如果我们有一个包含对向量 a \mathbf{a} a Pedersen vector commitment A A A A = a 1 G 1 + a 2 G 2 + ⋯ + a n G n A = a_1G_1 + a_2G_2+\dots + a_nG_n A = a 1 G 1 + a 2 G 2 + ⋯ + a n G n a \mathbf{a} a A = ? a 1 G 1 + ⋯ + a n G n A \stackrel{?}= a_1G_1 + \dots + a_nG_n A = ? a 1 G 1 + ⋯ + a n G n n n n a \mathbf{a} a n n n
在上一章中,我们展示了如何在零知识的情况下做到这一点。在本章中,我们将展示如何通过发送少于 n n n
动机
我们在此开发的技术将成为一个重要的基础模块,用于证明内积的有效计算,其证明大小为 log n \log n log n n n n
在上一章中,我们展示了如何证明我们正确执行了内积计算,而无需泄露向量或结果。然而,由于证明者发送 l u \mathbf{l}_u l u r u \mathbf{r}_u r u O ( n ) \mathcal{O}(n) O ( n )
本文中的子程序对于减小证明的大小将非常重要。本文不涉及零知识,因为之前讨论的算法本身就具备零知识属性。也就是说,l u \mathbf{l}_u l u r u \mathbf{r}_u r u
问题陈述
给定一个商定的基向量 G = [ G 1 , … , G n ] \mathbf{G}=[G_1,\dots,G_n] G = [ G 1 , … , G n ] A A A A A A a \mathbf{a} a A = ⟨ [ a 1 , … , a n ] , [ G 1 , … , G n ] ⟩ A = \langle[a_1,\dots,a_n],[G_1,\dots,G_n]\rangle A = ⟨[ a 1 , … , a n ] , [ G 1 , … , G n ]⟩ n n n [ a 1 , … , a n ] [a_1,\dots,a_n] [ a 1 , … , a n ]
小于 n n n
缩小证明大小依赖于三个洞见:
洞见 1:内积 ⟨ a , b ⟩ \langle \mathbf{a},\mathbf{b}\rangle ⟨ a , b ⟩
我们要利用的第一个洞见是,内积是外积 的对角线。换句话说,从某种意义上说,外积“包含”了内积。在一维向量的语境中,外积是一个二维矩阵,由第一个一维向量中的每个元素与第二个向量中的每个元素相乘形成。例如:
a = [ a 1 , a 2 ] , b = [ b 1 , b 2 ] , a ⊗ b = ( a 1 b 1 a 1 b 2 a 2 b 1 a 2 b 2 ) \begin{align*}
\mathbf{a}=[a_1, a_2],\space
\mathbf{b}=[b_1, b_2],
\end{align*}
\space\space
\mathbf{a} \otimes \mathbf{b} = \begin{pmatrix}
\boxed{a_1 b_1} & a_1 b_2 \\
a_2 b_1 & \boxed{a_2 b_2} \\
\end{pmatrix} a = [ a 1 , a 2 ] , b = [ b 1 , b 2 ] , a ⊗ b = ( a 1 b 1 a 2 b 1 a 1 b 2 a 2 b 2 )
这似乎是朝着错误方向迈出的一步,因为外积需要 O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) O ( 1 ) \mathcal{O}(1) O ( 1 ) 间接地 计算外积。
洞见 2:外积的和等于原向量和的乘积
第二个观察结果是,外积各项的和等于各个向量和的乘积。也就是说,
∑ i = 1 n a i ∑ i = 1 n b i = ∑ a ⊗ b \sum_{i=1}^{n} a_i\sum_{i=1}^{n} b_i=\sum\mathbf{a} \otimes \mathbf{b} i = 1 ∑ n a i i = 1 ∑ n b i = ∑ a ⊗ b
对于我们向量 [ a 1 , a 2 ] [a_1,a_2] [ a 1 , a 2 ] [ b 1 , b 2 ] [b_1,b_2] [ b 1 , b 2 ]
( a 1 + a 2 ) ( b 1 + b 2 ) ⏟ ∑ a i ∑ b i = a 1 b 1 + a 1 b 2 + a 2 b 1 + a 2 b 2 ⏟ ∑ a ⊗ b \underbrace{(a_1 + a_2)(b_1 + b_2)}_{\sum a_i\sum b_i} = \underbrace{a_1b_1 + a_1b_2 + a_2b_1 + a_2b_2}_{\sum\mathbf{a} \otimes \mathbf{b}} ∑ a i ∑ b i ( a 1 + a 2 ) ( b 1 + b 2 ) = ∑ a ⊗ b a 1 b 1 + a 1 b 2 + a 2 b 1 + a 2 b 2
在图形上,这可以直观地理解为一个尺寸为 ( a 1 + a 2 ) × ( b 1 + b 2 ) (a_1 + a_2) \times (b_1 + b_2) ( a 1 + a 2 ) × ( b 1 + b 2 ) a 1 × b 1 + a 1 × b 2 + a 2 × b 1 + a 2 × b 2 a_1 \times b_1 + a_1 \times b_2 + a_2 \times b_1 + a_2 \times b_2 a 1 × b 1 + a 1 × b 2 + a 2 × b 1 + a 2 × b 2
a 1 + a 2 b 1 a 1 b 1 + a 1 b 2 + b 2 + a 2 b 1 + a 2 b 2 = a 1 a 2 b 1 a 1 b 1 a 2 b 1 b 2 a 1 b 2 a 2 b 2 \begin{array}{|c|cc|}
\hline
&a_1+a_2\\
\hline
b_1&a_1b_1 + a_1b_2\\
+b_2& + a_2b_1 + a_2b_2\\
\hline
\end{array}=
\begin{array}{|c|c|c|}
\hline
&a_1&a_2\\
\hline
b_1&a_1b_1&a_2b_1\\
\hline
b_2&a_1b_2&a_2b_2\\
\hline
\end{array} b 1 + b 2 a 1 + a 2 a 1 b 1 + a 1 b 2 + a 2 b 1 + a 2 b 2 = b 1 b 2 a 1 a 1 b 1 a 1 b 2 a 2 a 2 b 1 a 2 b 2
在我们的例子中,b \mathbf{b} b
( a 1 + a 2 ) ( G 1 + G 2 ) = a 1 G 1 + a 1 G 2 + a 2 G 1 + a 2 G 2 (a_1 + a_2)(G_1 + G_2) = a_1G_1 + a_1G_2 + a_2G_1 + a_2G_2 ( a 1 + a 2 ) ( G 1 + G 2 ) = a 1 G 1 + a 1 G 2 + a 2 G 1 + a 2 G 2
请注意,我们最初的 Pedersen 承诺
A = ⟨ [ a 1 , a 2 ] , [ G 1 , G 2 ] ⟩ = a 1 G 1 + a 2 G 2 A = \langle[a_1,a_2],[G_1,G_2]\rangle = a_1G_1 + a_2G_2 A = ⟨[ a 1 , a 2 ] , [ G 1 , G 2 ]⟩ = a 1 G 1 + a 2 G 2
被嵌入到了外积中带框的项里:
( a 1 + a 2 ) ( G 1 + G 2 ) = a 1 G 1 + a 1 G 2 + a 2 G 1 + a 2 G 2 (a_1 + a_2)(G_1 + G_2) = \boxed{a_1G_1} + a_1G_2 + a_2G_1 + \boxed{a_2G_2} ( a 1 + a 2 ) ( G 1 + G 2 ) = a 1 G 1 + a 1 G 2 + a 2 G 1 + a 2 G 2
因此,通过将向量各项的和相乘,我们也计算了外积的和。
既然内积是外积的对角线,我们就通过将向量各项的和相乘,间接地 计算了内积。为了证明我们知道内积,我们需要证明我们同样知道外积中不属于内积的那些项。
对于长度为 2 2 2 非对角乘积(off-diagonal product) 。
在下方,我们用 □ \square □ ■ \blacksquare ■
a 1 a 2 b 1 ■ □ b 2 □ ■ \begin{array}{|c|c|c|}
\hline
&a_1&a_2\\
\hline
b_1&\blacksquare&\square\\
\hline
b_2&\square&\blacksquare\\
\hline
\end{array} b 1 b 2 a 1 ■ □ a 2 □ ■
我们现在可以正式声明我们在后续将要依赖的恒等式。如果 n = 2 n=2 n = 2
∑ a ⊗ b = ⟨ a , b ⟩ + o f f _ d i a g o n a l ( a , b ) \sum\mathbf{a}\otimes\mathbf{b}=\langle\mathbf{a},\mathbf{b}\rangle+\mathsf{off\_diagonal}(\mathbf{a},\mathbf{b}) ∑ a ⊗ b = ⟨ a , b ⟩ + off_diagonal ( a , b ) 如果其中一个向量是椭圆曲线点的向量(即使它们的离散对数是未知的),这个恒等式同样成立。
对于 n > 2 n > 2 n > 2
在 n > 2 n > 2 n > 2
在 n = 2 n = 2 n = 2
洞见 3:如果 n = 1 n = 1 n = 1
一个重要的边缘情况是当我们有一个长度为 1 1 1 a \mathbf{a} a 1 1 1 a \mathbf{a} a G \mathbf{G} G
算法草图
现在,我们可以为 n = 2 n=2 n = 2 a \mathbf{a} a G \mathbf{G} G A A A
证明者与验证者之间的交互如下:
证明者将其承诺 A = a 1 G 1 + a 2 G 2 A = a_1G_1 + a_2G_2 A = a 1 G 1 + a 2 G 2
证明者将 a \mathbf{a} a a ′ = a 1 + a 2 a' = a_1 + a_2 a ′ = a 1 + a 2 a \mathbf{a} a a ′ a' a ′ a ⊗ G \mathbf{a} \otimes \mathbf{G} a ⊗ G R = a 2 G 1 R = a_2G_1 R = a 2 G 1 L = a 1 G 2 L = a_1G_2 L = a 1 G 2 L L L R R R
在图形上,L L L R R R
a 1 a 2 G 1 R G 2 L \begin{array}{|c|c|c|}
\hline
&a_1&a_2\\
\hline
G_1&&R\\
\hline
G_2&L&\\
\hline
\end{array} G 1 G 2 a 1 L a 2 R
验证者通过计算 a ′ G ′ a'G' a ′ G ′ G ′ = G 1 + G 2 G' = G_1 + G_2 G ′ = G 1 + G 2 a ⊗ G \mathbf{a} \otimes \mathbf{G} a ⊗ G
a ′ G ′ ⏟ 外积和 = A ⏟ 内积 + L + R ⏟ 非对角项 \underbrace{a'G'}_\text{外积和} = \underbrace{A}_\text{内积} + \underbrace{L + R}_\text{非对角项} 外积和 a ′ G ′ = 内积 A + 非对角项 L + R
展开形式下,上述方程为:
( a 1 + a 2 ) ( G 1 + G 2 ) ⏟ 外积 = a 1 G 1 + a 2 G 2 ⏟ 内积 + a 1 G 2 + a 2 G 1 ⏟ 非对角项 \underbrace{(a_1+a_2)(G_1+G_2)}_\text{外积} = \underbrace{a_1G_1 + a_2G_2}_\text{内积} + \underbrace{a_1G_2 + a_2G_1}_\text{非对角项} 外积 ( a 1 + a 2 ) ( G 1 + G 2 ) = 内积 a 1 G 1 + a 2 G 2 + 非对角项 a 1 G 2 + a 2 G 1 请注意,上述检查等价于早前给出的恒等式:
∑ a ⊗ G = ⟨ a , G ⟩ + o f f _ d i a g o n a l ( a , G ) \sum\mathbf{a}\otimes\mathbf{G}=\langle\mathbf{a},\mathbf{G}\rangle+\mathsf{off\_diagonal}(\mathbf{a},\mathbf{G}) ∑ a ⊗ G = ⟨ a , G ⟩ + off_diagonal ( a , G )
安全漏洞:多重打开(multiple openings)
然而,存在一个安全问题——证明者可以为同一个承诺找到多个证明。例如,证明者可以随机选择 L L L
R = a ′ G ′ − L R = a'G' - L R = a ′ G ′ − L
为了防止这种情况,我们重新借用在讨论零知识乘法时一个类似的想法——证明者必须在其计算中包含验证者提供的随机数 u u u u u u 之前 发送 L L L R R R L L L R R R
证明者之所以必须单独发送 L L L R R R L + R L + R L + R L L L R R R
L + R = a ′ G ′ L + R = a'G' L + R = a ′ G ′
证明者可以选择某个椭圆曲线点 S S S L ′ L' L ′ R ′ R' R ′
( L + S ) ⏟ L ′ + ( R − S ) ⏟ R ′ = a ′ G ′ \underbrace{(L + S)}_{L'} + \underbrace{(R - S)}_{R'} = a'G' L ′ ( L + S ) + R ′ ( R − S ) = a ′ G ′
我们需要强制证明者保持 L L L R R R
这是修正此漏洞后的更新算法:
证明者和验证者商定一个基向量 [ G 1 , G 2 ] [G_1, G_2] [ G 1 , G 2 ]
证明者计算并向验证者发送 ( A , L , R ) (A, L, R) ( A , L , R )
A = a 1 G 1 + a 2 G 2 // 我们要证明其知识的向量承诺 L = a 1 G 2 // 左侧对角项 R = a 2 G 1 // 右侧对角项 \begin{align*}
A &= a_1G_1 + a_2G_2 && \text{// 我们要证明其知识的向量承诺}\\
L &= a_1G_2 && \text{// 左侧对角项}\\
R &= a_2G_1 && \text{// 右侧对角项}\\
\end{align*} A L R = a 1 G 1 + a 2 G 2 = a 1 G 2 = a 2 G 1 // 我们要证明其知识的向量承诺 // 左侧对角项 // 右侧对角项
验证者回复一个随机标量 u u u
证明者计算并发送 a ′ a' a ′
a ′ = a 1 + a 2 u a' = a_1 + a_2u a ′ = a 1 + a 2 u
验证者现在拥有了 ( A , L , R , a ′ , u ) (A, L, R, a', u) ( A , L , R , a ′ , u ) L + u A + u 2 R = ? a ′ ( u G 1 + G 2 ) L + u A + u^2R \stackrel{?}= a'(u G_1 + G_2) L + u A + u 2 R = ? a ′ ( u G 1 + G 2 )
其背后的底层展开是:
a 1 G 2 ⏟ L + u ( a 1 G 1 + a 2 G 2 ) ⏟ u A + a 2 u G 1 ⏟ u 2 R = ( a 1 + u a 2 ) ⏟ a ′ ( u G 1 + G 2 ) \underbrace{a_1G_2}_L + \underbrace{u(a_1G_1 + a_2G_2)}_{uA} + \underbrace{a_2u G_1}_{u^2R} = \underbrace{(a_1 + u a_2)}_{a'}(u G_1 + G_2) L a 1 G 2 + u A u ( a 1 G 1 + a 2 G 2 ) + u 2 R a 2 u G 1 = a ′ ( a 1 + u a 2 ) ( u G 1 + G 2 ) 如果证明者正确计算了 a ′ a' a ′ L L L R R R
请注意,验证者将 u u u G 2 G_2 G 2 u u u a 1 a_1 a 1
由于 L L L R R R u 2 u^2 u 2 R R R L L L u 2 u^2 u 2 u u u L L L R R R
算法的另一种解释:将 n n n
验证者只进行了一次乘法,即 a ′ a' a ′ ( u G 1 + G 2 ) (uG_1 + G_2) ( u G 1 + G 2 ) 2 2 2 n / 2 = 1 n/2=1 n /2 = 1
a 1 + a 2 u a_1 + a_2u a 1 + a 2 u 2 2 2 a \mathbf{a} a 1 1 1 u u u 1 1 1
因为他们都已将原始向量压缩为一个长度为 1 1 1 n = 1 n = 1 n = 1 ⟨ a ′ , G ′ ⟩ = a ′ ⊗ G ′ \langle\mathbf{a}',\mathbf{G}'\rangle=\mathbf{a}'\otimes\mathbf{G}' ⟨ a ′ , G ′ ⟩ = a ′ ⊗ G ′ a ′ = a 1 + a 2 u \mathbf{a}' = a_1 + a_2u a ′ = a 1 + a 2 u G ′ = G 1 u + G 2 \mathbf{G'} = G_1u + G_2 G ′ = G 1 u + G 2
算法的安全性
算法总结
作为对该算法的快速总结,
证明者向验证者发送 ( A , L , R ) (A, L, R) ( A , L , R )
验证者回复 u u u
证明者计算并发送 a ′ a' a ′
验证者检查:
L + u A + u 2 R = ? a ′ ( u G 1 + G 2 ) L + uA + u^2R \stackrel{?}= a'(uG_1 + G_2) L + u A + u 2 R = ? a ′ ( u G 1 + G 2 )
现在让我们看看为什么证明者无法作弊。
在步骤 3 中,证明者拥有的唯一“自由度”是 a ′ a' a ′
要想给出一个满足
L + u A + u 2 R = a ′ ( u G 1 + G 2 ) L + uA + u^2R = a'(uG_1 + G_2) L + u A + u 2 R = a ′ ( u G 1 + G 2 )
的 a ′ a' a ′ G 1 G_1 G 1 G 2 G_2 G 2
a ′ = l + u a + u 2 r u g 1 + g 2 a'=\frac{l + ua + u^2r}{ug_1 + g_2} a ′ = u g 1 + g 2 l + u a + u 2 r
其中
l l l r r r L L L R R R g 1 g_1 g 1 g 2 g_2 g 2 G 1 G_1 G 1 G 2 G_2 G 2 a a a A A A l l l r r r L L L R R R
然而,证明者并不知道离散对数 g 1 g_1 g 1 g 2 g_2 g 2 a ′ a' a ′
变量 a ′ a' a ′
对于满足 L + u A + u 2 R = a ′ ( u G 1 + G 2 ) L + uA + u^2R = a'(uG_1 + G_2) L + u A + u 2 R = a ′ ( u G 1 + G 2 ) a ′ a' a ′ L + u A + u 2 R L + uA + u^2R L + u A + u 2 R u u u a ′ ( u G 1 + G 2 ) a'(uG_1+G_2) a ′ ( u G 1 + G 2 ) Schwartz-Zippel Lemma (Schwartz-Zippel 引理),该方程最多有两个解。只要域的阶(order) ≫ 2 \gg 2 ≫ 2 L + u A + u 2 R = a ′ ( u G 1 + G 2 ) L + uA + u^2R = a'(uG_1 + G_2) L + u A + u 2 R = a ′ ( u G 1 + G 2 ) a ′ a' a ′
Bulletproofs 论文中注入随机数的方法
在 Bulletproofs 论文中,证明者并不是将 a 1 a_1 a 1 a 2 a_2 a 2 a 1 + a 2 u a_1 + a_2u a 1 + a 2 u a ′ = a 1 u + a 2 u − 1 a' = a_1u + a_2u^{-1} a ′ = a 1 u + a 2 u − 1 G ′ = u − 1 G 1 + u G 2 G' = u^{-1}G_1 + u G_2 G ′ = u − 1 G 1 + u G 2 u u − 1 uu^{-1} u u − 1
[ a 1 u , u − 1 a 2 ] ⊗ [ u − 1 G 1 , u G 2 ] = u a 1 u − 1 a 2 G 1 u − 1 a 1 G 1 a 1 G 2 u 2 G 2 u a 2 G 1 u − 2 a 2 G 2 [a_1u, u^{-1}a_2] \otimes [u^{-1}G_1, uG_2]=
\begin{array}{|c| c c|}
\hline
& ua_1 & u^{-1}a_2 \\
\hline
G_1u^{-1} & \color{green}{a_1G_1} & a_1G_2u^2 \\
G_2u & a_2G_1u^{-2} & \color{green}{a_2G_2} \\
\hline
\end{array} [ a 1 u , u − 1 a 2 ] ⊗ [ u − 1 G 1 , u G 2 ] = G 1 u − 1 G 2 u u a 1 a 1 G 1 a 2 G 1 u − 2 u − 1 a 2 a 1 G 2 u 2 a 2 G 2
可以说,这种方法“更干净”,所以我们将在后续采用这种方法。
引入 f o l d ( a , x ) \mathsf{fold}(\mathbf{a},x) fold ( a , x )
a 1 x + a 2 x − 1 a_1x + a_2x^{-1} a 1 x + a 2 x − 1 f o l d ( a , x ) \mathsf{fold}(\mathbf{a},x) fold ( a , x ) a \mathbf{a} a 0 0 0 n n n a \mathbf{a} a n / 2 n/2 n /2 n / 2 n/2 n /2
f o l d ( a , x ) = [ a 1 x + a 2 x − 1 , a 3 x + a 4 x − 1 , … , a n − 1 x + a n x − 1 ] \mathsf{fold}(\mathbf{a}, x)=[a_1x+a_2x^{-1},a_3x+a_4x^{-1},\dots,a_{n-1}x+a_nx^{-1}] fold ( a , x ) = [ a 1 x + a 2 x − 1 , a 3 x + a 4 x − 1 , … , a n − 1 x + a n x − 1 ]
如果我们执行 f o l d ( a , x − 1 ) \mathsf{fold}(\mathbf{a},x^{-1}) fold ( a , x − 1 )
f o l d ( a , x − 1 ) = [ a 1 x − 1 + a 2 x , a 3 x − 1 + a 4 x , … , a n − 1 x − 1 + a n x ] \mathsf{fold}(\mathbf{a}, x^{-1})=[a_1x^{-1}+a_2x,a_3x^{-1}+a_4x,\dots,a_{n-1}x^{-1}+a_nx] fold ( a , x − 1 ) = [ a 1 x − 1 + a 2 x , a 3 x − 1 + a 4 x , … , a n − 1 x − 1 + a n x ]
当 n = 2 n=2 n = 2 f o l d ( a , x ) \mathsf{fold}(\mathbf{a},x) fold ( a , x ) a 1 x + a 2 x − 1 a_1x+a_2x^{-1} a 1 x + a 2 x − 1 f o l d ( a , x − 1 ) = a 1 x − 1 + a 2 x \mathsf{fold}(\mathbf{a},x^{-1})=a_1x^{-1}+a_2x fold ( a , x − 1 ) = a 1 x − 1 + a 2 x
带有 f o l d \mathsf{fold} fold
我们现在使用 Bulletproofs 论文中处理随机数的方法重新陈述该算法:
证明者向验证者发送他们对 a \mathbf{a} a A = a 1 G 1 + a 2 G 2 A = a_1G_1 + a_2G_2 A = a 1 G 1 + a 2 G 2 L L L R R R L = a 1 G 2 R = a 2 G 1 \begin{align*}
L &= a_1G_2 \\
R &= a_2G_1 \\
\end{align*} L R = a 1 G 2 = a 2 G 1
验证者回复一个随机标量 u u u
证明者计算并发送 a ′ a' a ′ a ′ = f o l d ( a , u ) = a 1 u + a 2 u − 1 a' = \mathsf{fold}(\mathbf{a},u) = a_1u + a_2u^{-1} a ′ = fold ( a , u ) = a 1 u + a 2 u − 1
验证者计算:P = a ′ ⋅ f o l d ( G , u − 1 ) = a ′ ⋅ ( u − 1 G 1 + u G 2 ) P = ? L u 2 + A + u − 2 R \begin{align*}
P &= a'\cdot\mathsf{fold}(\mathbf{G},u^{-1})= a'\cdot(u^{-1} G_1 + uG_2)\\
P &\stackrel{?} = Lu^2 + A + u^{-2}R
\end{align*} P P = a ′ ⋅ fold ( G , u − 1 ) = a ′ ⋅ ( u − 1 G 1 + u G 2 ) = ? L u 2 + A + u − 2 R
假设证明者是诚实的,最后的检查底层可展开为:
( a 1 G 2 ) u 2 + ( a 1 G 1 + a 2 G 2 ) + u − 2 ( a 2 G 1 ) = ( a 1 u + a 2 u − 1 ) ( u − 1 G 1 + u G 2 ) ( a 1 G 2 ) u 2 + ( a 1 G 1 + a 2 G 2 ) + u − 2 ( a 2 G 1 ) = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 a 1 u 2 G 2 + a 1 G 1 + a 2 G 2 + a 2 u − 2 G 1 = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 \begin{align*}
(a_1G_2)u^2 + (a_1G_1 + a_2G_2) + u^{-2}(a_2G_1) &= (a_1u + a_2u^{-1})(u^{-1} G_1 + uG_2)\\
(a_1G_2)u^2 + (a_1G_1 + a_2G_2) + u^{-2}(a_2G_1) &=a_1G_1+a_1u^2G_2+a_2u^{-2}G_1+a_2G_2\\
a_1u^2G_2 + a_1G_1 + a_2G_2 + a_2u^{-2}G_1 &=a_1G_1+a_1u^2G_2+a_2u^{-2}G_1+a_2G_2\\
a_1G_1 + a_1u^2G_2 + a_2u^{-2}G_1 + a_2G_2 &=a_1G_1+a_1u^2G_2+a_2u^{-2}G_1+a_2G_2\\
\end{align*} ( a 1 G 2 ) u 2 + ( a 1 G 1 + a 2 G 2 ) + u − 2 ( a 2 G 1 ) ( a 1 G 2 ) u 2 + ( a 1 G 1 + a 2 G 2 ) + u − 2 ( a 2 G 1 ) a 1 u 2 G 2 + a 1 G 1 + a 2 G 2 + a 2 u − 2 G 1 a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 = ( a 1 u + a 2 u − 1 ) ( u − 1 G 1 + u G 2 ) = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2 = a 1 G 1 + a 1 u 2 G 2 + a 2 u − 2 G 1 + a 2 G 2
如何处理 n > 2 n > 2 n > 2
假设数组 a \mathbf{a} a
a = [ a 1 , a 2 , a 3 , a 4 , a 5 , a 6 , a 7 , a 8 ] = [ a 1 , a 2 ] [ a 3 , a 4 ] [ a 5 , a 6 ] [ a 7 , a 8 ] \mathbf{a} = [a_1, a_2, a_3, a_4, a_5, a_6, a_7, a_8]=[a_1, a_2] [a_3, a_4] [a_5, a_6] [a_7, a_8] a = [ a 1 , a 2 , a 3 , a 4 , a 5 , a 6 , a 7 , a 8 ] = [ a 1 , a 2 ] [ a 3 , a 4 ] [ a 5 , a 6 ] [ a 7 , a 8 ]
类似地,我们也可以对 G \mathbf{G} G
G = [ G 1 , G 2 , G 3 , G 4 , G 5 , G 6 , G 7 , G 8 ] = [ G 1 , G 2 ] [ G 3 , G 4 ] [ G 5 , G 6 ] [ G 7 , G 8 ] \mathbf{G} = [G_1, G_2, G_3, G_4, G_5, G_6, G_7, G_8]=[G_1, G_2] [G_3, G_4] [G_5, G_6] [G_7, G_8] G = [ G 1 , G 2 , G 3 , G 4 , G 5 , G 6 , G 7 , G 8 ] = [ G 1 , G 2 ] [ G 3 , G 4 ] [ G 5 , G 6 ] [ G 7 , G 8 ]
然后,每个子对都可以视为计算内积的一个实例,直接使用前面讲过的 n = 2 n=2 n = 2
接着,我们可以证明我们知道这四个 n = 2 n=2 n = 2 a 1 G 1 + a 2 G 2 a_1G_1 + a_2G_2 a 1 G 1 + a 2 G 2 a 3 G 3 + a 4 G 4 a_3G_3 + a_4G_4 a 3 G 3 + a 4 G 4 a 5 G 5 + a 6 G 6 a_5G_5 + a_6G_6 a 5 G 5 + a 6 G 6 a 7 G 7 + a 8 G 8 a_7G_7 + a_8G_8 a 7 G 7 + a 8 G 8
然而,这会为我们所证明的每个对额外产生四组 ( L , R ) (L, R) ( L , R )
一种朴素的解决方案是证明者承诺并发送:
A 1 = a 1 G 1 + a 2 G 2 A 2 = a 3 G 3 + a 4 G 4 A 3 = a 5 G 5 + a 6 G 6 A 4 = a 7 G 7 + a 8 G 8 L 1 = a 1 G 2 R 1 = a 2 G 1 L 2 = a 3 G 4 R 2 = a 4 G 3 L 3 = a 5 G 6 R 3 = a 6 G 5 L 4 = a 7 G 8 R 4 = a 8 G 7 \begin{align*}
A_1 &= a_1G_1+a_2G_2\\
A_2 &= a_3G_3+a_4G_4\\
A_3 &= a_5G_5+a_6G_6\\
A_4 &= a_7G_7+a_8G_8\\
L_1 &= a_1G_2\\
R_1 &= a_2G_1\\
L_2 &= a_3G_4\\
R_2 &= a_4G_3\\
L_3 &= a_5G_6\\
R_3 &= a_6G_5\\
L_4 &= a_7G_8\\
R_4 &= a_8G_7\\
\end{align*} A 1 A 2 A 3 A 4 L 1 R 1 L 2 R 2 L 3 R 3 L 4 R 4 = a 1 G 1 + a 2 G 2 = a 3 G 3 + a 4 G 4 = a 5 G 5 + a 6 G 6 = a 7 G 7 + a 8 G 8 = a 1 G 2 = a 2 G 1 = a 3 G 4 = a 4 G 3 = a 5 G 6 = a 6 G 5 = a 7 G 8 = a 8 G 7
在图形上,这可以表示如下:
a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 G 1 R 1 G 2 L 1 G 3 R 2 G 4 L 2 G 5 R 3 G 6 L 3 G 7 R 4 G 8 L 4 \begin{array}{c|c|}
&a_1 & a_2 & a_3 & a_4 & a_5 & a_6 & a_7 & a_8\\
\hline
G_1&&R_1\\
\hline
G_2&L_1\\
\hline
G_3&&&&R_2\\
\hline
G_4&&&L_2\\
\hline
G_5&&&&&&R_3\\
\hline
G_6&&&&&L_3\\
\hline
G_7&&&&&&&&R_4\\
\hline
G_8&&&&&&&L_4\\
\hline
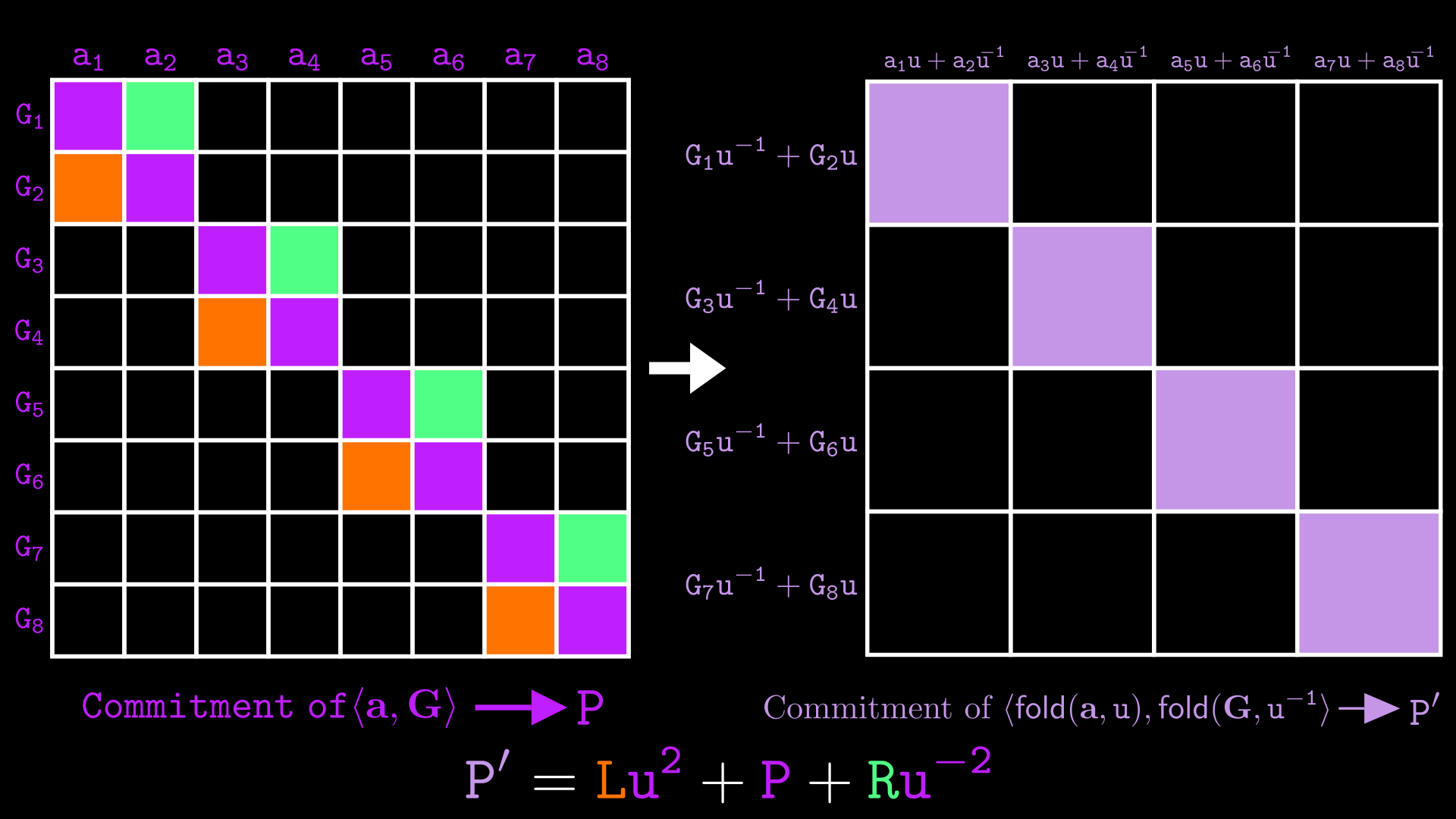
\end{array} G 1 G 2 G 3 G 4 G 5 G 6 G 7 G 8 a 1 L 1 a 2 R 1 a 3 L 2 a 4 R 2 a 5 L 3 a 6 R 3 a 7 L 4 a 8 R 4 作为一个(关键的!)优化,我们将每一对中的所有 A i A_i A i L i L_i L i R i R_i R i A A A L L L R R R
A = A 1 + A 2 + A 3 + A 4 L = L 1 + L 2 + L 3 + L 4 R = R 1 + R 2 + R 3 + R 4 \begin{align*}
A &= A_1 + A_2 + A_3 + A_4\\
L &= L_1 + L_2 + L_3 + L_4\\
R &= R_1 + R_2 + R_3 + R_4\\
\end{align*} A L R = A 1 + A 2 + A 3 + A 4 = L 1 + L 2 + L 3 + L 4 = R 1 + R 2 + R 3 + R 4
上述操作如下方动画所示:
将所有承诺和非对角项加在一起的安全性
对于这种优化,最初的担忧是:由于证明者将更多的项加在了一起,就有了更多的机会来隐藏不诚实的计算。
现在我们来证明:一旦证明者发送了 A A A L L L R R R A A A
观察到 L L L L = a 1 G 2 + a 3 G 4 + a 5 G 6 + a 7 G 8 L = a_1G_2 + a_3G_4 +a_5G_6+a_7G_8 L = a 1 G 2 + a 3 G 4 + a 5 G 6 + a 7 G 8 R R R R = a 2 G 1 + a 4 G 3 + a 6 G 5 + a 8 G 7 R = a_2G_1 + a_4G_3 +a_6G_5+a_8G_7 R = a 2 G 1 + a 4 G 3 + a 6 G 5 + a 8 G 7 L L L R R R L L L [ G 1 , G 3 , G 5 , G 7 ] [G_1, G_3, G_5, G_7] [ G 1 , G 3 , G 5 , G 7 ] [ a 2 , a 4 , a 6 , a 8 ] [a_2, a_4, a_6, a_8] [ a 2 , a 4 , a 6 , a 8 ] [ a 2 , a 4 , a 6 , a 8 ] [a_2, a_4, a_6, a_8] [ a 2 , a 4 , a 6 , a 8 ] R R R
A A A [ a 1 , a 2 ] [a_1, a_2] [ a 1 , a 2 ] [ a 3 , a 4 ] [a_3, a_4] [ a 3 , a 4 ] [ a 5 , a 6 ] [a_5, a_6] [ a 5 , a 6 ] [ a 7 , a 8 ] [a_7, a_8] [ a 7 , a 8 ] A A A n = 8 n = 8 n = 8
a 1 G 1 + a 2 G 2 + a 3 G 3 + a 4 G 4 + a 5 G 5 + a 6 G 6 + a 7 G 7 + a 8 G 8 = ( a 1 G 1 + a 2 G 2 ) + ( a 3 G 3 + a 4 G 4 ) + ( a 5 G 5 + a 6 G 6 ) + ( a 7 G 7 + a 8 G 8 ) \begin{align*}
&\space a_1G_1 + a_2G_2\space + \space a_3G_3 + a_4G_4\space\space + \space\space a_5G_5 + a_6G_6\space + \space a_7G_7 + a_8G_8\\
=&(a_1G_1 + a_2G_2) + (a_3G_3 + a_4G_4) + (a_5G_5 + a_6G_6) + (a_7G_7 + a_8G_8)\end{align*} = a 1 G 1 + a 2 G 2 + a 3 G 3 + a 4 G 4 + a 5 G 5 + a 6 G 6 + a 7 G 7 + a 8 G 8 ( a 1 G 1 + a 2 G 2 ) + ( a 3 G 3 + a 4 G 4 ) + ( a 5 G 5 + a 6 G 6 ) + ( a 7 G 7 + a 8 G 8 )
例如,证明者可能会将数值从 a 1 G 1 a_1G_1 a 1 G 1 a 2 G 1 a_2G_1 a 2 G 1
剩下的唯一担忧是,证明者可能会将数值从 A A A a 1 G 1 a_1G_1 a 1 G 1 L L L a 2 G 1 a_2G_1 a 2 G 1 u u u
因此,一旦证明者发送了以本节所描述方式计算的 ( A , L , R ) (A, L, R) ( A , L , R )
证明我们知道 A A A n / 2 n/2 n /2
证明者向验证者发送 A = ⟨ a , G ⟩ A = \langle\mathbf{a},\mathbf{G}\rangle A = ⟨ a , G ⟩ L = a 1 G 2 + a 3 G 4 + . . . a n − 1 G n L = a_1G_2 + a_3G_4 + ... a_{n-1}G_n L = a 1 G 2 + a 3 G 4 + ... a n − 1 G n R = a 2 G 1 + a 4 G 3 + . . . + a n G n − 1 R = a_2G_1 + a_4G_3 + ... + a_nG_{n-1} R = a 2 G 1 + a 4 G 3 + ... + a n G n − 1
验证者发送一个随机数 u u u
证明者计算 a ′ = f o l d ( a , u ) \mathbf{a}'=\mathsf{fold}(\mathbf{a},u) a ′ = fold ( a , u ) a ′ \mathbf{a}' a ′
验证者检查 L u 2 + A + R u − 2 = ? ⟨ a ′ , f o l d ( G , u − 1 ) ⟩ Lu^2 + A + Ru^{-2} \stackrel{?}=\langle\mathbf{a}',\mathsf{fold}(\mathbf{G},u^{-1})\rangle L u 2 + A + R u − 2 = ? ⟨ a ′ , fold ( G , u − 1 )⟩
我们将其作为一个练习留给读者:推导一个例子来检验在证明者诚实的情况下,最终的验证检查在代数上是否等价。我们建议使用一个小的例子,例如 n = 4 n=4 n = 4
对 f o l d \mathsf{fold} fold
P P P a \mathbf{a} a G \mathbf{G} G L L L R R R
总和 L u 2 + P + R u − 2 Lu^2 + P + Ru^{-2} L u 2 + P + R u − 2 f o l d ( a , u ) \mathsf{fold}(\mathbf{a},u) fold ( a , u ) f o l d ( G , u − 1 ) \mathsf{fold}(\mathbf{G}, u^{-1}) fold ( G , u − 1 ) n / 2 n/2 n /2
我们在下面以图形方式展示这一关系:
要证明我们知道一个大小为 n / 2 n/2 n /2 n / 2 n/2 n /2 f o l d ( a , u ) \mathsf{fold}(\mathbf{a},u) fold ( a , u )
使用这种解释,该算法正在执行以下操作:
证明者发送 A = ⟨ a , G ⟩ A = \langle\mathbf{a},\mathbf{G}\rangle A = ⟨ a , G ⟩ L L L R R R
验证者发送 u u u
现在验证者拥有了一个相对基向量 f o l d ( G , u − 1 ) \mathsf{fold}(\mathbf{G},u^{-1}) fold ( G , u − 1 ) A ′ = L u 2 + A + R u − 2 A' = Lu^2 + A + Ru^{-2} A ′ = L u 2 + A + R u − 2
证明者通过发送 a ′ = f o l d ( a , u ) \mathbf{a}' =\mathsf{fold}(\mathbf{a}, u) a ′ = fold ( a , u ) A ′ A' A ′
验证速度的限制
因为验证者需要计算 f o l d ( G , u − 1 ) \mathsf{fold}(\mathbf{G}, u^{-1}) fold ( G , u − 1 ) G \mathbf{G} G O ( n ) \mathcal{O}(n) O ( n )
总结
我们展示了证明者如何能够在仅发送 n / 2 n/2 n /2 a \mathbf{a} a A A A
在下一章中,我们将展示如何递归地应用这个算法,从而使证明者仅需发送 O ( log n ) \mathcal{O}(\log n) O ( log n )
练习: 实现本章描述的算法。使用以下代码作为起点:
Copy from py_ecc.bn128 import G1, multiply, add, FQ , eq, Z1 from py_ecc.bn128 import curve_order as p import numpy as np from functools import reduce import random def random_element (): return random.randint( 0 , p) def add_points ( * points): return reduce (add, points, Z1) # if points = G1, G2, G3, G4 and scalars = a,b,c,d vector_commit returns # aG1 + bG2 + cG3 + dG4 def vector_commit (points, scalars): return reduce (add, [multiply(P, i) for P, i in zip (points, scalars)], Z1) # these EC points have unknown discrete logs: G_vec = [(FQ( 6286155310766333871795042970372566906087502116590250812133967451320632869759 ), FQ( 2167390362195738854837661032213065766665495464946848931705307210578191331138 )), (FQ( 6981010364086016896956769942642952706715308592529989685498391604818592148727 ), FQ( 8391728260743032188974275148610213338920590040698592463908691408719331517047 )), (FQ( 15884001095869889564203381122824453959747209506336645297496580404216889561240 ), FQ( 14397810633193722880623034635043699457129665948506123809325193598213289127838 )), (FQ( 6756792584920245352684519836070422133746350830019496743562729072905353421352 ), FQ( 3439606165356845334365677247963536173939840949797525638557303009070611741415 ))] # return a folded vector of length n/2 for scalars def fold (scalar_vec, u): pass # your code here # return a folded vector of length n/2 for points def fold_points (point_vec, u): pass # your code here # return L, R as a tuple def compute_secondary_diagonal (G_vec, a): pass # your code here a = [ 9 , 45 , 23 , 42 ] # prover commits A = vector_commit(G_vec, a) L, R = compute_secondary_diagonal(G_vec, a) # verifier computes randomness u = random_element() # prover computes fold(a) aprime = fold(a, u) # verifier computes fold(G) Gprime = fold_points(G_vec, pow (u, - 1 , p)) # verification check assert eq(vector_commit(Gprime, aprime), add_points(multiply(L, pow (u, 2 , p)), A, multiply(R, pow (u, - 2 , p)))), "invalid proof" assert len (Gprime) == len (a) // 2 and len (aprime) == len (a) // 2 , "proof must be size n/2"