multiplica el único elemento de por el único elemento de .
Bosquejo del algoritmo
Ahora podemos crear un primer borrador de un algoritmo para el caso que pruebe que hemos calculado el producto interno de y , lo cual es equivalente a demostrar que conocemos el compromiso .
La interacción entre el probador y el verificador es la siguiente:
- El probador envía su compromiso al verificador.
- El probador suma todos los términos en y envía esto como al verificador (ten en cuenta que la suma de los componentes de un vector es un escalar, por lo tanto, sumar los elementos de da como resultado el escalar ). Además, el probador calcula los términos no diagonales de (es decir, , ) y envía y al verificador.
Gráficamente, y pueden verse de la siguiente manera:
- El verificador calcula indirectamente al calcular donde y verifica que
En forma expandida, la ecuación anterior es:
Nota que la verificación anterior es equivalente a la identidad vista previamente:
Error de seguridad: múltiples aperturas
Sin embargo, hay un problema de seguridad: el probador puede encontrar múltiples pruebas para el mismo compromiso. Por ejemplo, el probador podría elegir de forma aleatoria, y luego calcular
Para evitar esto, reutilizamos una idea similar de nuestra discusión sobre la multiplicación en zero knowledge: el probador debe incluir la aleatoriedad proporcionada por el verificador en su cálculo. También deben enviar y por adelantado, antes de recibir , de modo que y no puedan seleccionarse “ventajosamente”.
La razón por la que el probador debe enviar y de forma individual, en lugar de la suma , es que el probador es capaz de hackear el protocolo moviendo valor entre y sin restricciones. Es decir, dado que
el probador podría elegir algún punto de la curva elíptica y calcular unos fraudulentos y como
Necesitamos obligar al probador a mantener y separados.
Aquí está el algoritmo actualizado que corrige este error:
-
El probador y el verificador acuerdan un vector base donde los puntos son elegidos aleatoriamente y sus logaritmos discretos son desconocidos.
-
El probador calcula y envía al verificador :
-
El verificador responde con un escalar aleatorio .
-
El probador calcula y envía :
- El verificador, ahora en posesión de comprueba que:
Internamente esto es:
lo cual es idénticamente correcto si el probador calculó correctamente , y .
Nota que el verificador aplicó a , mientras que el probador aplicó a . Esto causa que los términos del producto interno original sean los coeficientes lineales del polinomio resultante.
El hecho de que y estén separados por , el cual es controlado por el verificador, previene que un probador malicioso lleve a cabo el ataque descrito anteriormente. Es decir, el probador no puede mover valor de a porque el valor que mueve debe ser escalado por , pero el probador debe enviar y antes de recibir .
Una interpretación alternativa del algoritmo: reduciendo a la mitad la dimensión de
El verificador solo está llevando a cabo una única multiplicación, por . A pesar de que comenzamos con vectores de longitud , el verificador solo realiza multiplicaciones de puntos.
La operación convirtió un vector de longitud en un vector de longitud . Por lo tanto, tanto el probador como el verificador están construyendo conjuntamente un nuevo vector de longitud dados los vectores del probador y la aleatoriedad del verificador.
Dado que ambos han comprimido el vector original a un vector de longitud , el verificador puede usar la identidad cuando . Aquí, y .
Seguridad del algoritmo
Resumen del algoritmo
Como un breve resumen del algoritmo,
- El probador envía al verificador.
- El verificador responde con .
- El probador calcula y envía .
- El verificador comprueba que:
Ahora veamos por qué el probador no puede hacer trampa.
El único “grado de libertad” que tiene el probador en el paso 3 es .
Para encontrar un que satisfaga
el probador necesita conocer los logaritmos discretos de y . Específicamente, tendría que resolver
donde
- y son los logaritmos discretos de y
- y son los logaritmos discretos de y respectivamente, y es el logaritmo discreto de .
- y son conocidos por el probador, ya que el probador produjo y en el paso 1.
Sin embargo, el probador no conoce los logaritmos discretos y , por lo que no puede calcular .
La variable tiene solo dos soluciones válidas
Solo hay dos valores válidos para que satisfacen . Nota que la ecuación forma un polinomio cuadrático con respecto a la variable , y forma un polinomio lineal. Según el Lema de Schwartz-Zippel, la ecuación tiene a lo sumo dos soluciones. Siempre y cuando el orden del campo sea , la probabilidad de que el probador encuentre un tal que resulte en un punto de intersección de es insignificante.
El enfoque del paper de Bulletproofs para inyectar aleatoriedad
En lugar de combinar y como , el probador los combina como y el verificador hace . Nota que las potencias de los dos vectores se aplican en orden opuesto. Cuando calculamos el producto externo, los términos del producto interno verán cancelarse sus :
Podría decirse que este enfoque es “más limpio”, por lo que lo usaremos en adelante.
Introduciendo
El cálculo ocurre tan frecuentemente en Bulletproofs que resulta útil darle un nombre, al cual llamaremos . El primer argumento es el vector que estamos plegando (folding), el cual debe ser de longitud par; si no lo es, lo rellenamos con un . Fold divide el vector de longitud en pares, y devuelve un vector de longitud de la siguiente manera:
Si hacemos nos referimos a:
Cuando , es simplemente y .
Descripción del algoritmo con
Ahora replanteamos el algoritmo usando el enfoque de inyección de aleatoriedad del paper de Bulletproofs:
- El probador envía al verificador su compromiso de como , junto con y calculados como
- El verificador responde con un escalar aleatorio .
- El probador calcula y envía
- El verificador calcula:
Asumiendo que el probador fue honesto, la comprobación final internamente se expande a:
Cómo manejar los casos cuando
Asumiendo que el arreglo tiene una longitud par (si no, podemos añadir un elemento cero para hacer que su longitud sea par), podemos particionar el arreglo en pares (pairwise-partition). A continuación se muestra un ejemplo de una partición en pares:
De manera similar, podemos particionar en pares.
Cada uno de los sub-pares puede ser tratado luego como instancias del cálculo del producto interno usando el caso de anterior:

Podríamos entonces probar que conocemos los cuatro compromisos de , es decir, , , y , y esto sería equivalente a probar que conocemos la apertura del compromiso original.
Sin embargo, esto crearía cuatro términos adicionales por los pares que estamos probando, es decir, no habría ganancia de eficiencia en términos del tamaño de los datos que transmite el probador.
La solución ingenua (naive) sería que el probador comprometiera y enviara:
Gráficamente, esto puede verse de la siguiente manera:
Como una optimización (¡clave!), sumamos todos los términos , y de cada uno de los pares para que se conviertan en los puntos únicos , , . En otras palabras, el probador solo envía:
La operación descrita se muestra en la siguiente animación:
Seguridad de sumar todos los compromisos y las no diagonales
Una preocupación inicial con tal optimización es que dado que el probador está sumando más términos entre sí, hay más oportunidades para ocultar un cálculo deshonesto.
Ahora mostraremos que una vez que el probador envía (y y ), solo puede crear una única prueba de que conoce la apertura de .
Observa que se calcula como y se calcula como . No tienen ningún punto de curva elíptica en común. Por lo tanto, el probador no puede “mover valor” de a porque no conoce los logaritmos discretos de ninguno de los puntos. Efectivamente, es un Pedersen vector commitment de hacia el vector base . La suposición de seguridad de un Pedersen vector commitment es que el probador solo puede producir una posible apertura de vector. “Mover valores” una vez que han enviado el compromiso significaría que el probador puede calcular un vector diferente a que produce el mismo compromiso. Pero eso contradice nuestra suposición de que un probador solo puede producir un único vector válido para un Pedersen commitment. Un argumento similar se puede hacer para .
es la suma de cuatro Pedersen commitments (los compromisos a los vectores , , , ). Sin embargo, el hecho de que varios Pedersen commitments se sumen es irrelevante desde una perspectiva de seguridad. No hay diferencia si los compromisos se calculan por separado y luego se suman, o si se calcula como un vector de . Considera que:
Por ejemplo, el probador podría “mover valor” de a .
La única preocupación restante es que el probador pudiera mover valor de en hacia en , ya que comparten un punto común en la curva elíptica. Sin embargo, esto es prevenido por el valor aleatorio del verificador, como se mostró anteriormente.
Por lo tanto, una vez que el probador envía calculado de la manera descrita en esta sección, solo puede crear una posible apertura, y en consecuencia, crear solo una posible prueba.
Probando que conocemos una apertura de mientras enviamos datos
- El probador envía al verificador. El probador también envía y .
- El verificador envía un valor aleatorio .
- El probador calcula y envía al verificador.
- El verificador comprueba que .
Dejamos como ejercicio para el lector desarrollar un ejemplo para comprobar que la verificación final es algebraicamente idéntica si el probador fue honesto. Sugerimos usar un ejemplo pequeño como .
Otra interpretación más de
es un compromiso al vector original con respecto al vector base . es un compromiso al vector compuesto por las no diagonales izquierdas de los productos externos en pares, y es un compromiso a los componentes de las no diagonales derechas de los productos externos en pares.
La suma es en sí misma un vector commitment del vector hacia la base , que tiene un tamaño de .
Mostramos la relación gráficamente a continuación:
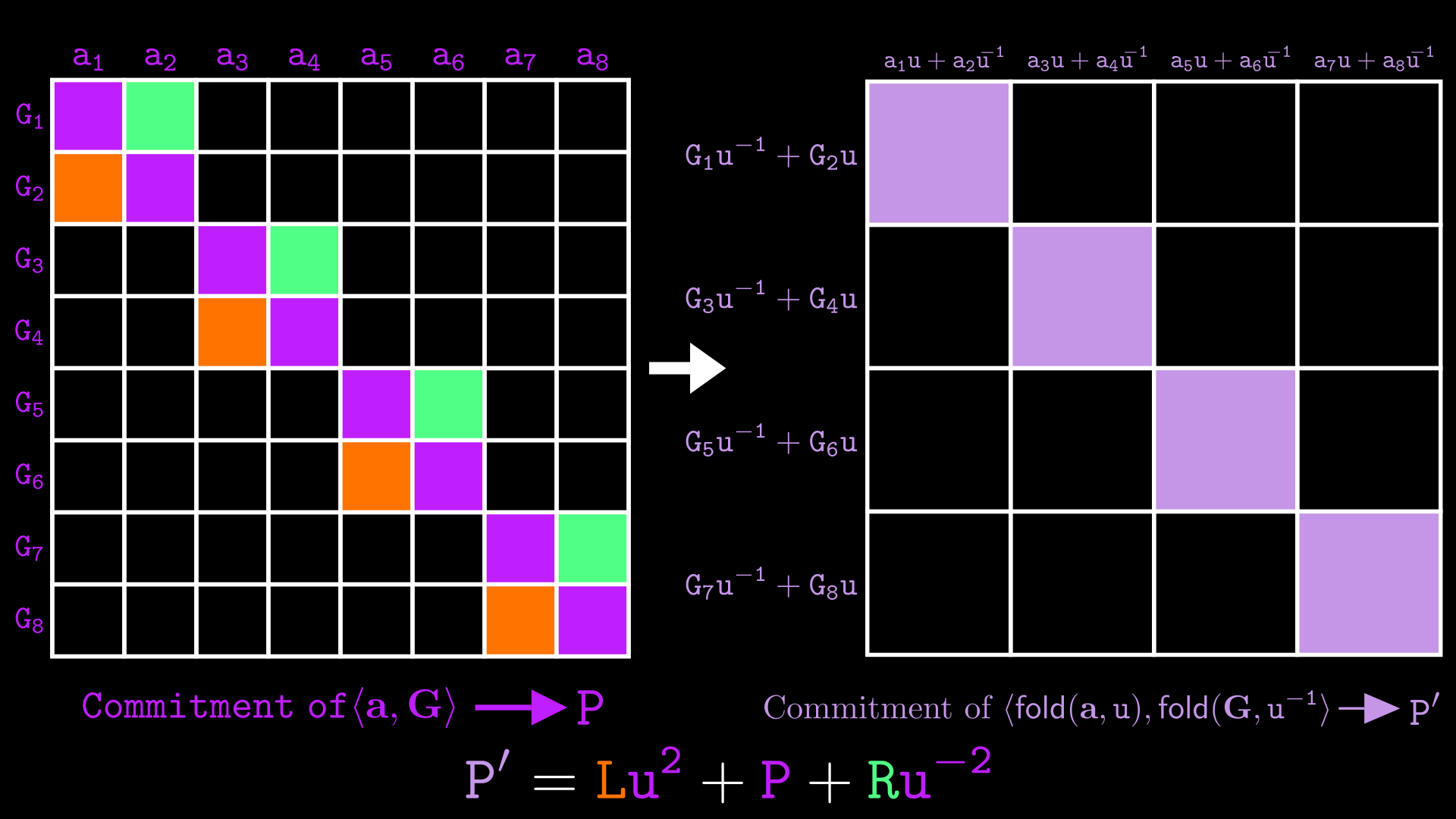
Para probar que conocemos la apertura de un compromiso de tamaño , simplemente podemos enviar el vector de tamaño , que en este caso es .
Usando esta interpretación, el algoritmo está haciendo lo siguiente:
- El probador envía , y .
- El verificador envía .
- Ahora el verificador tiene un compromiso con respecto al vector base .
- El probador prueba que conoce la apertura de enviando .
Limitaciones en la velocidad de verificación
Dado que el verificador necesita calcular , esto requerirá iterar sobre todo el vector , lo cual tomará un tiempo de . Aunque el tamaño de la prueba puede ser más pequeño que los vectores originales, verificar la prueba seguirá tomando un tiempo lineal.
Resumen
Hemos mostrado cómo el probador puede demostrar que conoce una apertura de un Pedersen vector commitment enviando solo elementos ( plegado).
En el próximo capítulo, mostraremos cómo aplicar recursivamente este algoritmo para que el probador solo envíe elementos.
Ejercicio: Implementa el algoritmo descrito en este capítulo. Utiliza el siguiente código como punto de partida:
from py_ecc.bn128 import G1, multiply, add, FQ, eq, Z1
from py_ecc.bn128 import curve_order as p
import numpy as np
from functools import reduce
import random
def random_element():
return random.randint(0, p)
def add_points(*points):
return reduce(add, points, Z1)
# if points = G1, G2, G3, G4 and scalars = a,b,c,d vector_commit returns
# aG1 + bG2 + cG3 + dG4
def vector_commit(points, scalars):
return reduce(add, [multiply(P, i) for P, i in zip(points, scalars)], Z1)
# these EC points have unknown discrete logs:
G_vec = [(FQ(6286155310766333871795042970372566906087502116590250812133967451320632869759), FQ(2167390362195738854837661032213065766665495464946848931705307210578191331138)),
(FQ(6981010364086016896956769942642952706715308592529989685498391604818592148727), FQ(8391728260743032188974275148610213338920590040698592463908691408719331517047)),
(FQ(15884001095869889564203381122824453959747209506336645297496580404216889561240), FQ(14397810633193722880623034635043699457129665948506123809325193598213289127838)),
(FQ(6756792584920245352684519836070422133746350830019496743562729072905353421352), FQ(3439606165356845334365677247963536173939840949797525638557303009070611741415))]
# return a folded vector of length n/2 for scalars
def fold(scalar_vec, u):
pass
# your code here
# return a folded vector of length n/2 for points
def fold_points(point_vec, u):
pass
# your code here
# return L, R as a tuple
def compute_secondary_diagonal(G_vec, a):
pass
# your code here
a = [9,45,23,42]
# prover commits
A = vector_commit(G_vec, a)
L, R = compute_secondary_diagonal(G_vec, a)
# verifier computes randomness
u = random_element()
# prover computes fold(a)
aprime = fold(a, u)
# verifier computes fold(G)
Gprime = fold_points(G_vec, pow(u, -1, p))
# verification check
assert eq(vector_commit(Gprime, aprime), add_points(multiply(L, pow(u, 2, p)), A, multiply(R, pow(u, -2, p)))), "invalid proof"
assert len(Gprime) == len(a) // 2 and len(aprime) == len(a) // 2, "proof must be size n/2"