यदि हमारे पास एक Pedersen vector commitment है जिसमें एक vector के लिए commitment शामिल है, जैसे , तो हम verifier को भेजकर यह साबित कर सकते हैं कि हम opening जानते हैं, जो यह जांचेगा कि है या नहीं। इसके लिए verifier को elements भेजने की आवश्यकता होती है (यह मानते हुए कि की लंबाई है)।
पिछले अध्याय में, हमने दिखाया था कि इसे zero knowledge के साथ कैसे किया जाए। इस अध्याय में, हम दिखाएंगे कि elements से कम भेजते हुए opening के ज्ञान को कैसे साबित किया जाए, लेकिन zero knowledge प्रॉपर्टी के बिना।
Motivation
हम यहाँ जो तकनीक विकसित करेंगे वह आकार के proof के साथ एक inner product की वैध गणना को साबित करने के लिए एक महत्वपूर्ण building block होगी, जहाँ vectors की लंबाई है।
पिछले अध्याय में, हमने दिखाया कि यह कैसे साबित किया जाए कि हमने inner product को सही ढंग से execute किया है, लेकिन vectors या परिणाम को प्रकट किए बिना। हालाँकि, उस step के कारण जहाँ prover और भेजता है, proof का आकार है।
इस लेख में subroutine proof के आकार को कम करने के लिए महत्वपूर्ण होगा। यह लेख zero knowledge से संबंधित नहीं है क्योंकि पहले चर्चा किए गए algorithm में zero knowledge प्रॉपर्टी होती है। यानी और शुरुआत में गुप्त नहीं थे, इसलिए उन्हें obfuscate (छिपाने) करने की कोई आवश्यकता नहीं है।
Problem statement
एक सहमत basis vector दिए जाने पर, prover verifier को एक Pedersen vector commitment देता है, जहाँ , के लिए एक non-blinding commitment है, यानी , और वह terms से कम भेजकर यह साबित करना चाहता है कि वह commitment की opening जानता है, यानी पूरा vector भेजने के बजाय।
से छोटा proof
Proof के आकार को छोटा करना तीन insights पर निर्भर करता है:
Insight 1: Inner product outer product का diagonal होता है
पहला insight जिसका हम लाभ उठाएंगे वह यह है कि inner product outer product का diagonal होता है। दूसरे शब्दों में, outer product एक तरह से inner product को “समाहित” करता है। 1D vectors के संदर्भ में, outer product एक 2D matrix है जो पहले 1D vector के प्रत्येक element को दूसरे vector के प्रत्येक अन्य element से गुणा करके बनाया जाता है। उदाहरण के लिए:
यह गलत दिशा में उठाया गया कदम लग सकता है क्योंकि outer product की गणना करने के लिए steps की आवश्यकता होती है। हालाँकि, निम्नलिखित insight से पता चलता है कि समय में outer product की अप्रत्यक्ष (indirectly) गणना करना संभव है।
Insight 2: Outer product का योग original vectors के योग के गुणनफल (product) के बराबर होता है
दूसरा observation यह है कि outer product के terms का योग vectors के योग के गुणनफल के बराबर होता है। यानी,
vectors और के हमारे उदाहरण के लिए यह होगा:
Graphically (ग्राफ़िक रूप से), इसे dimensions वाले आयत (rectangle) के क्षेत्रफल के रूप में देखा जा सकता है, जिसका “क्षेत्रफल” के समान होता है:
हमारे मामले में, vector वास्तव में elliptic curve points का basis vector है, इसलिए हम कह रहे हैं कि
ध्यान दें कि हमारा मूल Pedersen commitment
outer product के बॉक्स वाले terms में एम्बेडेड (embedded) है:
इसलिए, vector entries के योग को एक साथ गुणा करके, हम outer product के योग की भी गणना करते हैं।
चूँकि inner product outer product का diagonal होता है, इसलिए हमने vector entries के योग को एक साथ गुणा करके अप्रत्यक्ष रूप से inner product की गणना कर ली है। यह साबित करने के लिए कि हम inner product जानते हैं, हमें यह साबित करने की आवश्यकता है कि हम outer product के उन terms को भी जानते हैं जो inner product का हिस्सा नहीं हैं।
लंबाई वाले vectors के लिए, आइए outer product के उन हिस्सों को जो inner product का हिस्सा नहीं हैं, off-diagonal product कहें।
नीचे, हम उन terms को से चिह्नित करते हैं जो off-diagonal product बनाते हैं और उन terms को से चिह्नित करते हैं जो inner product बनाते हैं:
अब हम औपचारिक रूप से उस identity को बता सकते हैं जिस पर हम आगे चलकर निर्भर रहेंगे। यदि है तो:
यह identity तब भी मान्य होती है जब vectors में से कोई एक elliptic curve points का vector हो (भले ही उनके discrete logs अज्ञात हों)।
उन मामलों के लिए जहाँ है, एक inner product के ज्ञान को साबित करने का अर्थ है कि prover को verifier को यह विश्वास दिलाना होगा कि वे नीचे दिए गए बैंगनी रंग वाले (purple-shaded) क्षेत्र के “क्षेत्रफल” को जानते हैं।
होने पर इस जानकारी को संक्षेप (succinctly) में बताना अधिक कठिन है, इसलिए हम इस पर बाद में फिर से विचार करेंगे।
के मामले में, क्षेत्रफल केवल off-diagonals है।
Insight 3: यदि है तो inner product outer product के बराबर होता है
एक महत्वपूर्ण corner case वह है जहाँ हमारे पास लंबाई का एक vector है। उस मामले में, prover केवल verifier को (जिसकी लंबाई है) भेजता है और verifier केवल के single element को के single element से गुणा करता है।
Algorithm की रूपरेखा (Sketch)
अब हम मामले के लिए एक algorithm का पहला ड्राफ्ट बना सकते हैं जो यह साबित करता है कि हमने और के inner product की गणना की है, जो यह दिखाने के समतुल्य है कि हम commitment जानते हैं।
Prover और verifier के बीच का interaction इस प्रकार है:
- Prover verifier को अपना commitment भेजता है।
- Prover के सभी terms को जोड़ता है और उसे के रूप में verifier को भेजता है (ध्यान दें कि vector के components का योग एक scalar होता है, इसलिए के elements को जोड़ने पर scalar प्राप्त होता है)। इसके अलावा, prover के off-diagonal terms (यानी , ) की गणना करता है और और को verifier को भेजता है।
Graphically, और को इस प्रकार देखा जा सकता है:
- Verifier अप्रत्यक्ष रूप से की गणना करके की गणना करता है, जहाँ है, और जाँचता है कि
Expanded रूप में, उपरोक्त समीकरण है:
ध्यान दें कि उपरोक्त जाँच पहले दी गई identity के समतुल्य है:
Security bug: एकाधिक (multiple) openings
हालाँकि, यहाँ एक security issue है – prover एक ही commitment के लिए कई proofs खोज सकता है। उदाहरण के लिए, prover को randomly चुन सकता है, फिर गणना कर सकता है:
इसे रोकने के लिए, हम zero knowledge multiplication की अपनी चर्चा से एक समान विचार का फिर से उपयोग करते हैं – prover को अपनी गणना में verifier द्वारा प्रदान की गई randomness को शामिल करना होगा। उन्हें प्राप्त करने से पहले (in advance) और भी भेजना होगा ताकि और को “फायदेमंद” तरीके से नहीं चुना जा सके।
Prover को योग के बजाय और को अलग-अलग क्यों भेजना चाहिए, इसका कारण यह है कि prover बिना किसी प्रतिबंध के और के बीच value को move करके protocol को हैक करने में सक्षम है। यानी, चूँकि
prover कोई elliptic curve point चुन सकता है और एक fraudulent (धोखाधड़ी पूर्ण) और की गणना इस प्रकार कर सकता है:
हमें prover को और को अलग रखने के लिए मजबूर करने की आवश्यकता है।
यहाँ updated algorithm है जो इस बग को ठीक करता है:
-
Prover और verifier एक basis vector पर सहमत होते हैं जहाँ points को randomly चुना जाता है और उनके discrete logs अज्ञात होते हैं।
-
Prover की गणना करता है और verifier को भेजता है:
-
Verifier एक random scalar के साथ प्रतिक्रिया देता है।
-
Prover की गणना करता है और भेजता है:
- Verifier, जिसके पास अब है, जाँचता है कि:
आंतरिक रूप से (Under the hood) यह है:
जो कि बिल्कुल सही (identically correct) है यदि prover ने , , और की सही गणना की है।
ध्यान दें कि verifier ने को पर apply किया जबकि prover ने को पर apply किया। इसके कारण original inner product के terms परिणामी (resulting) polynomial के linear coefficients बन जाते हैं।
यह तथ्य कि और , द्वारा अलग किए गए हैं, जिसे verifier नियंत्रित करता है, एक malicious prover को पहले बताए गए हमले को करने से रोकता है। यानी, prover से में value shift नहीं कर सकता है क्योंकि जो value वे shift करते हैं उसे द्वारा scale किया जाना चाहिए, लेकिन prover को प्राप्त करने से पहले और भेजना होगा।
Algorithm की एक वैकल्पिक व्याख्या (alternative interpretation): के dimension को आधा करना
Verifier केवल एक single गुणा कर रहा है, गुना । भले ही हमने लंबाई के vectors के साथ शुरुआत की, verifier केवल point multiplications करता है।
Operation ने लंबाई के vector को लंबाई के vector में बदल दिया। इसलिए, prover के vectors और verifier की randomness दिए जाने पर, prover और verifier दोनों संयुक्त रूप से लंबाई का एक नया vector बना रहे हैं।
चूँकि दोनों ने original vector को लंबाई के vector में compress कर दिया है, verifier identity का उपयोग कर सकता है जब हो। यहाँ, और है।
Algorithm की सुरक्षा (Security)
Algorithm सारांश
Algorithm के एक त्वरित सारांश (quick summary) के रूप में:
- Prover verifier को भेजता है।
- Verifier के साथ प्रतिक्रिया देता है।
- Prover की गणना करता है और भेजता है।
- Verifier जाँचता है कि:
अब आइए देखें कि prover धोखा (cheat) क्यों नहीं दे सकता।
Step 3 पर prover के पास एकमात्र “degree of freedom” है।
एक ऐसा लाने के लिए जो निम्न को संतुष्ट करे:
prover को और के discrete logs जानने की आवश्यकता है। विशेष रूप से, उन्हें हल करना होगा:
जहाँ
- और , और के discrete logs हैं
- और क्रमशः और के discrete logs हैं, और , का discrete log है।
- और prover को ज्ञात हैं, क्योंकि prover ने step 1 में और को produce किया था।
हालाँकि, prover को discrete logs और नहीं पता हैं, इसलिए वे की गणना नहीं कर सकते।
Variable के केवल दो वैध (valid) समाधान हैं
के लिए केवल दो मान वैध हैं जो को संतुष्ट करते हैं। ध्यान दें कि समीकरण variable के संबंध में एक quadratic polynomial बनाता है और एक linear polynomial बनाता है। Schwartz-Zippel Lemma के अनुसार, समीकरण के अधिक से अधिक दो समाधान होते हैं। जब तक field का क्रम (order) है, तब तक prover द्वारा ऐसा खोजने की संभावना (probability) नगण्य (negligible) है जिसके परिणामस्वरूप का एक intersection point प्राप्त हो।
Randomness इंजेक्ट करने के लिए Bulletproofs पेपर का दृष्टिकोण
और को के रूप में एक साथ मिलाने के बजाय, prover उन्हें के रूप में मिलाता है और verifier करता है। ध्यान दें कि दो vectors की powers विपरीत क्रम में apply की जाती हैं। जब हम outer product की गणना करते हैं, तो inner product terms में cancel हो जाएगा:
तार्किक रूप से (Arguably), यह दृष्टिकोण अधिक “cleaner” है इसलिए हम आगे इसी का उपयोग करेंगे।
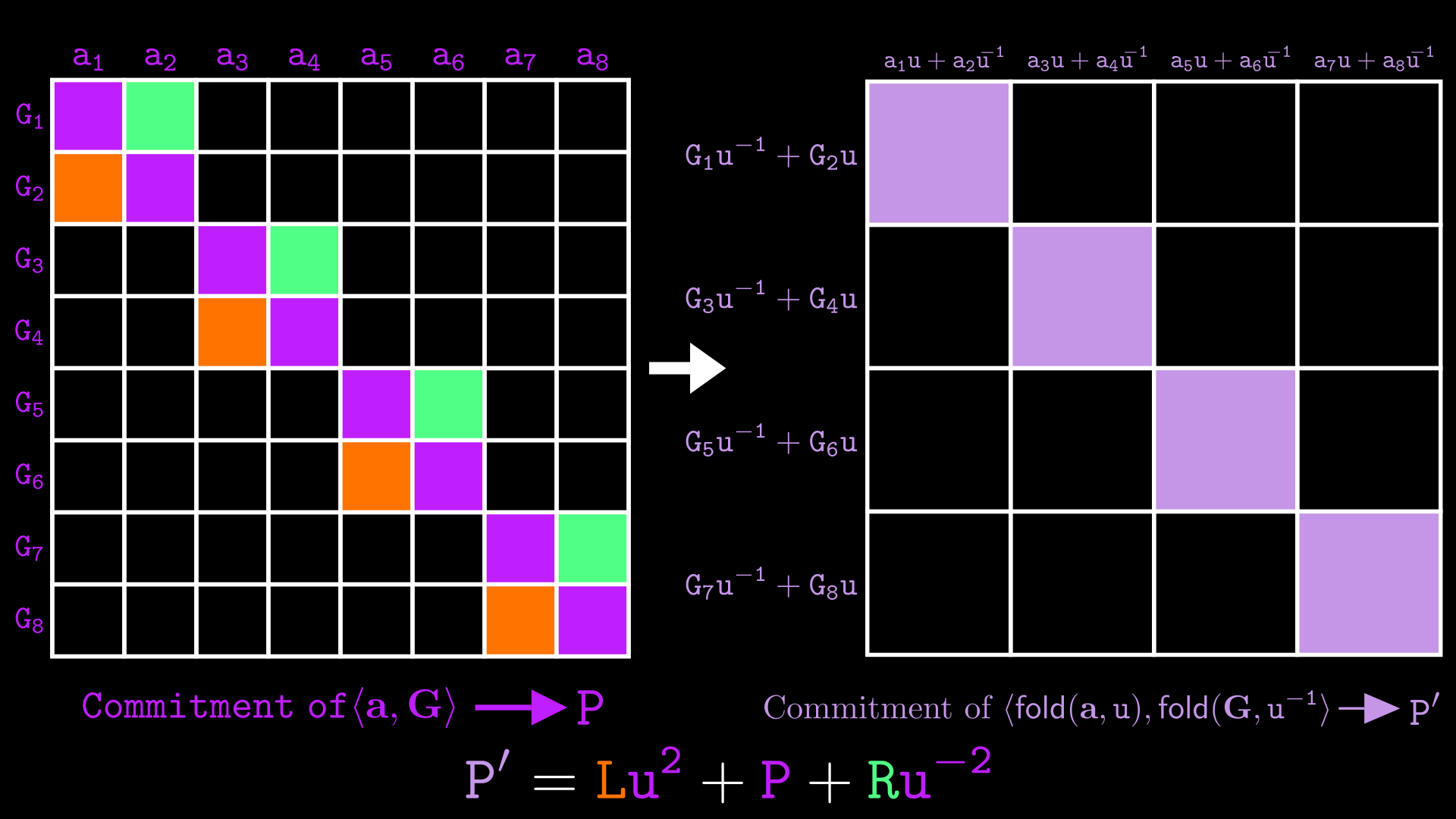
का परिचय
की गणना Bulletproofs में इतनी बार होती है कि इसे एक नाम देना सुविधाजनक है, जिसे हम कहते हैं। पहला argument वह vector है जिसे हम fold कर रहे हैं (जिसकी लंबाई सम (even) होनी चाहिए, यदि नहीं तो हम इसे के साथ pad करते हैं)। Fold लंबाई के vector को जोड़े (pairs) में विभाजित करता है, और इस प्रकार लंबाई का एक vector देता है:
यदि हम करते हैं तो हमारा मतलब है:
जब होता है, तो केवल होता है और होता है।
के साथ Algorithm का विवरण
अब हम randomness के लिए Bulletproofs पेपर के दृष्टिकोण का उपयोग करके algorithm को फिर से बताते हैं:
- Prover के लिए अपना commitment के रूप में verifier को भेजता है, साथ ही और भी भेजता है जिसकी गणना इस प्रकार की गई है:
- Verifier एक random scalar के साथ प्रतिक्रिया देता है।
- Prover की गणना करता है और भेजता है:
- Verifier गणना करता है:
यह मानते हुए कि prover ईमानदार था, आंतरिक रूप से (under the hood) अंतिम जाँच इस प्रकार विस्तारित (expand) होती है:
होने पर मामलों को कैसे handle करें
यह मानते हुए कि array की लंबाई सम (even) है (यदि नहीं, तो हम इसे सम लंबाई बनाने के लिए एक zero element जोड़ सकते हैं), हम array को pairwise-partition कर सकते हैं। नीचे एक pairwise-partition का उदाहरण दिया गया है:
इसी तरह, हम को pair-wise partition कर सकते हैं।
फिर प्रत्येक sub-pair को पहले बताए गए मामले का उपयोग करके inner product की गणना के उदाहरण (instances) के रूप में माना जा सकता है:

फिर हम यह साबित कर सकते हैं कि हम चार commitments , , , और को जानते हैं और यह यह साबित करने के समतुल्य होगा कि हम original commitment की opening को जानते हैं।
हालाँकि, यह हमारे द्वारा साबित किए जा रहे pairs के लिए चार अतिरिक्त terms बनाएगा – यानी, prover द्वारा ट्रांसमिट किए जाने वाले डेटा के आकार के संदर्भ में कोई efficiency gain (दक्षता लाभ) नहीं होगा।
Naive समाधान यह होगा कि prover commit करे और भेजे:
Graphically, इसे इस प्रकार देखा जा सकता है:
एक (मुख्य!) optimization के रूप में, हम प्रत्येक जोड़े (pair) से सभी , और terms को जोड़कर single points , , बना देते हैं। दूसरे शब्दों में, prover केवल भेजता है:
वर्णित operation नीचे दिए गए एनीमेशन में दिखाया गया है:
सभी commitments और off-diagonals को एक साथ जोड़ने की सुरक्षा
इस तरह के optimization के साथ एक शुरुआती चिंता यह है कि चूँकि prover अधिक terms को एक साथ जोड़ रहा है, इसलिए एक बेईमान (dishonest) गणना को छिपाने का अधिक अवसर होता है।
अब हम दिखाते हैं कि एक बार जब prover (और और ) भेज देता है, तो वे केवल एक unique proof ही बना सकते हैं कि वे की opening को जानते हैं।
ध्यान दें कि की गणना के रूप में की जाती है और की गणना के रूप में की जाती है। उनमें कोई सामान्य (common) elliptic curve points नहीं हैं। इस प्रकार, prover से में “value shift” नहीं कर सकता क्योंकि वे किसी भी points के discrete logs नहीं जानते हैं। प्रभावी रूप से, basis vector पर का एक Pedersen vector commitment है। Pedersen vector commitment की security assumption यह है कि prover केवल एक ही संभव vector opening produce कर सकता है। Commitment भेजने के बाद “Shifting values around (मानों को इधर-उधर करने)” का अर्थ होगा कि prover के अलावा किसी अन्य vector की गणना कर सकता है जो समान commitment produce करता है। लेकिन यह हमारी इस धारणा (assumption) का खंडन करता है कि एक prover Pedersen commitment के लिए केवल एक single वैध vector ही produce कर सकता है। के लिए भी ऐसा ही तर्क दिया जा सकता है।
चार Pedersen commitments (vectors , , , के commitments) का योग है। हालाँकि, यह तथ्य कि कई Pedersen commitments एक साथ जोड़े गए हैं, सुरक्षा के दृष्टिकोण से महत्वहीन (immaterial) है। इससे कोई फर्क नहीं पड़ता कि commitments की गणना अलग से की जाती है और फिर जोड़ी जाती है, या की गणना के vector के रूप में की जाती है। इस पर विचार करें कि:
उदाहरण के लिए, prover से में “value shift” कर सकता है।
एकमात्र शेष चिंता यह है कि prover में से में तक value shift कर सकता है क्योंकि वे एक common elliptic curve point share करते हैं। हालाँकि, जैसा कि पहले दिखाया गया है, verifier से प्राप्त random द्वारा इसे रोका जाता है।
इसलिए, एक बार जब prover इस अनुभाग में वर्णित तरीके से गणना किए गए को भेज देता है, तो वे केवल एक ही संभव opening बना सकते हैं, और इस प्रकार केवल एक ही संभव proof बना सकते हैं।
डेटा भेजते हुए यह साबित करना कि हम की opening जानते हैं
- Prover verifier को भेजता है। Prover और भी भेजता है।
- Verifier एक random भेजता है।
- Prover की गणना करता है और verifier को भेजता है।
- Verifier जाँचता है कि है या नहीं।
हम पाठक के लिए यह अभ्यास (exercise) के रूप में छोड़ते हैं कि वह एक उदाहरण पर काम करके जाँचे कि क्या अंतिम सत्यापन जाँच (verification check) बीजगणितीय रूप से (algebraically) समान है यदि prover ईमानदार था। हम जैसे छोटे उदाहरण का उपयोग करने का सुझाव देते हैं।
की एक और व्याख्या (interpretation)
basis vector के संबंध में original vector के लिए एक commitment है। pairwise outer products के left off-diagonals से बने vector के लिए एक commitment है और pairwise outer products के right off-diagonals के components के लिए एक commitment है।
योग स्वयं basis पर vector का एक vector commitment है, जिसका आकार है।
हम नीचे graphically इस संबंध को दिखाते हैं:
आकार के commitment की opening को जानने का प्रमाण देने के लिए, हम बस आकार का vector भेज सकते हैं, जो इस मामले में है।
इस व्याख्या का उपयोग करते हुए, algorithm निम्नलिखित कार्य कर रहा है:
- Prover , , और भेजता है।
- Verifier भेजता है।
- अब verifier के पास basis vector के संबंध में एक commitment है।
- Prover भेजकर यह साबित करता है कि वे की opening जानते हैं।
Verification गति (speed) की सीमाएँ
चूँकि verifier को की गणना करने की आवश्यकता होती है, इसलिए पूरे vector पर iterate करने की आवश्यकता होगी, जिसमें समय लगेगा। हालाँकि proof का आकार मूल (original) vectors से छोटा हो सकता है, लेकिन proof को verify करने में अभी भी linear time लगेगा।
सारांश (Summary)
हमने दिखाया है कि कैसे prover केवल elements ( folded) भेजते हुए यह दिखा सकता है कि वे एक Pedersen vector commitment की opening जानते हैं।
अगले अध्याय में, हम दिखाएंगे कि इस algorithm को recursively कैसे apply किया जाए ताकि prover केवल elements भेजे।
Exercise: इस अध्याय में वर्णित algorithm को implement करें। निम्नलिखित कोड को शुरुआती बिंदु (starting point) के रूप में उपयोग करें:
from py_ecc.bn128 import G1, multiply, add, FQ, eq, Z1
from py_ecc.bn128 import curve_order as p
import numpy as np
from functools import reduce
import random
def random_element():
return random.randint(0, p)
def add_points(*points):
return reduce(add, points, Z1)
# if points = G1, G2, G3, G4 and scalars = a,b,c,d vector_commit returns
# aG1 + bG2 + cG3 + dG4
def vector_commit(points, scalars):
return reduce(add, [multiply(P, i) for P, i in zip(points, scalars)], Z1)
# these EC points have unknown discrete logs:
G_vec = [(FQ(6286155310766333871795042970372566906087502116590250812133967451320632869759), FQ(2167390362195738854837661032213065766665495464946848931705307210578191331138)),
(FQ(6981010364086016896956769942642952706715308592529989685498391604818592148727), FQ(8391728260743032188974275148610213338920590040698592463908691408719331517047)),
(FQ(15884001095869889564203381122824453959747209506336645297496580404216889561240), FQ(14397810633193722880623034635043699457129665948506123809325193598213289127838)),
(FQ(6756792584920245352684519836070422133746350830019496743562729072905353421352), FQ(3439606165356845334365677247963536173939840949797525638557303009070611741415))]
# return a folded vector of length n/2 for scalars
def fold(scalar_vec, u):
pass
# your code here
# return a folded vector of length n/2 for points
def fold_points(point_vec, u):
pass
# your code here
# return L, R as a tuple
def compute_secondary_diagonal(G_vec, a):
pass
# your code here
a = [9,45,23,42]
# prover commits
A = vector_commit(G_vec, a)
L, R = compute_secondary_diagonal(G_vec, a)
# verifier computes randomness
u = random_element()
# prover computes fold(a)
aprime = fold(a, u)
# verifier computes fold(G)
Gprime = fold_points(G_vec, pow(u, -1, p))
# verification check
assert eq(vector_commit(Gprime, aprime), add_points(multiply(L, pow(u, 2, p)), A, multiply(R, pow(u, -2, p)))), "invalid proof"
assert len(Gprime) == len(a) // 2 and len(aprime) == len(a) // 2, "proof must be size n/2"