Solidity में Dynamic-sized types (जिन्हें कभी-कभी complex types भी कहा जाता है) वेरिएबल साइज़ वाले डेटा प्रकार होते हैं। इनमें mappings, nested mappings, arrays, nested arrays, strings, bytes, और वे structs शामिल हैं जिनमें इनमें से कोई भी type होता है। यह आर्टिकल दिखाता है कि उन्हें कैसे एनकोड (encode) किया जाता है और storage में कैसे रखा जाता है।
Mappings
Mappings का उपयोग डेटा को key-value पेयर (जोड़े) के रूप में स्टोर करने के लिए किया जाता है।
नीचे दिए गए रंगीन key values को आने वाले कोड ब्लॉक में संदर्भित (refer) किया जाएगा:
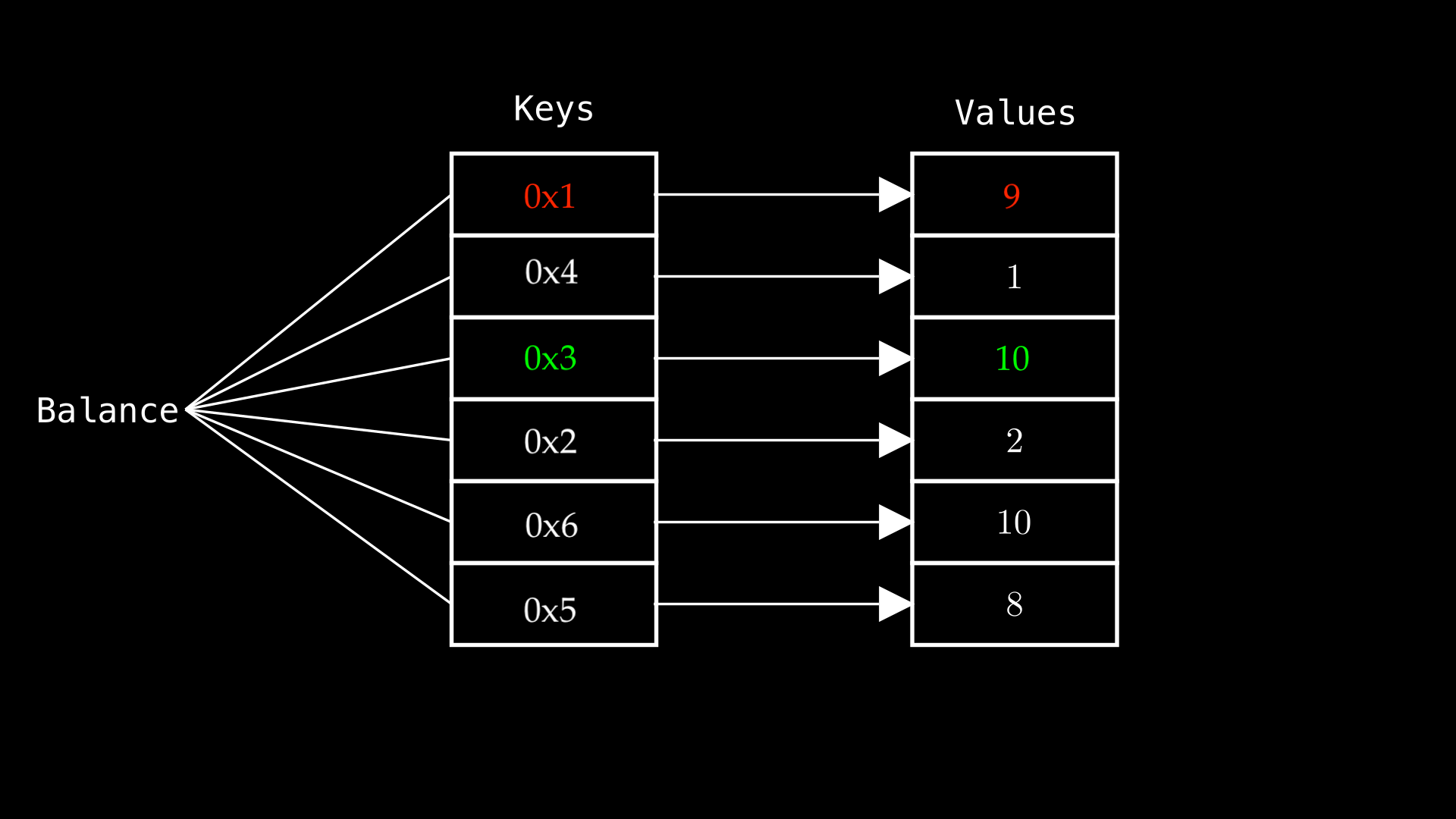
इस उदाहरण पर विचार करें जो एक Ethereum एड्रेस को किसी वैल्यू (value) के साथ जोड़ने (associate) के लिए mappings का उपयोग करता है। लाल और हरे रंग की key values, जैसा कि ऊपर आरेख (diagram) में दिखाया गया है, नीचे दिए गए कोड में सेट की गई हैं:
// SPDX-License-Identifier: MIT
pragma solidity =0.8.26;
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9; // RED
balance[address(0x03)] = 10; // GREEN
}
}
फ़ंक्शन setValues एड्रेस 0x01 और 0x03 को क्रमशः 9 और 10 पर मैप करता है, उन्हें मैपिंग वेरिएबल balance में स्टोर करता है। Solidity का उपयोग करके address(0x01) को असाइन की गई वैल्यू प्राप्त करना सीधा (straightforward) है। लेकिन यह किस storage slot का उपयोग कर रहा है, और हम इसे असेंबली (assembly) के साथ कैसे एक्सेस कर सकते हैं?
Mappings के लिए Storage Slot
वैल्यू के storage slot की गणना (compute) करने के लिए, हम निम्नलिखित कदम उठाते हैं:
- वैल्यू से जुड़ी key और मैपिंग वेरिएबल के storage slot (base slot) को आपस में जोड़ें (concatenate करें)।
- जोड़े गए परिणाम (concatenated result) को हैश (hash) करें।
उपरोक्त चरणों के लिए फ़ॉर्मूला
जहाँ का अर्थ कॉनकैटेनेट (concatenate) करना है
निम्नलिखित एनीमेशन दिखाता है कि ऊपर दिए गए फ़ॉर्मूले में डेटा कैसे लेआउट किया गया है:
अंदरूनी तौर पर (Under the hood), key और base slot दोनों 256 बिट (32 बाइट्स) वैल्यू के रूप में स्टोर होते हैं। जब उन्हें एक साथ जोड़ा (concatenate) जाता है, तो वे 64 बाइट्स की वैल्यू बन जाते हैं।
नीचे एक एनीमेशन दिया गया है जो दिखाता है कि इन वैल्यूज़ (key और base slot) को कैसे कॉनकैटेनेट किया जाता है। उपयोग किए गए वैल्यूज़ हैं:
- address key =
0x504DbB5Dc821445b142312b74693d778a1B60b2f - uint256 baseSlot =
6
ध्यान दें कि कैसे key और base slot वैल्यूज़ को एक साथ जोड़ने से पहले 32-बाइट वैल्यूज़ बनाने के लिए ज़ीरो (zeros) के साथ पैड (pad) किया गया था। कॉनकैटेनेशन का परिणाम (64 बाइट्स ऐरे) ही वह होता है जिसे storage slot निर्धारित करने के लिए हैश किया जाता है।
Mapping Storage Slot की गणना करें
अब जब हमें इस बात का आइडिया हो गया है कि मैपिंग के लिए storage slot प्राप्त करने हेतु key और base slot की गणना कैसे की जाती है, तो हम यह देखने के लिए तैयार हैं कि इसे Solidity में मैन्युअल रूप से कैसे किया जाता है।
याद रखें, मैपिंग के लिए स्लॉट की गणना करने के लिए हमें दो वैल्यूज़ (key और base slot) की आवश्यकता होती है। इसे पूरा करने का कोड getStorageSlot() फ़ंक्शन में है:
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9; // RED
balance[address(0x03)] = 10; // GREEN
}
//*** NEWLY ADDED FUNCTION ***//
function getStorageSlot(address _key) public pure returns (bytes32 slot) {
uint256 balanceMappingSlot;
assembly {
// `.slot` returns the state variable (balance) location within the storage slots.
// In our case, balance.slot = 0
balanceMappingSlot := balance.slot
}
slot = keccak256(abi.encode(_key, balanceMappingSlot));
}
}
getStorageSlot फ़ंक्शन आर्ग्यूमेंट के रूप में _key लेता है और balance वेरिएबल के लिए base slot (balanceMappingSlot) प्राप्त करने के लिए एक assembly ब्लॉक का उपयोग करता है। फिर यह प्रत्येक वैल्यू को 32 बाइट्स तक पैड करने और उन्हें जोड़ने के लिए abi.encode का उपयोग करता है, उसके बाद storage slot उत्पन्न करने के लिए keccak256 का उपयोग करके जोड़े गए (concatenated) वैल्यू को हैश करता है।
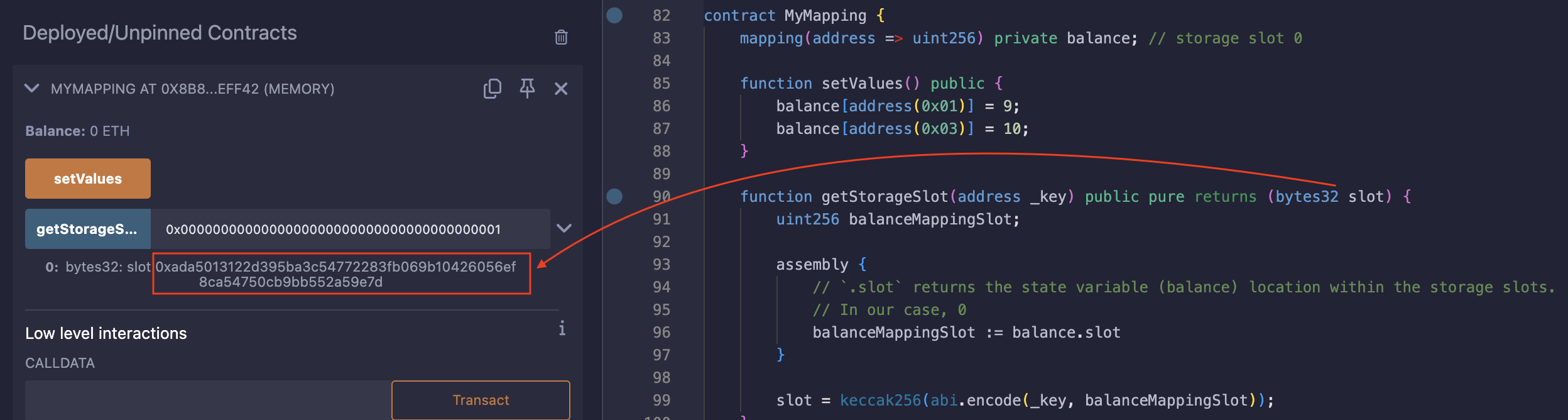
इसका परीक्षण (test) करने के लिए, आइए फ़ंक्शन को address(0x01) के आर्ग्यूमेंट के साथ कॉल करें, क्योंकि हमने पहले ही setValues फ़ंक्शन में इस _key से जुड़े storage slot को एक वैल्यू असाइन कर दी है।
कॉल के बाद वापस आया स्लॉट (returned slot): 0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d
इसके बाद, हम एक getValue() फ़ंक्शन बनाते हैं जो हमारे द्वारा कैलकुलेट किए गए storage slot को लोड करेगा। यह फ़ंक्शन यह साबित करने के लिए है कि getStorageSlot() द्वारा कैलकुलेट किया गया स्लॉट वास्तव में वही सही storage slot है जो उस वैल्यू को रखता है।
function getValue(address _key) public view returns (uint256 value) {
// CALL HELPER FUNCTION TO GET SLOT
bytes32 slot = getStorageSlot(_key);
assembly {
// Loads the value stored in the slot
value := sload(slot)
}
}
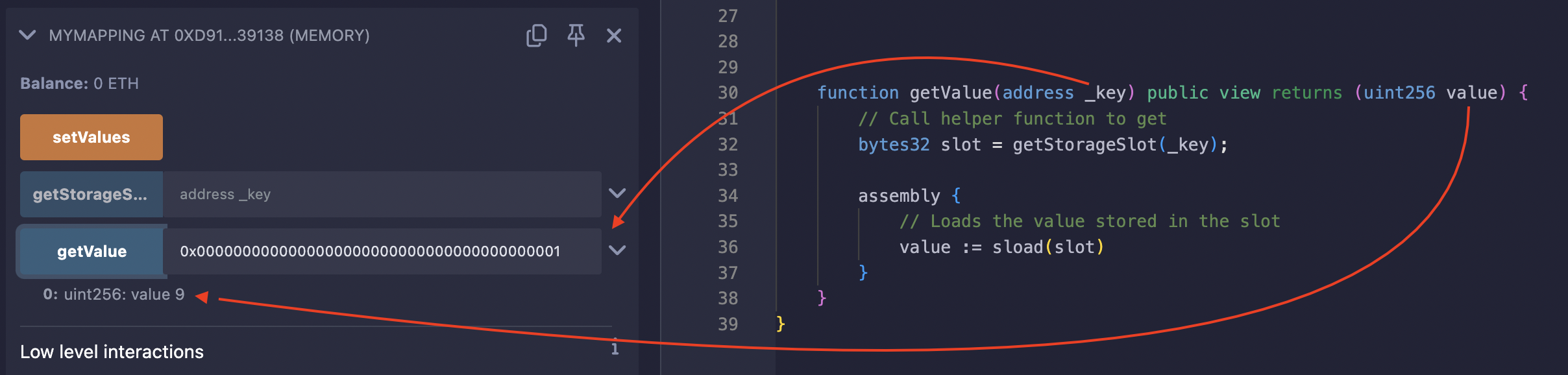
आर्ग्यूमेंट के रूप में address(1) के साथ getValue फ़ंक्शन को कॉल करने पर 9 वापस आया, जो address(1) की (key) को असाइन की गई सही वैल्यू है:
यहाँ आपके लिए Remix पर परीक्षण करने का पूरा कोड है।
// SPDX-License-Identifier: MIT
pragma solidity =0.8.26;
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9;
balance[address(0x03)] = 10;
}
function getStorageSlot(address _key) public pure returns (bytes32 slot) {
uint256 balanceMappingSlot;
assembly {
// `.slot` returns the state variable (balance) location within the storage slots.
// In our case, 0
balanceMappingSlot := balance.slot
}
slot = keccak256(abi.encode(_key, balanceMappingSlot));
}
function getValue(address _key) public view returns (uint256 value) {
// Call helper function to get
bytes32 slot = getStorageSlot(_key);
assembly {
// Loads the value stored in the slot
value := sload(slot)
}
}
}
Nested Mappings
एक nested mapping दूसरी मैपिंग के अंदर एक मैपिंग होती है। इसके लिए एक सामान्य उपयोग का मामला (use case) किसी विशिष्ट एड्रेस के लिए विभिन्न टोकन के बैलेंस को स्टोर करना है, जैसा कि नीचे दिए गए आरेख (diagram) में दिखाया गया है।
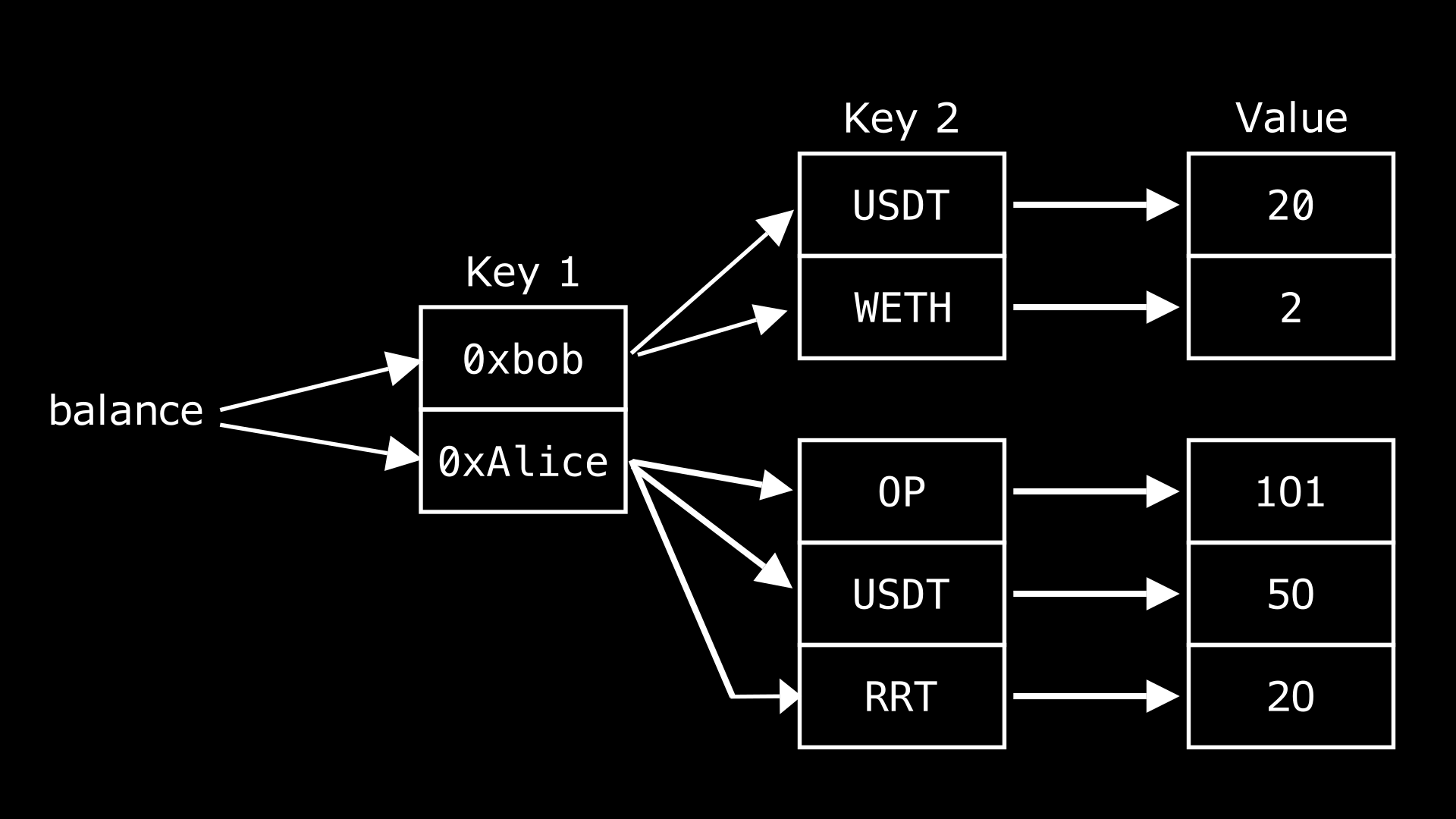
यह दिखाता है कि balance वेरिएबल दो अलग-अलग एड्रेस, 0xbob और 0xAlice को रखता है, इनमें से प्रत्येक एड्रेस कई टोकनों से जुड़ा है, जो आगे चलकर अलग-अलग बैलेंस पर मैप होते हैं, इसलिए, nested mappings।
Nested Mappings के लिए Storage Slot
Nested mappings के लिए storage slots की गणना सिंगल मैपिंग के समान ही होती है, अंतर केवल इतना है कि मैपिंग का “लेवल” हैश संचालन (hash operations) की संख्या से मेल खाता है। नीचे एक एनीमेशन और कोड उदाहरण दिया गया है जो दो हैश संचालन के साथ दो-स्तरीय मैपिंग (two-level mappings) को प्रदर्शित करता है:
अब असेंबली (assembly) का उपयोग करके स्टोरेज से nested array की वैल्यू प्राप्त करने का कोड उदाहरण देखते हैं
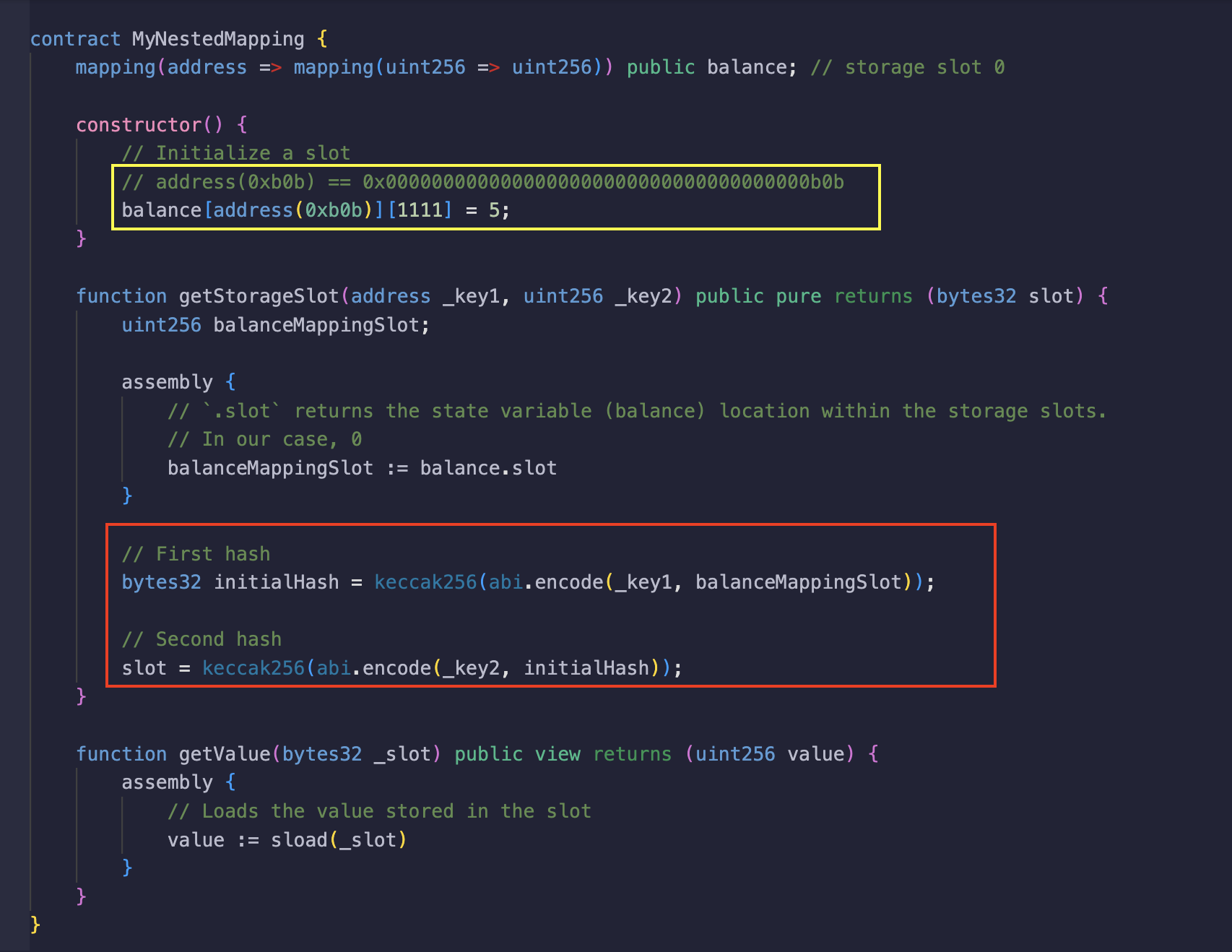
नीचे दिए गए स्क्रीनशॉट में, पीले बॉक्स में हाइलाइट किए गए अनुसार address(0xb0b) (owner) और 1111 (tokenID) keys के साथ balance मैपिंग को 5 वैल्यू असाइन की गई है। कॉन्ट्रैक्ट में दो फ़ंक्शन हैं;
getStorageSlotफ़ंक्शन जो दो आर्ग्यूमेंट लेता है जो वांछित स्लॉट (desired slot) प्राप्त करने के लिए आवश्यक keys हैं। जैसा कि लाल बॉक्स में देखा जा सकता है, फ़ंक्शन में दो हैश ऑपरेशन भी हो रहे हैं:- पहला
_key1(owner) औरbalanceमैपिंग स्लॉट का हैश है, जिसे बाद मेंinitialHashवेरिएबल में स्टोर किया जाता है। - दूसरा
_key2(tokenID) औरinitialHashका हैश है, ताकिbalance[_key1][_key2]का स्लॉट प्राप्त किया जा सके। यदि यह 3-स्तरीय (3-level) मैपिंग होती, तो वांछित storage slot प्राप्त करने के लिए तीसरी की (_key3) को दूसरे हैश ऑपरेशन से प्राप्त वैल्यू के साथ हैश किया जाता और इसी तरह आगे भी।
- पहला
getValueफ़ंक्शन जो आर्ग्यूमेंट के रूप में एक स्लॉट लेता है और उसमें रखी गई वैल्यू वापस करता है, जो पिछले उदाहरण के समान ही काम करता है।
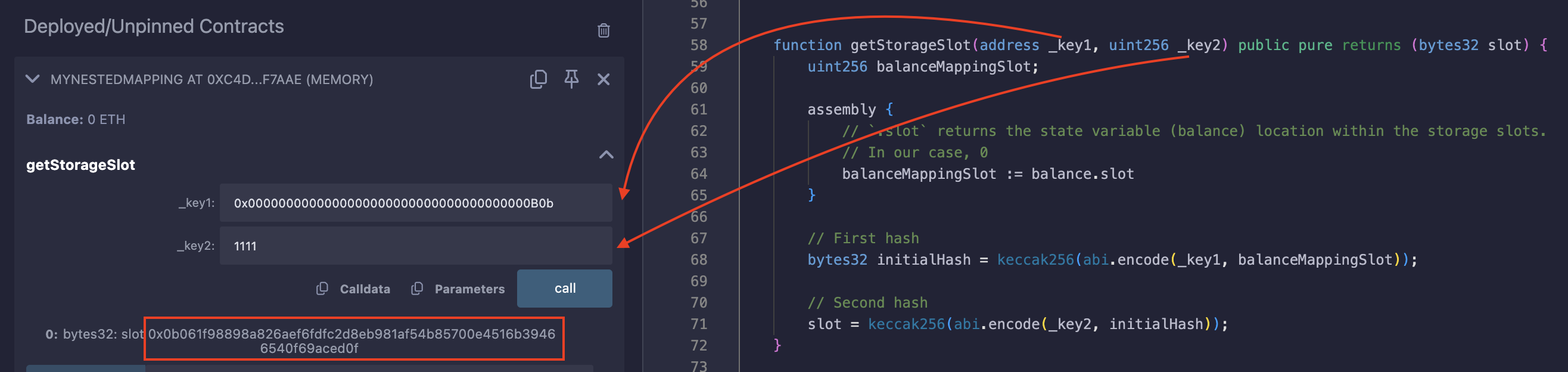
निम्नलिखित आर्ग्यूमेंट्स, address(0xb0b) और 1111 के साथ getStorageSlot फ़ंक्शन को कॉल करने पर निम्नलिखित स्लॉट वापस आता है:
0x0b061f98898a826aef6fdfc2d8eb981af54b85700e4516b39466540f69aced0f
यह दिखाने के लिए कि कैलकुलेट किए गए स्लॉट में 5 वैल्यू मौजूद है, हम getValue फ़ंक्शन को कॉल करेंगे और स्लॉट को आर्ग्यूमेंट के रूप में पास करेंगे। यह फ़ंक्शन स्लॉट को लोड करने के लिए sload ऑपकोड (opcode) का उपयोग करता है और फिर उसकी वैल्यू लौटाता है:

और हाँ! हमें वही वैल्यू 5 मिली जो हमने कंस्ट्रक्टर (constructor) में डाली थी।
Array
यह Solidity में एक डायनामिक प्रकार (dynamic type) है जिसका उपयोग समान प्रकार के एलिमेंट्स (elements) के एक इंडेक्स किए गए संग्रह (indexed collection) को स्टोर करने के लिए किया जाता है, चाहे वह प्रिमिटिव हो या डायनामिक। Solidity दो प्रकार के array का समर्थन करता है: fixed-size और dynamic, जिनके storage allocation के तरीके अलग-अलग होते हैं।
Fixed-Size Arrays
इस प्रकार के ऐरे (array) का आकार पूर्व-निर्धारित (predetermined) होता है जिसे ऐरे के डिक्लेयर (declare) होने के बाद बदला नहीं जा सकता।
Fixed-size Array के लिए Slot Allocation
यदि ऐरे के एलिमेंट का प्रकार एक पूरे storage slot की क्षमता (256 बिट्स, 32 बाइट्स, या 1 वर्ड) घेरता है, तो Solidity कंपाइलर इन एलिमेंट्स को व्यक्तिगत स्टोरेज वेरिएबल के रूप में मानता है, उन्हें ऐरे के स्टोरेज वेरिएबल के स्लॉट से शुरू करते हुए क्रमिक (sequentially) रूप से स्लॉट असाइन करता है।
नीचे दिए गए कॉन्ट्रैक्ट पर विचार करें:
contract MyFixedUint256Array {
uint256 public num; // storage slot 0
uint256[3] public myArr = [
4, // storage slot 1
9, // storage slot 2
2 // storage slot 3
];
}
चूँकि num uint256 प्रकार का है और कॉन्ट्रैक्ट में पहला स्टेट वेरिएबल (state variable) है, यह पूरे storage slot 0 को घेर लेता है। दूसरा स्टेट वेरिएबल, myArr, uint256 का तीन एलिमेंट्स वाला एक fixed-size ऐरे है, जिसका अर्थ है कि प्रत्येक एलिमेंट अपना स्वयं का storage slot घेरेगा, जो स्लॉट 1 से शुरू होता है।
नीचे दिया गया एनीमेशन दिखाता है कि प्रत्येक वेरिएबल को storage slots कैसे आवंटित (allocate) किए जाते हैं, जिसमें विस्तार से बताया गया है कि प्रत्येक स्टोरेज वेरिएबल की वैल्यूज़ स्लॉट में कैसे स्टोर की जाती हैं।
आइए एक और उदाहरण देखें, जो पिछले वाले के समान है, लेकिन इस बार ऐरे के लिए डेटा प्रकार के रूप में uint32 का उपयोग किया गया है:
contract MyFixedUint32Array {
uint256 public num; // storage slot 0
uint32[3] public myArr = [
4, // storage slot ???
9, // storage slot ???
2 // storage slot ???
];
}
आगे पढ़ने से पहले, क्या आप ऐरे के तीसरे एलिमेंट के लिए storage slot बता सकते हैं? यदि आप सोच रहे हैं कि यह पिछले उदाहरण की तरह स्लॉट 3 हो सकता है, तो आप पुनर्विचार (reconsider) कर सकते हैं।
यदि प्रत्येक ऐरे एलिमेंट का प्रकार एक पूरा storage slot नहीं घेरता है, जैसे इस उदाहरण में uint32, तो कंपाइलर कई एलिमेंट्स को एक ही स्लॉट के भीतर तब तक एक साथ पैक (pack) करता है जब तक कि वह भर न जाए या अगले स्लॉट में जाने से पहले अगले एलिमेंट के लिए पर्याप्त जगह न बचे। यह उसी तरह है जैसे कंपाइलर द्वारा स्टोरेज वेरिएबल्स को एक साथ पैक किया जाता है जब वे व्यक्तिगत रूप से एक पूर्ण स्लॉट को नहीं घेरते हैं।
पैक की गई वैल्यूज़ को स्लॉट कैसे आवंटित किया जाता है:
नोट: पैक्ड एलिमेंट (packed element) को एक्सेस करने में अधिक गैस (gas) खर्च होगी क्योंकि EVM को सामान्य sload के अलावा अतिरिक्त निर्देश (instructions) जोड़ने होते हैं। अपने एलिमेंट्स को पैक करने की सलाह केवल तभी दी जाती है जब उन्हें आमतौर पर एक ही ट्रांज़ैक्शन में एक्सेस किया जाता हो और इस प्रकार वे कोल्ड लोड लागत (cold load costs) को साझा कर सकें।
Dynamic Arrays
Fixed-size ऐरे के विपरीत जिसका आकार कंपाइल समय (compile time) पर पूर्व-निर्धारित होता है, डायनामिक ऐरे रनटाइम (runtime) पर आकार बदल सकता है।
Dynamic Array के लिए Slot Allocation
आम तौर पर, डायनामिक ऐरे की लंबाई कहीं न कहीं स्टोर होती है क्योंकि कंपाइल समय पर यह ज्ञात नहीं होता है। Solidity डायनामिक ऐरे की लंबाई को एक अलग storage slot में स्टोर करके इस सिद्धांत का पालन करता है। नीचे बताया गया है कि डायनामिक ऐरे की लंबाई और एलिमेंट(s) दोनों को स्लॉट कैसे आवंटित किए जाते हैं।
ऐरे की लंबाई के लिए आवंटित किया गया storage slot वही स्लॉट होता है जो ऐरे स्टोरेज वेरिएबल (base slot) के लिए होता है। नीचे एक उदाहरण दिया गया है जो इसे स्पष्ट करता है:
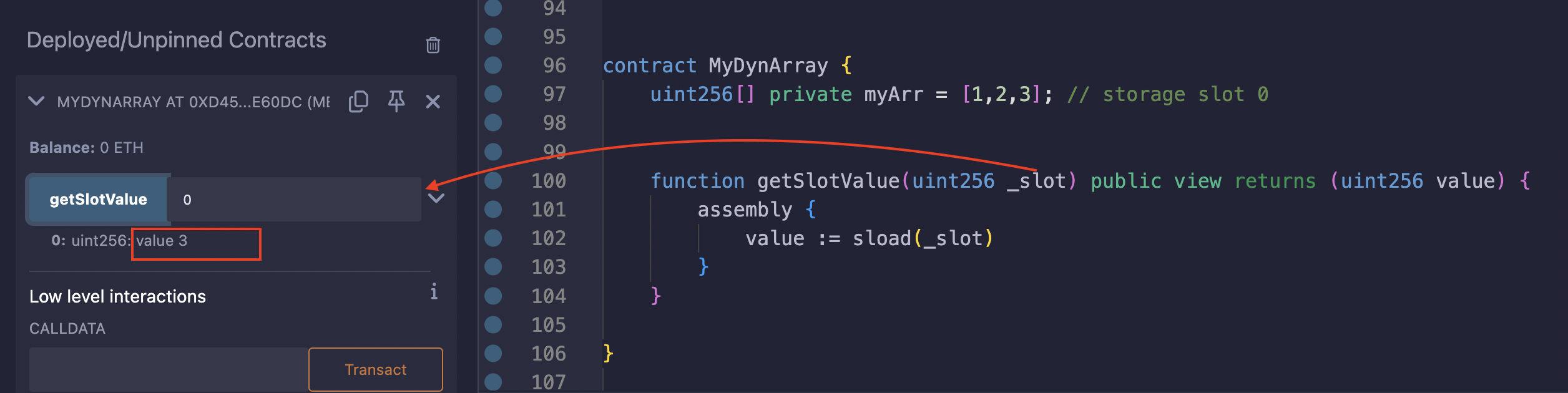
myArr वेरिएबल में तीन एलिमेंट्स हैं, जिससे इसकी लंबाई 3 हो जाती है। getSlotValue फ़ंक्शन, जैसा कि इसके नाम से पता चलता है, एक स्लॉट नंबर लेता और उसमें स्टोर की गई वैल्यू लौटाता है। हमारे मामले में, हमने स्लॉट 0 को आर्ग्यूमेंट के रूप में पास किया क्योंकि यह वह स्लॉट है जो myArr स्टोरेज वेरिएबल के लिए आवंटित किया गया है। इसके बाद हमने स्लॉट से वैल्यू लोड करने के लिए sload ऑपकोड का उपयोग किया।
ऐरे वैल्यूज़ को storage slots में क्रमिक रूप से (sequentially) रखा जाता है, जहाँ प्रत्येक storage slot ऐरे में एक इंडेक्स होता है। पहले एलिमेंट (इंडेक्स 0) के लिए storage slot, base storage slot (वह स्लॉट जहाँ वेरिएबल डिक्लेयर किया गया है) के keccak256 हैश द्वारा निर्धारित होता है। नीचे दी गई छवि इसे स्पष्ट करती है।
स्लॉट 2 का keccak हैश उस स्लॉट की ओर इशारा करता है जो पहले एलिमेंट को रखता है, फिर हम ऐरे में अन्य इंडेक्स के स्टोरेज स्थानों (storage locations) को प्राप्त करने के लिए उस वैल्यू में 1 जोड़ते जाते हैं:
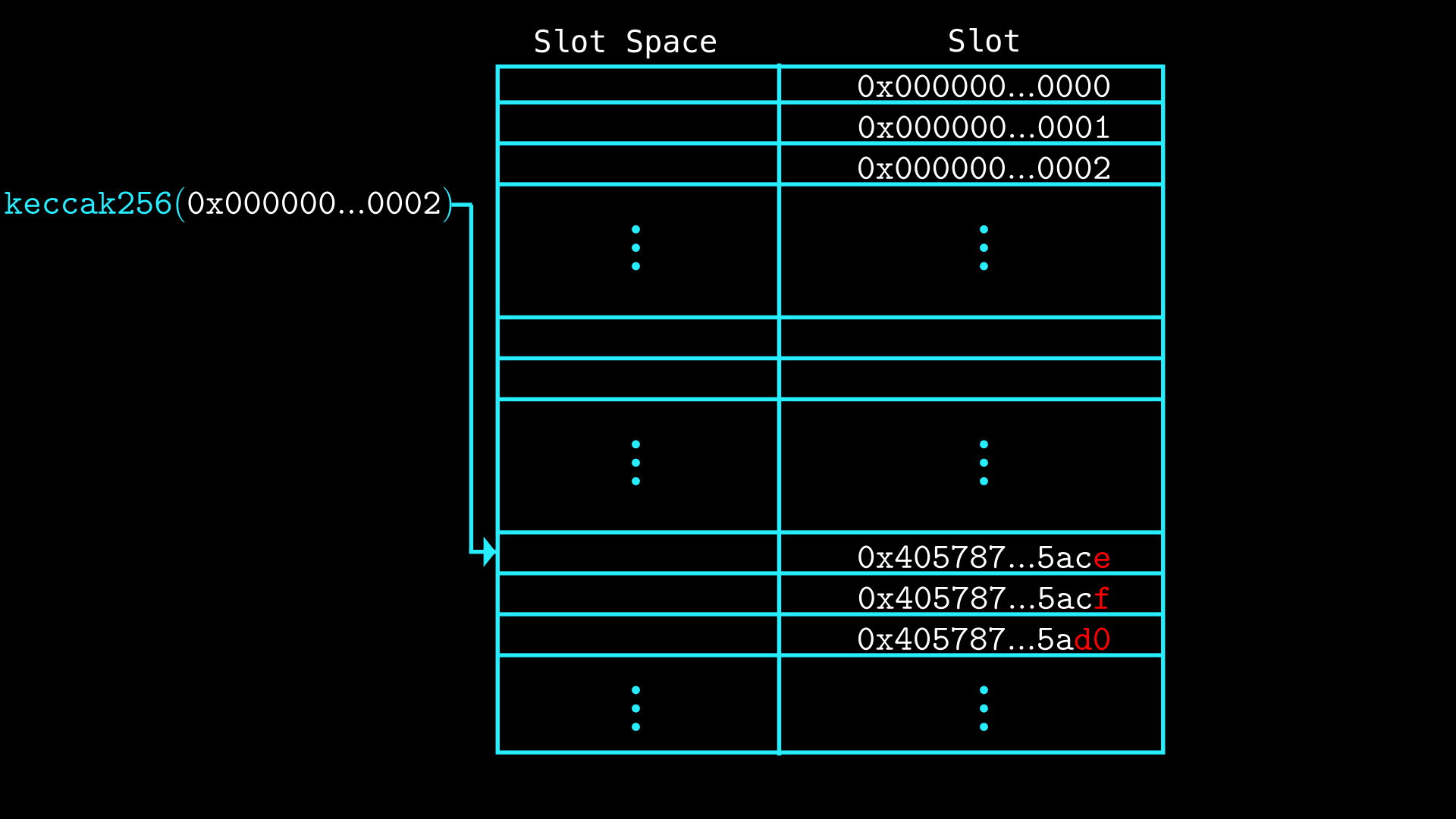
Storage slots को 0 से 2²⁵⁶ - 1 तक नंबर दिया गया है, और ठीक यही रेंज keccak256 आउटपुट करता है। छवि में पहली लाल वैल्यू (0x405787...5ace) स्लॉट 2 से प्राप्त हैश्ड (hashed) स्टोरेज स्थान को दर्शाती है, जो ऐरे के पहले एलिमेंट को रखती है। इसके बाद की प्रत्येक वैल्यू (0x405787...5acf, 0x405787...5ad0) पिछले वाले में वृद्धि (increment) है, जो ऐरे में अगले एलिमेंट के अनुरूप है। यह पैटर्न प्रत्येक अतिरिक्त एलिमेंट के लिए जारी रहता है, जिसमें स्टोरेज स्थान ऐरे के आकार के आधार पर क्रमिक रूप से बढ़ता है।
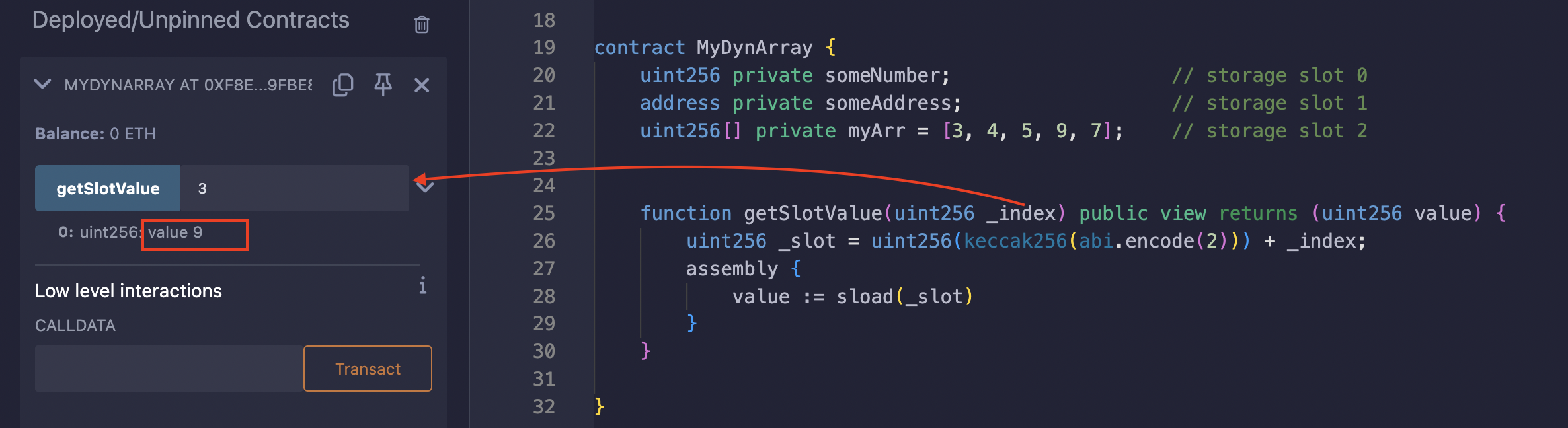
उदाहरण के लिए, storage slot 2 पर स्थित 5 लंबाई वाले एक ऐरे पर विचार करें, जिसमें uint256 प्रकार के एलिमेंट्स [3, 4, 5, 9, 7] हैं:
contract MyDynArray {
uint256 private someNumber; // storage slot 0
address private someAddress; // storage slot 1
uint256[] private myArr = [3, 4, 5, 9, 7]; // storage slot 2
function getSlotValue(uint256 _index) public view returns (uint256 value) {
uint256 _slot = uint256(keccak256(abi.encode(2))) + _index;
assembly {
value := sload(_slot)
}
}
}
वैल्यू 9 को रखने वाले storage slot को खोजने के लिए, हम पहले keccak256 का उपयोग करके base slot (2) को हैश करते हैं। फिर हम हैश की गई वैल्यू में एलिमेंट का इंडेक्स (इंडेक्स = 3) जोड़ते हैं। यह गणना हमें वैल्यू 9 को रखने वाला विशिष्ट storage slot देती है। अंत में, हम प्राप्त हुए _slot में वैल्यू को sload करते हैं।
Remix पर परीक्षण करें:
क्या होता है जब एलिमेंट्स storage slot स्थान का पूरी तरह उपयोग नहीं करते हैं?
उपलब्ध स्थान के भरने तक एलिमेंट्स को storage slots में पैक किया जाता है। केवल 128 बिट्स (16 बाइट्स) या उससे छोटे प्रकारों (types) को ही पैक किया जा सकता है। हालाँकि, एड्रेस, जिनमें से प्रत्येक 20 बाइट्स लेता है, पैक नहीं किए जाते हैं क्योंकि दो एड्रेस (40 बाइट्स) एक सिंगल storage slot के आकार से अधिक होते हैं।
आइए MyDynArray कॉन्ट्रैक्ट में uint256 के बजाय uint32 का उपयोग करने के लिए myArr को बदलें:
contract MyDynArray {
uint256 private someNumber; // storage slot 0
address private someAddress; // storage slot 1
uint32[] private myArr = [3, 4, 5, 9, 7]; // storage slot 2
function getSlotValue(uint256 _index) public view returns (bytes32 value) {
uint256 _slot = uint256(keccak256(abi.encode(2))) + _index;
assembly {
value := sload(_slot)
}
}
}
निम्नलिखित बदलाव किए गए हैं:
uint256[]⇒uint32[]: डायनामिक ऐरे के लिए डेटा प्रकार।uint256 value⇒bytes32 value: रिटर्न वैल्यू (return value), ताकि हम आसानी से देख सकें कि वैल्यूज़ कैसे पैक की जाती हैं।
प्रत्येक एलिमेंट प्रति storage slot उपलब्ध 32 बाइट्स में से 4 बाइट्स घेरता है। 5 एलिमेंट्स के साथ, कुल आकार 4 * 5 = 20 बाइट्स है। इसका मतलब है कि सभी एलिमेंट्स कुछ शेष स्थान के साथ एक सिंगल storage slot के भीतर फिट हो सकते हैं।
Remix पर परीक्षण करें:
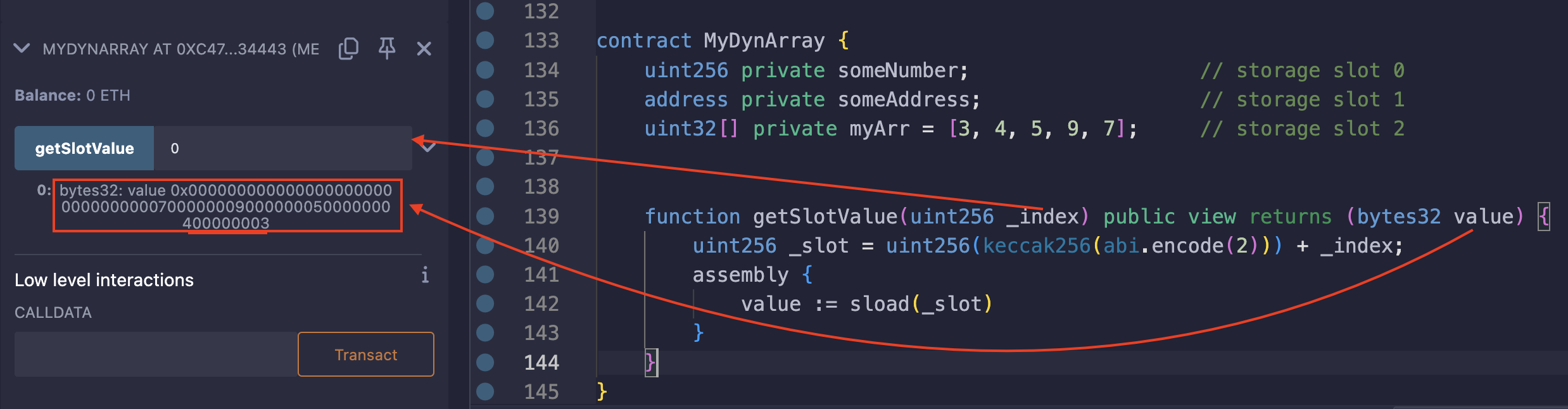
रिटर्न वैल्यू:

Nested Array
एक nested array वह ऐरे होता है जो अन्य ऐरे को रखता है। इसका उपयोग मैट्रिक्स-जैसी (matrix-like) डेटा को दर्शाने के लिए किया जा सकता है, जहाँ प्रत्येक पंक्ति (row) के भीतर के एलिमेंट्स एक ऐरे होते हैं, और कॉलम (column) उस ऐरे के भीतर एक इंडेक्स होता है।
नीचे दिया गया स्पष्टीकरण एनीमेशन कॉलम को संदर्भित करने के लिए C और पंक्तियों को संदर्भित करने के लिए R का उपयोग करता है।
C ⇒ हरा (green)
R ⇒ लाल (red)
Fixed-Size Nested Array के लिए Storage Slot
कंपाइलर fixed-size nested array में एलिमेंट्स के लिए स्लॉट उसी तरह आवंटित करता है जैसे यह एक नियमित fixed-size ऐरे के लिए करता है। प्रत्येक एलिमेंट को base slot से शुरू करते हुए क्रमिक (incrementally) रूप से एक स्लॉट आवंटित किया जाता है, यदि यह एक पूरे स्लॉट को घेरता है। अन्यथा, इसे अन्य एलिमेंट्स के साथ तब तक पैक किया जाता है जब तक कि स्लॉट का स्थान भर न जाए।
यहाँ एक सरल एनीमेशन दिया गया है जो दर्शाता है कि एक fixed-size nested array डेटा को कैसे स्टोर करता है:
Dynamic Nested Array के लिए Storage Slot
जैसा कि हम पहले से ही जानते हैं, एक डायनामिक ऐरे में किसी विशिष्ट एलिमेंट के लिए storage slot निर्धारित करने के चरण इस प्रकार हैं:
- base slot को keccak हैश करना
- फिर हैश वैल्यू में एलिमेंट का इंडेक्स जोड़ना
डायनामिक नेस्टेड ऐरे (dynamic nested arrays) के लिए, इस प्रक्रिया में अंतिम स्लॉट खोजने के लिए नेस्टिंग के प्रत्येक स्तर (level of nesting) के लिए उपरोक्त चरणों को दोहराना शामिल है।
मान लीजिए कि हमारे पास एक दो-स्तरीय नेस्टेड ऐरे (two-levels nested array) है, यानी ऐरे के भीतर ऐरे:
एलिमेंट f के लिए storage slot निर्धारित करने के चरण हैं:
- ऐरे के base slot को keccak हैश करना और फिर उस सब-ऐरे (sub-array) का इंडेक्स जोड़ना जो एलिमेंट को रखता है। हमारे मामले में, दूसरा सब-ऐरे।
- चरण 1 के परिणाम को keccak हैश करना और फिर सब-ऐरे में एलिमेंट
fका इंडेक्स जोड़ना।
यहाँ एक एनीमेशन है जो उपरोक्त चरणों को स्पष्ट करता है:
हम सबसे पहले base slot को हैश करते हैं और सब-ऐरे का इंडेक्स (sub-array1, जो बेस ऐरे में इंडेक्स 1 है) जोड़ते हैं, जो हमें प्रारंभिक हैश (प्रारंभिक हैश, वह स्लॉट जो सब-ऐरे को रखता है) देता है। इसके बाद, हम इस प्रारंभिक हैश को हैश करते हैं और अंतिम स्लॉट निर्धारित करने के लिए sub-array1 के भीतर एलिमेंट f का इंडेक्स (जो 2 है) जोड़ते हैं।
uint256 डायनामिक नेस्टेड ऐरे में किसी एलिमेंट के लिए स्लॉट प्राप्त करने का एक व्यावहारिक (practical) उदाहरण:
contract MyNestedArray {
uint256 private someNumber; // storage slot 0
// Initialize nested array
uint256[][] private a = [[2,9,6,3],[7,4,8,10]]; // storage slot 1
function getSlot(uint256 baseSlot, uint256 _index1, uint256 _index2) public pure returns (bytes32 _finalSlot) {
// keccak256(baseSlot) + _index1
uint256 _initialSlot = uint256(keccak256(abi.encode(baseSlot))) + _index1;
// keccak256(_initialSlot) + _index2
_finalSlot = bytes32(uint256(keccak256(abi.encode(_initialSlot))) + _index2);
}
function getSlotValue(uint256 _slot) public view returns (uint256 value) {
assembly {
value := sload(_slot)
}
}
}
मान लीजिए कि हम उपरोक्त कॉन्ट्रैक्ट में [[2,9,6,3],[7,4,8,10]] ऐरे में एलिमेंट 8 को रखने वाला storage slot ढूंढना चाहते हैं।
-
हमें तीन चीजों को पहचानने की आवश्यकता है:
- नेस्टेड ऐरे का base slot
- एलिमेंट वाले सब-ऐरे का इंडेक्स,
- और उस सब-ऐरे के भीतर एलिमेंट का इंडेक्स।
हमारा वांछित (desired) स्लॉट प्राप्त करने के लिए इन इंडेक्स की आवश्यकता होती है।
-
हम baseSlot और इंडेक्स की वैल्यूज़ पास करते हुए
getSlotफ़ंक्शन को कॉल करते हैं:- baseSlot: ऐरे
aके लिए स्लॉट, जो स्लॉट 1 है। - _index1: एलिमेंट वाले सब-ऐरे (
[7,4,8,10]) का इंडेक्स 1 है। - _index2: सब-ऐरे के भीतर एलिमेंट
8इंडेक्स 2 पर है।
कॉल के बाद वापस आया स्लॉट:
0xea7809e925a8989e20c901c4c1da82f0ba29b26797760d445a0ce4cf3c6fbd33 - baseSlot: ऐरे
-
अंत में, चरण 2 से वापस आए स्लॉट को पास करते हुए
getSlotValueफ़ंक्शन को कॉल करें।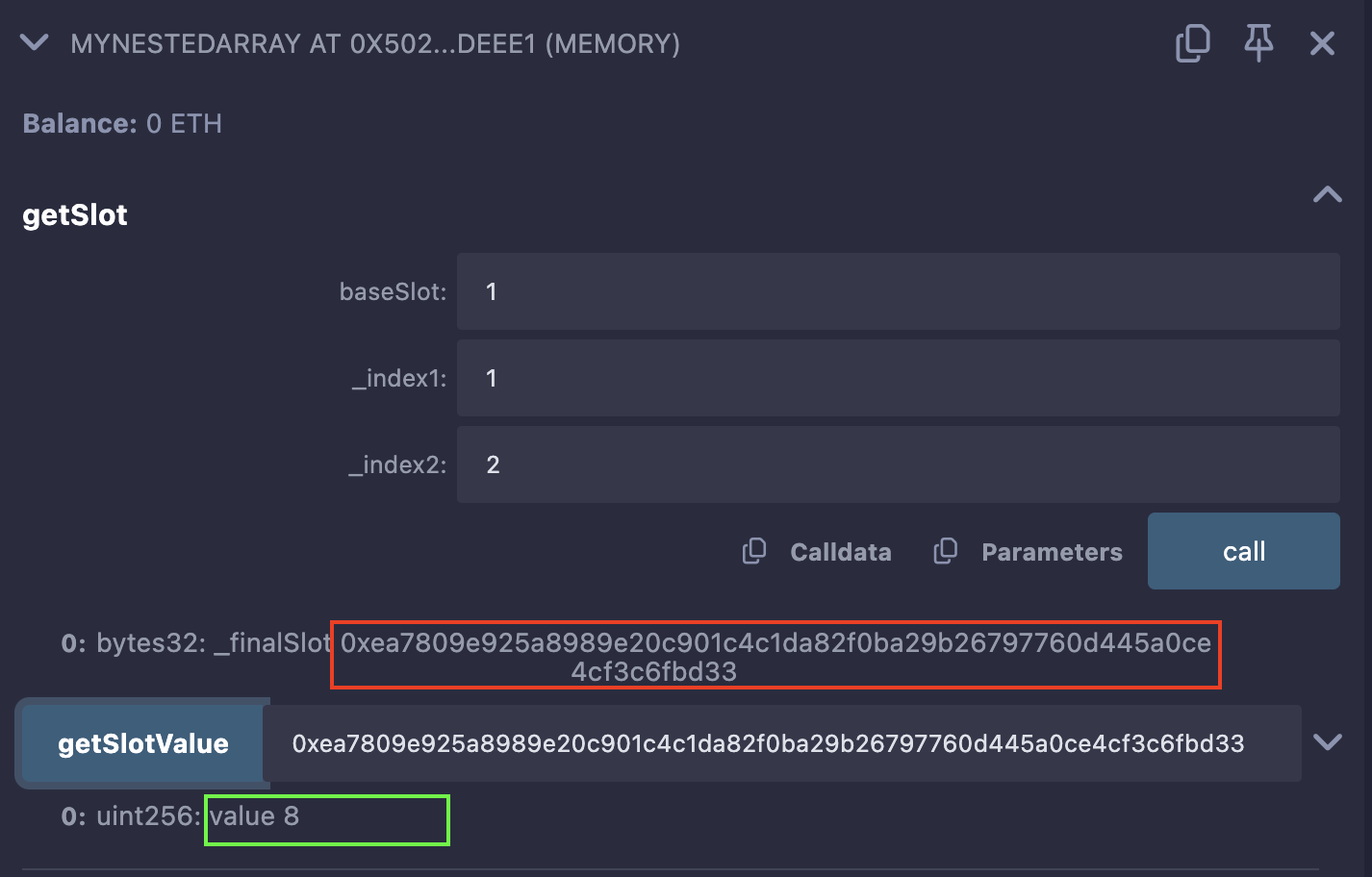
String
Solidity में स्ट्रिंग्स डायनामिक प्रकार (dynamic types) की होती हैं, जिसका अर्थ है कि उनकी लंबाई निश्चित नहीं होती है। कुछ स्ट्रिंग्स एक सिंगल storage slot के भीतर फिट हो सकती हैं, जबकि अन्य को कई स्लॉट्स की आवश्यकता हो सकती है।
निम्नलिखित उदाहरण कॉन्ट्रैक्ट पर विचार करें:
contract String {
string public myString;
uint256 public num;
}
string का storage slot 0 है और uint256 का storage slot 1 है।
यदि हम myString में एक छोटा स्ट्रिंग डेटा स्टोर करते हैं (जो 32 बाइट्स से कम है, हम बाद में चर्चा करेंगे कि 32 बाइट्स वाली स्ट्रिंग को लंबी स्ट्रिंग क्यों माना जाता है), तो हम इसे बिना किसी समस्या के स्लॉट 0 से प्राप्त (retrieve) कर सकते हैं।
हालाँकि, यदि हम एक लंबा स्ट्रिंग डेटा स्टोर करते हैं, मान लें कि जो 42 बाइट्स लेता है, तो यह स्लॉट 0 को ओवरफ़्लो (overflow) करेगा और स्लॉट 1 को ओवरराइट कर देगा, जो शुरू में num वेरिएबल के लिए आरक्षित (reserved) है।
ऐसा इसलिए होता है क्योंकि स्लॉट 0 लंबी स्ट्रिंग को समाहित करने के लिए पर्याप्त बड़ा नहीं होता है। इस समस्या को रोकने के लिए, Solidity स्ट्रिंग की लंबाई के आधार पर string प्रकारों के लिए storage slots आवंटित करने के लिए अलग-अलग तरीकों का उपयोग करता है।
Strings के लिए Storage Slot
स्टोरेज वेरिएबल स्लॉट (base slot) छोटी स्ट्रिंग्स (short strings) के लिए स्ट्रिंग को उसकी लंबाई की जानकारी के साथ स्टोर करता है या लंबी स्ट्रिंग्स के लिए केवल उसकी लंबाई की जानकारी स्टोर करता है, और इन मामलों का अध्ययन नीचे अलग-अलग सेक्शन में किया जाएगा।
छोटी स्ट्रिंग (Short String) (≤ 31 बाइट्स):
स्ट्रिंग डेटा और उसकी लंबाई दोनों को एक साथ base slot में स्टोर किया जाता है। स्ट्रिंग को बाईं ओर से पैक किया जाता है, जबकि उसकी लंबाई को स्लॉट के सबसे दाईं ओर के बाइट (rightmost byte) में स्टोर किया जाता है। छोटी स्ट्रिंग्स के लिए, स्ट्रिंग की अधिकतम लंबाई 31 कैरेक्टर्स होती है। हालाँकि, प्रोटोकॉल द्वारा वास्तव में जो स्टोर किया जाता है वह स्ट्रिंग की लंबाई को 2 से गुणा करके होता है, क्योंकि प्रत्येक कैरेक्टर स्टोरेज में एक बाइट घेरता है। इसका मतलब है कि छोटी स्ट्रिंग के लिए जो अधिकतम वैल्यू स्टोर की जा सकती है वह 31 * 2 = 62 है, जो हेक्साडेसिमल में 0x3e है।
नीचे हेक्स में एक छोटी स्ट्रिंग Hello World का उदाहरण दिया गया है। ज़ीरो (zeros) खाली जगह (free space) हैं जिनका उपयोग 31 बाइट्स तक की लंबी स्ट्रिंग को स्टोर करने के लिए किया जा सकता है, और अंतिम बाइट में (स्ट्रिंग की लंबाई) * 2 होता है।
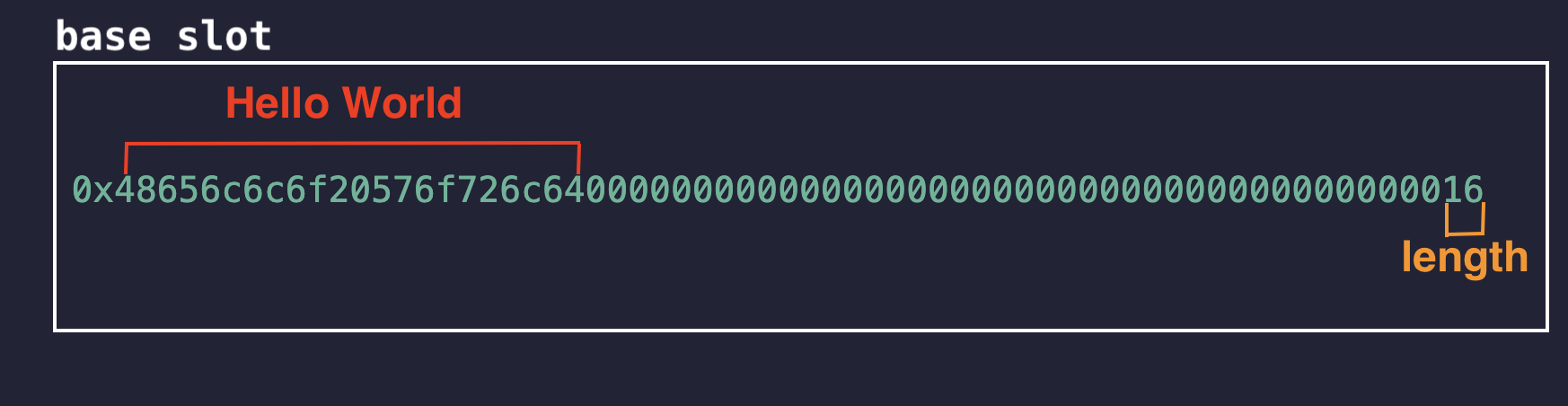
यहाँ 0x16 = 22 है जो 2 * 11 है, जहाँ 11 Hello World स्ट्रिंग की लंबाई है।
लंबी स्ट्रिंग (Long String) (> 31 बाइट्स):
(स्ट्रिंग की लंबाई * 2) + 1 (हम कुछ ही देर में 1 जोड़ने का कारण बताएंगे) base slot में स्टोर किया जाता है, फिर हेक्स में स्ट्रिंग को एक निरंतर storage slot स्पेस (continuous storage slot space) में स्टोर किया जाता है। स्ट्रिंग डेटा के पहले 32 बाइट्स base slot के keccak256 हैश पर स्टोर किए जाते हैं। अगले 32 बाइट्स base slot के हैश प्लस वन (+1) पर, और अगले हैश प्लस टू (+2) पर, और इसी तरह तब तक स्टोर किए जाते हैं जब तक कि पूरी स्ट्रिंग स्टोर न हो जाए।
निम्नलिखित एनीमेशन दिखाता है कि लंबाई और लंबी स्ट्रिंग (हेक्स में) storage slots में कैसे स्टोर की जाती हैं:
लंबी स्ट्रिंग की लंबाई को स्टोर करने से पहले, कंपाइलर उसमें एक (1) जोड़ता है (जिससे वह सम से विषम (even to odd) हो जाती है)। उदाहरण के लिए, ऊपर एनीमेशन में स्ट्रिंग 47 बाइट्स (32 + 15) लेती है, जिसका अर्थ है कि इसकी लंबाई 47 * 2 = 94 (हेक्स में 0x5e) है। Solidity कंपाइलर तब इस लंबाई में 1 जोड़ता है, जिससे यह 95 (हेक्स में 0x5f) हो जाती है, और इस वैल्यू को base slot में स्टोर करता है।
इसका कारण रनटाइम बाइटकोड (runtime bytecode) को छोटी और लंबी स्ट्रिंग्स के बीच कुशलतापूर्वक अंतर करने की अनुमति देना है। छोटी स्ट्रिंग्स के लिए, लंबाई हमेशा सम (even) होती है, इसलिए base slot में स्टोर की गई वैल्यू का अंतिम बिट हमेशा शून्य (zero) होगा। दूसरी ओर, लंबी स्ट्रिंग्स (32 बाइट्स या अधिक) की लंबाई हमेशा विषम (odd) होती है, जिसका अर्थ है कि अंतिम बिट हमेशा एक (one) होगा।
अनुकूलित (Optimized) Even और Odd जाँच
अधिकांश प्रोग्रामिंग भाषाओं में यह जाँचने का सामान्य तरीका कि कोई संख्या सम (even) है या विषम (odd), मॉड्यूलर ऑपरेटर (num % 2) का उपयोग करना और यह जाँचना है कि शेषफल (remainder) 0 है या नहीं। यह Solidity में भी लागू होता है। हालाँकि, एक अधिक अनुकूलित (optimized) तरीका बिटवाइज़ AND (bitwise AND) ऑपरेशन का उपयोग करना है: num & 1 == 0। नीचे दोनों तरीकों और उनकी संबंधित लागतों (costs) का एक उदाहरण दिया गया है:
contract ModMethod {
// Gas cost: 761
function isEven(uint256 num) public pure returns (bool x) {
x = (num % 2) == 0;
}
}
contract BitwiseAndMethod {
// Gas cost: 589
function isEven(uint256 num) public pure returns (bool x) {
x = (num & 1) == 0;
}
}
String की लंबाई (Length) प्राप्त करें
Solidity में स्ट्रिंग प्रकार (String type) में length प्रॉपर्टी नहीं होती है। ऐसा इसलिए है क्योंकि कुछ कैरेक्टर्स, विशेष रूप से गैर-ascii (non-ascii) में, एक से अधिक बाइट ले सकते हैं, इसलिए यह ट्रैक करना कि कितने कैरेक्टर्स हैं, जब उनके साइज़ अलग-अलग हो सकते हैं, बहुत अधिक ओवरहेड (overhead) पैदा करता है। हालाँकि, हम नीचे दिए गए उदाहरण के अनुसार इसे बाइट्स में कास्ट करके (casting to bytes) यह देख सकते हैं कि स्ट्रिंग कितने बाइट्स लेती है:
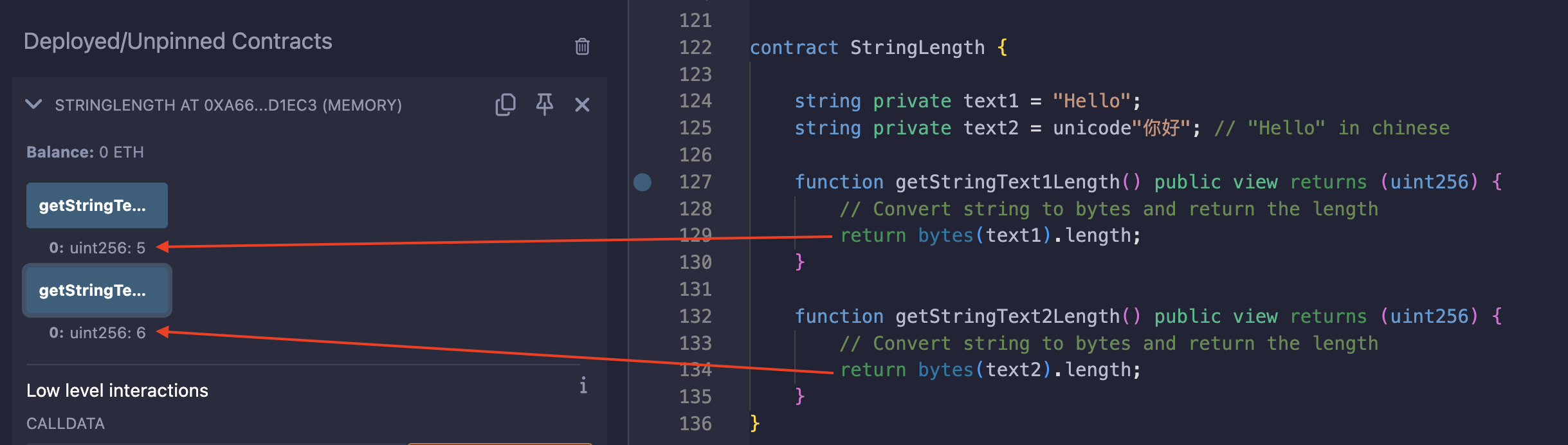
text2 में, प्रत्येक कैरेक्टर 3 बाइट्स लेता है, जिससे यह 6 बाइट्स हो जाता है। किसी स्ट्रिंग पर length प्रॉपर्टी का उपयोग करने के लिए, आपको स्क्रीनशॉट की तरह स्ट्रिंग को bytes में बदलना (convert) होगा।
Bytes
स्ट्रिंग्स की तरह ही, बाइट्स (bytes) Solidity में एक डायनामिक प्रकार है और स्लॉट आवंटन (slot allocation) के लिए नियमों के समान सेट का पालन करता है।
- शॉर्ट (Short) bytes (≤ 31 बाइट्स): पूरी तरह से base slot में स्टोर किया जाता है, जिसमें इसकी लंबाई भी शामिल है (
बाइट्स की संख्या * 2)। - लॉन्ग (Long) bytes (> 31 बाइट्स): base slot लंबाई (
(बाइट्स की संख्या * 2) + 1) को स्टोर करता है, और वास्तविक डेटा base slot केkeccak256हैश से शुरू होने वाले लगातार स्लॉट्स (consecutive slots) में स्टोर किया जाता है।
Fixed-Size Bytes
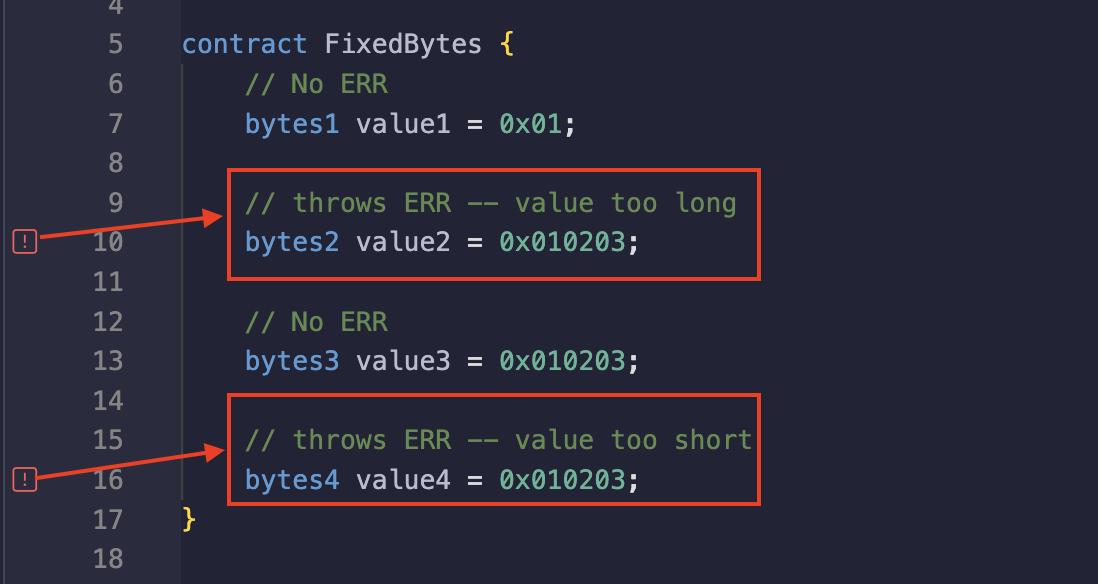
ये ऐसे प्रकार (types) हैं जिनका उपयोग बाइट्स की एक निश्चित संख्या (fixed number) को स्टोर करने के लिए किया जाता है। इन प्रकारों की रेंज bytes1 से bytes32 तक होती है, जिसका अर्थ है कि आपके पास fixed-size बाइट ऐरे हो सकते हैं जो 1 से 32 बाइट्स तक रखते हैं।
उपयोग किए गए बाइट साइज़ से अधिक या कम वैल्यू स्टोर करने पर कंपाइल टाइम एरर (compile time error) आएगा। नीचे दी गई छवि में, वेरिएबल value2 और value4 को ऐसी वैल्यूज़ असाइन की गई हैं जो उनके अपेक्षित बाइट साइज़ के अनुसार नहीं हैं, जिसके परिणामस्वरूप कंपाइलेशन एरर आता है।
हमने अपने पिछले अधिकांश कोड उदाहरणों में keccak256 हैश को रखने के लिए bytes32 का उपयोग किया है।
व्यक्तिगत बाइट (Individual Byte) को एक्सेस करना
एक fixed-size bytes ऐरे के भीतर एक बाइट को उसके इंडेक्स का उपयोग करके एक्सेस किया जा सकता है।
उदाहरण के लिए, निम्नलिखित कॉन्ट्रैक्ट पहले बाइट को एक्सेस करता है:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.9;
contract FixedBytes {
bytes4 value = hex"01020304";
function accessFirstByte() public view returns (bytes1) {
bytes1 individualByte = value[0]; // Access the first byte
return individualByte; // Returns the first byte
}
}
accessFirstByte फ़ंक्शन एक सिंगल बाइट (bytes1) लौटाता है। फ़ंक्शन के अंदर, value[0] value ऐरे के पहले बाइट को एक्सेस करता है। फिर यह बाइट लौटाया जाता है।
Solidity वर्ज़न 0.8.0 से पहले, सिंगल बाइट को दर्शाने के लिए bytes1 के बजाय byte प्रकार का उपयोग किया जाता था। वर्ज़न 0.8.0 और उससे ऊपर में, अब सिंगल बाइट वैल्यू को रखने के लिए bytes1 को प्राथमिकता दी जाती है।
string/bytes और bytes1[] की तुलना
दोनों डायनामिक प्रकार हैं जो बाइट वैल्यूज़ को स्टोर करते हैं, और दोनों मामलों में, बाइट्स को उनके इंडेक्स द्वारा एक्सेस किया जाता है। हालाँकि, मुख्य अंतर इस बात में है कि बाइट वैल्यूज़ को कैसे स्टोर किया जाता है।
निम्नलिखित कॉन्ट्रैक्ट्स पर विचार करें जो bytes और bytes1[] दोनों प्रकारों के लिए समान बाइट वैल्यू को स्टोर करते हैं:
contract Bytes {
bytes foo_bytes = hex"ffeedd";
// helper to get slot value
function getSlotValue() public view returns (bytes32 x) {
assembly {
x := sload(0)
}
}
}
contract Bytes1Array {
bytes1[] bar_bytes = [bytes1(hex"ff"), bytes1(hex"ee"), bytes1(hex"dd")];
// helper to get slot value
function getSlotValue() public view returns (bytes32 x) {
bytes32 _slot = keccak256(abi.encode(0));
assembly {
x := sload(_slot)
}
}
}
चूँकि foo_bytes वेरिएबल को असाइन की गई वैल्यू एक शॉर्ट bytes अनुक्रम (sequence) है (यानी, ≤ 31 बाइट्स), इसलिए वैल्यू और इसकी लंबाई (बाइट्स की संख्या * 2) दोनों एक ही storage slot (base slot) में इस प्रकार स्टोर किए जाते हैं:
दूसरी ओर, bar_bytes वेरिएबल, जो bytes1[] प्रकार (एक डायनामिक ऐरे) का है, ऐरे की लंबाई और वैल्यूज़ को अलग-अलग स्लॉट में स्टोर करता है:
लंबाई base slot में स्टोर की जाती है:
वैल्यूज़ base slot के हैश में स्टोर की जाती हैं:
दूसरे शब्दों में, शॉर्ट सीक्वेंस वाले bytes प्रकार bytes1[] की तुलना में कम storage slots का उपयोग करते हैं। हालाँकि, 31 बाइट्स से अधिक लंबे सीक्वेंस के लिए, bytes प्रकार उसी स्लॉट गणना (slot calculation) का उपयोग करता है जो bytes1[] करता है, जिसके परिणामस्वरूप उपयोग किए गए स्लॉट्स की संख्या समान होती है।
bytes और bytes1[] के बीच एक और अंतर यह है कि उनकी वैल्यूज़ को स्लॉट में कैसे स्टोर किया जाता है। foo_bytes के लिए, पूरी वैल्यू को उसके स्लॉट(स्लॉट्स) में एक ही बार में रखा जाता है। इसके विपरीत, bar_bytes के लिए, पहला एलिमेंट सबसे कम महत्वपूर्ण बाइट (least significant byte) में स्टोर किया जाता है, उसके बाद अगला एलिमेंट आता है, और यह पैटर्न अंतिम बाइट तक जारी रहता है।
एनीमेशन दिखाता है कि foo_bytes और bar_bytes वेरिएबल को असाइन की गई नई वैल्यूज़ कैसे दो-दो स्लॉट (हरे और पीले रंग में स्लॉट) लेती हैं, जिसमें foo_bytes स्लॉट 0 लेता है और bar_bytes स्लॉट 1 लेता है:
Struct
Solidity में Structs हमें अलग-अलग डेटा प्रकारों के कई वेरिएबल्स को एक सिंगल नाम के तहत ग्रुप करने और इसे एक नए प्रकार के रूप में उपयोग करने की अनुमति देते हैं। उदाहरण के लिए, यदि हमें प्लेयर की जानकारी जैसे कि playerId, score, और level को स्टोर करने के लिए एक कॉन्ट्रैक्ट की आवश्यकता है, तो struct का उपयोग करना आदर्श विकल्प होगा। इस तरह, हम प्रत्येक प्लेयर के बारे में सभी प्रासंगिक (relevant) विवरणों को एक ही संगठित (organized) स्ट्रक्चर में एक साथ रख सकते हैं।
Struct में Storage Slot
Solidity में एक struct वेरिएबल्स के लिए एक कंटेनर के रूप में कार्य करता है, और struct के भीतर प्रत्येक फ़ील्ड के लिए storage slot आवंटन उन्हीं नियमों का पालन करता है जिन पर हमने पहले चर्चा की है।
आइए एक उदाहरण देखें:
contract MyStruct {
// Define a Player struct
struct Player {
address playerId;
uint256 score;
uint256 level;
}
uint256 private someNumber = 99;
/*
AFTER DIFFERENT DECLARATIONS ABOVE, THE NEXT AVAILABLE SLOT IS: 6
*/
// Declare a state variable of type Player
Player private thePlayer;
}
कोड को चलाए (run) बिना, क्या आप स्लॉट 0 की वैल्यू का अनुमान लगा सकते हैं? यदि आपको लगता है कि यह 99 है, तो आप सही हैं। ऐसा इसलिए है क्योंकि Solidity में किसी struct को डिफ़ाइन (define) करने से कोई storage slot स्थान नहीं घिरता जब तक कि उसे डिक्लेयर (declare) नहीं किया जाता, इसलिए कंपाइलर someNumber वेरिएबल को पहले स्टोरेज वेरिएबल के रूप में देखता है।
Player Struct प्रकार के वेरिएबल को डिक्लेयर करें:
आइए जाँचें कि structs के साथ स्टोरेज कैसे काम करता है, सबसे पहले एक struct को डिक्लेयर करके — ऐसा करने से यह वास्तव में स्टोरेज लेगा। ध्यान दें कि हम इसे डिक्लेयर कर रहे हैं, न कि पहले की तरह डिफ़ाइन कर रहे हैं।
/*
AFTER DIFFERENT DECLARATIONS ABOVE, THE NEXT AVAILABLE SLOT IS: 6
*/
// Declare a state variable of type Player
Player private thePlayer;
Player struct के भीतर के फ़ील्ड डिक्लेयर किए जाने पर base slot से शुरू होकर तीन लगातार (consecutive) storage slots घेरेंगे। playerId फ़ील्ड, जो एड्रेस प्रकार का है, एक स्लॉट में उपलब्ध 32 बाइट्स में से 20 बाइट्स का उपयोग करता है। score और level फ़ील्ड, uint256 प्रकार के होने के कारण, प्रत्येक 256 बिट्स (32 बाइट्स) का एक पूर्ण स्लॉट स्थान घेरते हैं। यह ज्ञात होने के साथ, हम कह सकते हैं कि फ़ील्ड्स के लिए storage slots क्रमशः 6, 7 और 8 हैं।
Struct के भीतर Dynamic Types के लिए Storage Slot Allocation
एक अन्य उदाहरण struct के भीतर डायनामिक प्रकारों (dynamic types) का होना है। आइए मैपिंग का उपयोग करने के लिए पिछले उदाहरण को संशोधित (modify) करें और इसे कुछ वैल्यूज़ भी असाइन करें:
contract MyStruct {
// Define a Player struct
struct Player {
address playerId;
mapping(uint256 level => uint256 score) playerScore;
}
uint256 private someNumber = 23; // storage slot 0
uint256 private someNumber1 = 77; // storage slot 1
// Declare a state variable of type Player
Player private thePlayer;
constructor () {
// Set deployer's address as player's id
thePlayer.playerId = msg.sender;
// Set player's score to 100 for level 1 and 68 for level 2
thePlayer.playerScore[1] = 100;
thePlayer.playerScore[2] = 68;
}
}
Struct के भीतर मैपिंग में किसी वैल्यू के लिए storage slot की गणना करने के चरण इस प्रकार हैं:
thePlayerstruct के base slot की पहचान करें: यह स्लॉट तब निर्धारित होता है जब struct को कॉन्ट्रैक्ट में डिक्लेयर किया जाता है।- Struct के भीतर
playerScoreमैपिंग के लिए स्लॉट की गणना करें: यह स्लॉट उस क्रम से निर्धारित होता है जिसमें मैपिंग को struct में डिक्लेयर किया गया है। - Key और मैपिंग के base slot, यानी चरण 2 में प्राप्त स्लॉट के कॉनकैटेनेशन (concatenation) को हैश करें।
इन चरणों के ज्ञात होने के साथ, हम लेवल 2 के लिए प्लेयर का स्कोर रखने वाले storage slot की गणना कर सकते हैं।
चरण 1: thePlayer के base slot की पहचान करें
thePlayerऊपर कॉन्ट्रैक्ट में डिक्लेयर किया गया एक struct है, और चूँकि इसेsomeNumberऔरsomeNumber1वेरिएबल के बाद डिक्लेयर किया गया है, इसका base slot स्लॉट2होगा (क्योंकिsomeNumberस्लॉट 0 को घेरता है औरsomeNumber1स्लॉट 1 को घेरता है)।
चरण 2: Struct के भीतर playerScore मैपिंग के लिए स्लॉट की गणना करें
// Define a Player struct
struct Player {
address playerId;
mapping(uint256 level => uint256 score) playerScore;
}
- Struct के base slot (स्लॉट 2) से शुरू होकर, प्रत्येक फ़ील्ड को क्रमिक (sequentially) रूप से स्लॉट असाइन किए जाते हैं। इसका मतलब है कि
addressप्रकार का पहला फ़ील्डplayerId, स्लॉट 2 (base slot) को घेरता है, जबकि दूसरा फ़ील्डplayerScoreमैपिंग, अगले स्लॉट में रखा गया है, जो स्लॉट3(मैपिंग का base slot) है।
चरण 3: Key और मैपिंग के base slot के कॉनकैटेनेशन को हैश करें
-
Key और मैपिंग के base slot के ज्ञात होने के साथ, हम उन्हें कॉनकैटेनेट और हैश करके अपने लक्ष्य (target) storage slot की गणना कर सकते हैं।
निम्नलिखित छवि दिखाती है कि सही key (इस मामले में, एक लेवल
2) और मैपिंग के base slot (3) को पास करके, फिर लक्ष्य स्लॉट (target slot) कोsloadकरके लक्ष्य स्लॉट (हरा बॉक्स) कैसे निर्धारित किया जाता है: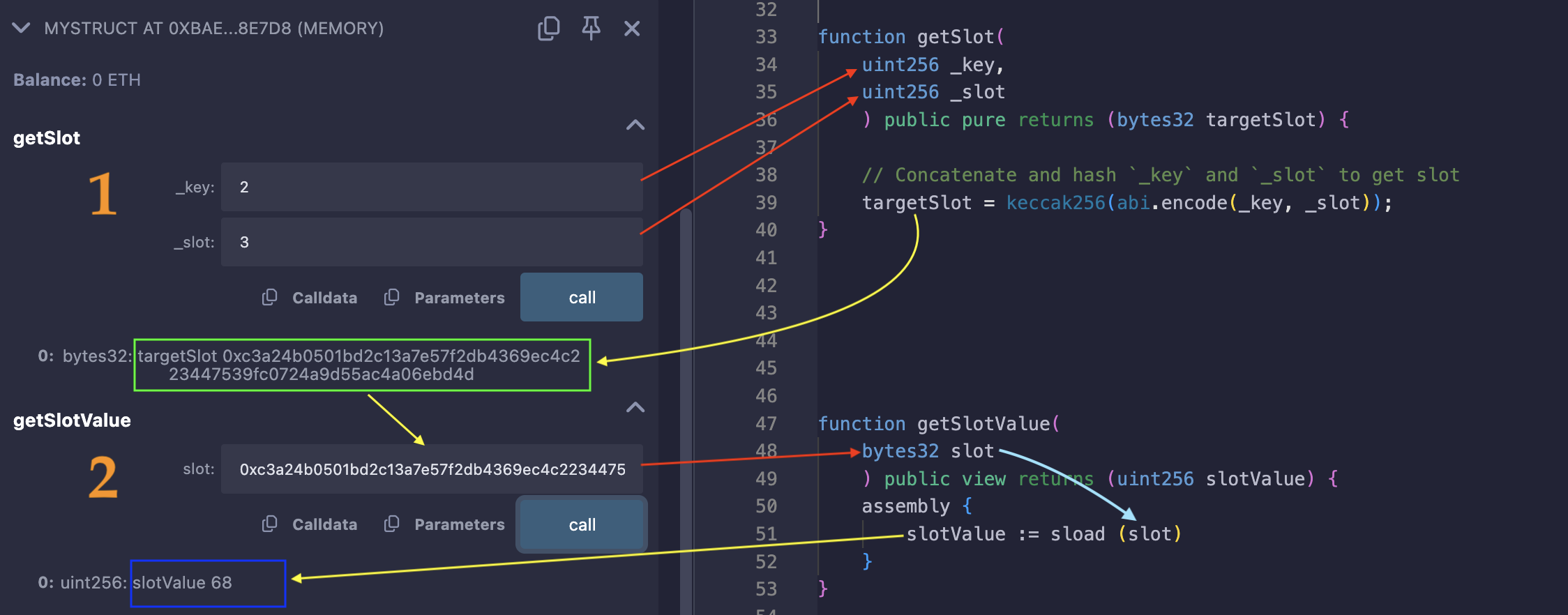
नीले बॉक्स में, लक्ष्य स्लॉट को sload करने से वापस आई वैल्यू (लेवल 2 के लिए प्लेयर का स्कोर) है।