Solidity 中的动态大小类型(有时称为复杂类型)是具有可变大小的数据类型。它们包括 mappings(映射)、嵌套 mappings、arrays(数组)、嵌套 arrays、strings(字符串)、bytes(字节),以及包含这些类型中任何一种的 structs(结构体)。本文将展示它们是如何被编码并保存在 storage 中的。
Mappings
Mappings 用于以键值对的形式存储数据。
下面的彩色键值将在接下来的代码块中被引用:
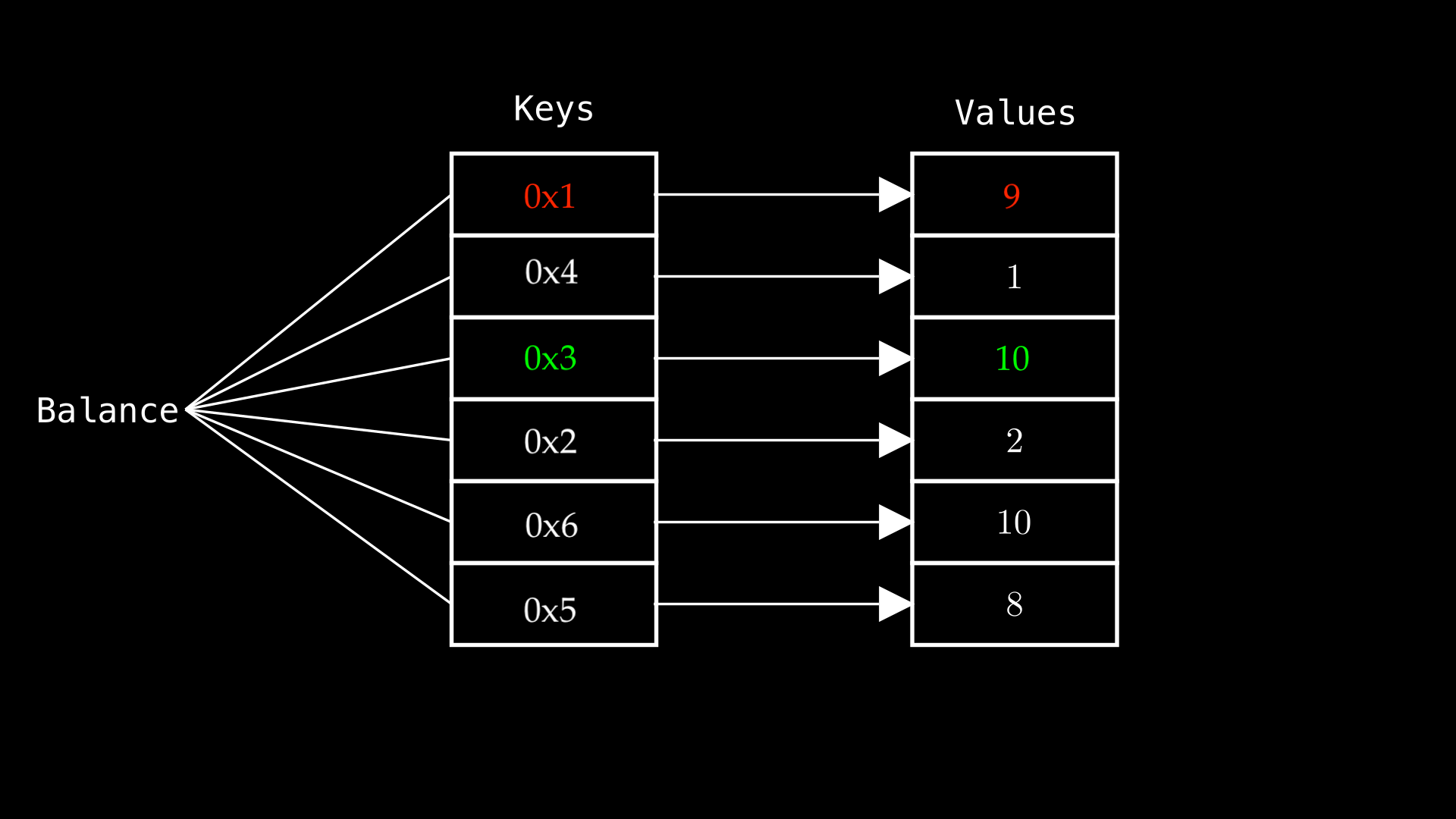
考虑以下示例,该示例使用 mappings 将 Ethereum 地址与某个值关联起来。如上图所示,红色和绿色的键值在下面的代码中被设置:
// SPDX-License-Identifier: MIT
pragma solidity =0.8.26;
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9; // RED
balance[address(0x03)] = 10; // GREEN
}
}
函数 setValues 将地址 0x01 和 0x03 分别映射为 9 和 10,并将它们存储在映射变量 balance 中。使用 Solidity 获取分配给 address(0x01) 的值非常简单。但是它使用的是哪个存储槽?我们如何使用 assembly(汇编)来访问它呢?
Mappings 的存储槽
要计算该值的存储槽,我们采取以下步骤:
- 将与值关联的键和映射变量的存储槽(base slot)拼接在一起。
- 对拼接的结果进行哈希处理。
上述步骤的公式
其中 表示拼接
下面的动画展示了上述公式中的数据是如何布局的:
在底层,键和 base slot 均作为 256 位(32 字节)的值存储。当它们拼接在一起时,就是一个 64 字节的值。
下面的动画展示了这些值(键和 base slot)是如何拼接的。使用的值为:
- address key =
0x504DbB5Dc821445b142312b74693d778a1B60b2f - uint256 baseSlot =
6
请注意,键和 base slot 的值在拼接之前是如何首先被零填充为 32 字节值的。拼接的结果(64 字节数组)就是被哈希处理以确定存储槽的内容。
计算 Mapping 存储槽
现在我们已经了解了如何计算键和 base slot 来获取 mapping 的存储槽,接下来我们准备看看在 Solidity 中如何手动完成这一操作。
记住,我们需要两个值来计算 mapping 的槽(键和 base slot)。实现这一目的的代码在 getStorageSlot() 函数中:
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9; // RED
balance[address(0x03)] = 10; // GREEN
}
//*** NEWLY ADDED FUNCTION ***//
function getStorageSlot(address _key) public pure returns (bytes32 slot) {
uint256 balanceMappingSlot;
assembly {
// `.slot` returns the state variable (balance) location within the storage slots.
// In our case, balance.slot = 0
balanceMappingSlot := balance.slot
}
slot = keccak256(abi.encode(_key, balanceMappingSlot));
}
}
getStorageSlot 函数接收 _key 作为参数,并使用一个 assembly 块来获取 balance 变量的 base slot(balanceMappingSlot)。然后它使用 abi.encode 将每个值填充为 32 字节并拼接它们,接着使用 keccak256 对拼接后的值进行哈希处理,以生成存储槽。
为了测试这一点,让我们以 address(0x01) 作为参数调用该函数,因为我们已经在 setValues 函数中为与此 _key 关联的存储槽分配了一个值。
调用后返回的槽:0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d
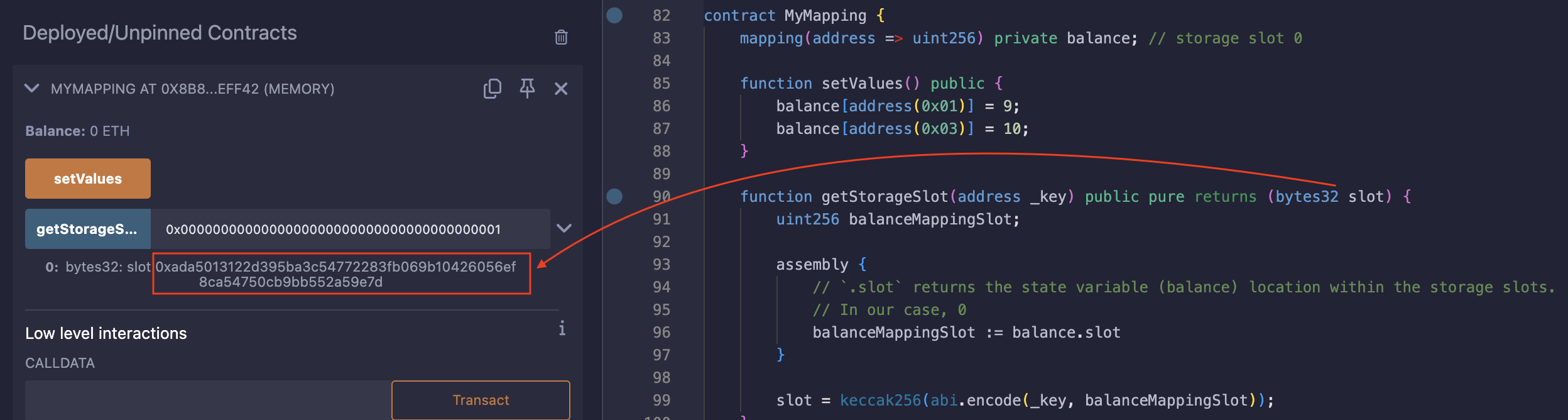
接下来,我们创建一个 getValue() 函数,它将加载我们计算出的存储槽。该函数旨在证明 getStorageSlot() 计算出的槽确实是保存该值的正确存储槽。
function getValue(address _key) public view returns (uint256 value) {
// CALL HELPER FUNCTION TO GET SLOT
bytes32 slot = getStorageSlot(_key);
assembly {
// Loads the value stored in the slot
value := sload(slot)
}
}
以 address(1) 为参数调用 getValue 函数返回了 9,这是分配给 address(1) 键的正确值:
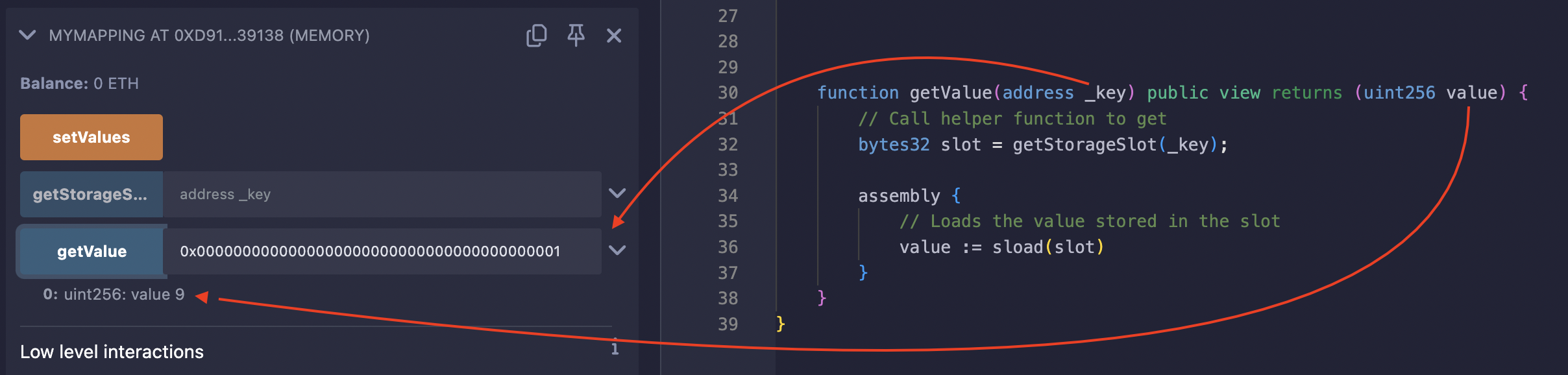
这里是供你在 Remix 上测试的完整代码。
// SPDX-License-Identifier: MIT
pragma solidity =0.8.26;
contract MyMapping {
mapping(address => uint256) private balance; // storage slot 0
function setValues() public {
balance[address(0x01)] = 9;
balance[address(0x03)] = 10;
}
function getStorageSlot(address _key) public pure returns (bytes32 slot) {
uint256 balanceMappingSlot;
assembly {
// `.slot` returns the state variable (balance) location within the storage slots.
// In our case, 0
balanceMappingSlot := balance.slot
}
slot = keccak256(abi.encode(_key, balanceMappingSlot));
}
function getValue(address _key) public view returns (uint256 value) {
// Call helper function to get
bytes32 slot = getStorageSlot(_key);
assembly {
// Loads the value stored in the slot
value := sload(slot)
}
}
}
嵌套 Mappings
嵌套 mapping 是指在另一个 mapping 内部的 mapping。一个常见的用例是存储特定地址的不同代币余额,如下图所示。
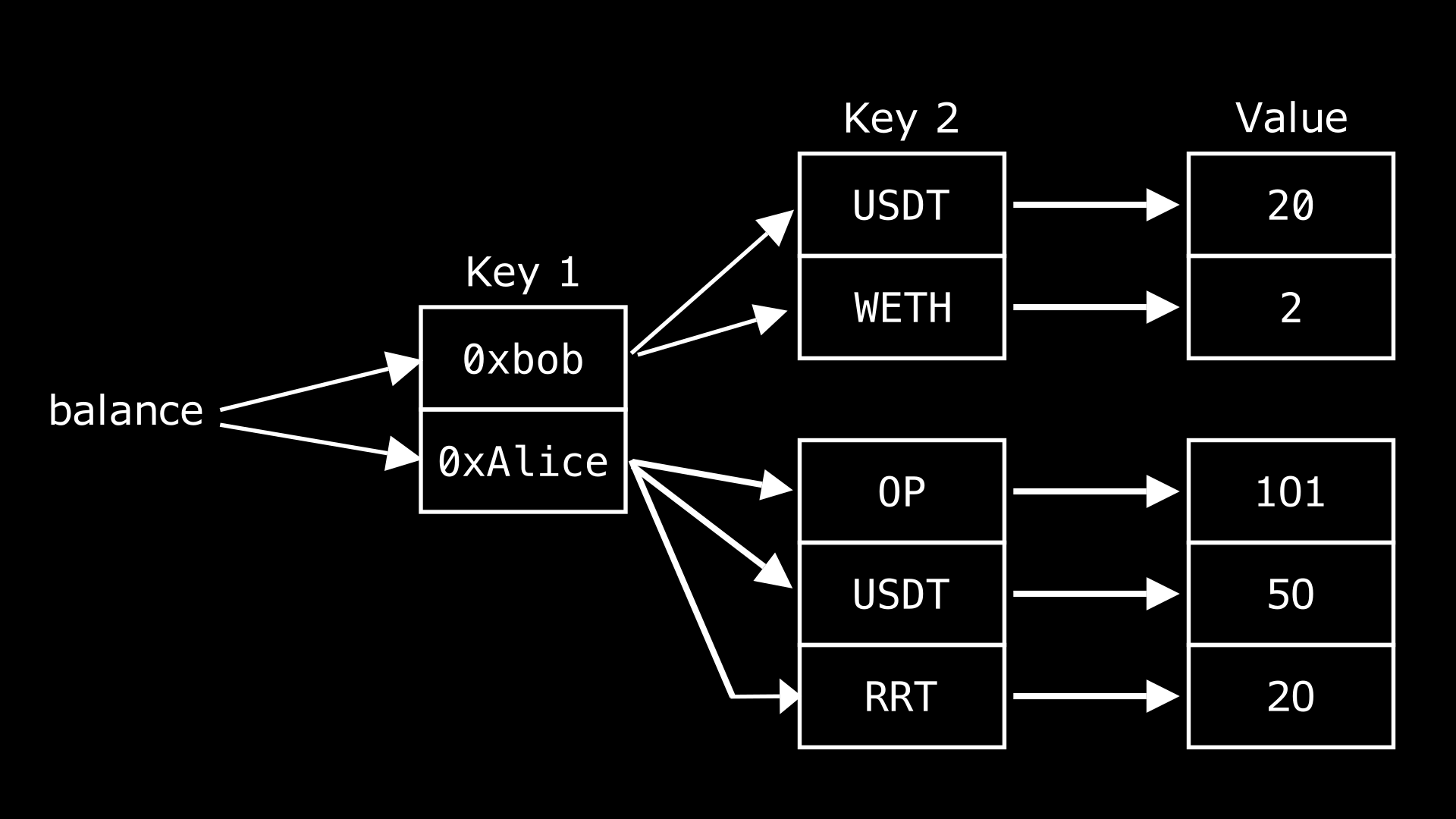
这表明 balance 变量包含两个不同的地址 0xbob 和 0xAlice,这些地址中的每一个都与多个代币关联,进而映射到不同的余额,因此称为嵌套 mappings。
嵌套 Mappings 的存储槽
嵌套 mappings 的存储槽计算与单一 mappings 类似,区别在于 mapping 的“层级”对应于哈希操作的次数。下面是一个动画和代码示例,展示了具有两次哈希操作的双层 mappings:
现在让我们展示一个使用 assembly 从 storage 中获取嵌套数组值的代码示例
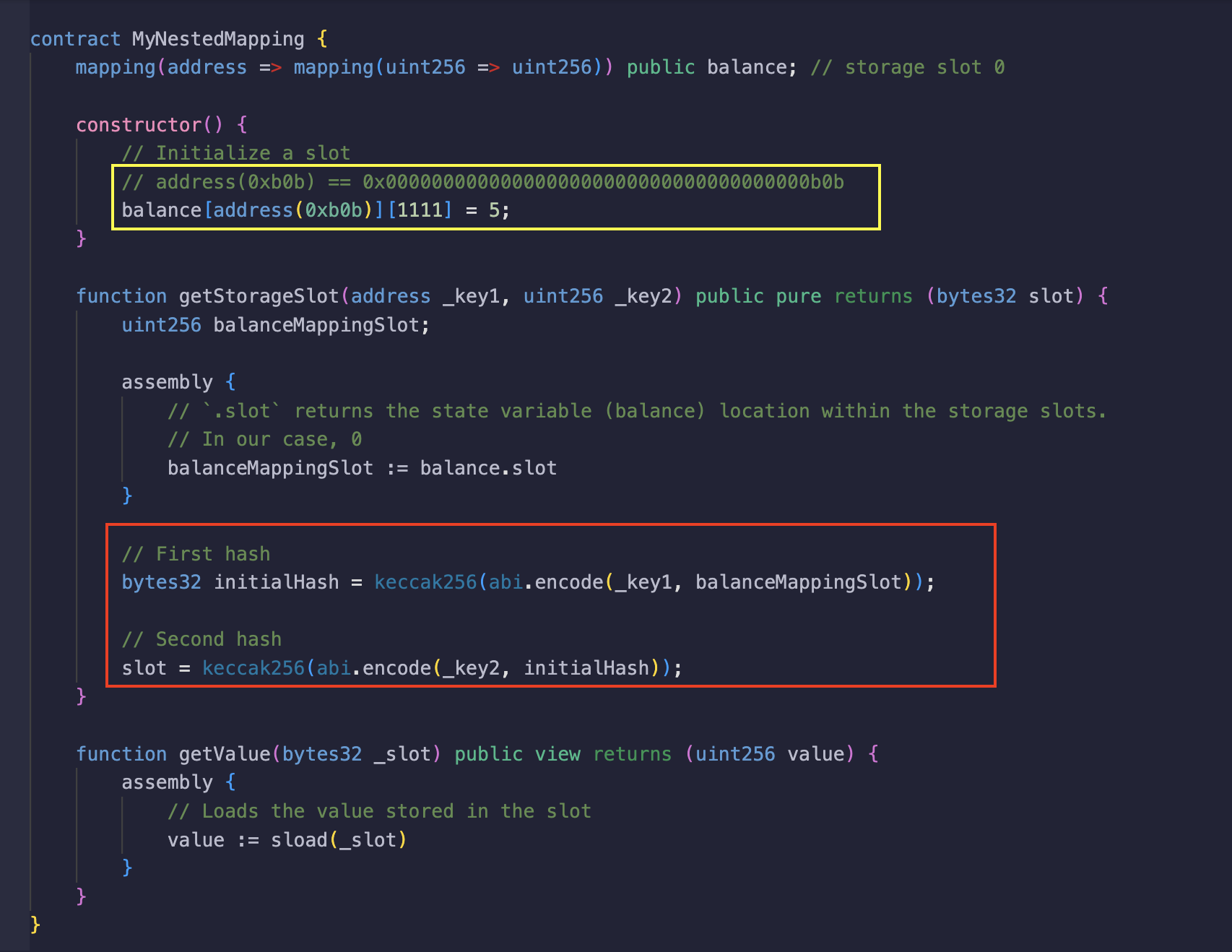
在下面的截图中,值 5 被分配给 balance 映射,键分别为 address(0xb0b)(owner)和 1111(tokenID),如黄色框中高亮显示。该合约有两个函数;
getStorageSlot函数接收两个参数,它们是推导所需槽位所需的键。如红框所示,该函数中还发生了两次哈希操作:- 第一次是
_key1(owner)和balance映射槽的哈希,然后将其存储在initialHash变量中。 - 第二次是
_key2(tokenID)和initialHash的哈希,以获取balance[_key1][_key2]的槽。如果是 3 层 mappings,第三个键(_key3)将与第二次哈希操作的值进行哈希处理以获得所需的存储槽,依此类推。
- 第一次是
getValue函数接收一个槽作为参数并返回其中保存的值,其行为与前面的示例相同。
使用以下参数 address(0xb0b) 和 1111 调用 getStorageSlot 函数,返回以下槽:
0x0b061f98898a826aef6fdfc2d8eb981af54b85700e4516b39466540f69aced0f
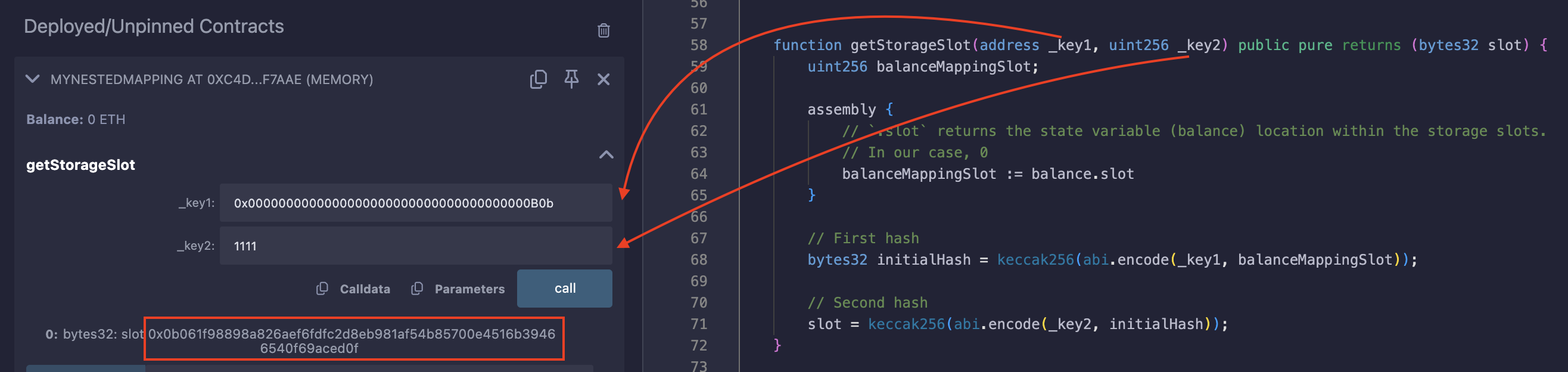
为了证明计算出的槽保存了值 5,我们将调用 getValue 函数并将槽作为参数传递。该函数使用 sload 操作码加载槽,然后返回其值:

没错!我们得到了在构造函数中插入的相同值 5。
Array(数组)
这是 Solidity 中的一种动态类型,用于存储同一类型(无论是原始类型还是动态类型)元素的索引集合。Solidity 支持两种数组类型:固定大小(fixed-size)和动态(dynamic),它们具有不同的存储分配方法。
固定大小 Arrays
此类数组具有预定的大小,在声明数组后不能更改。
固定大小 Array 的槽分配
如果数组的元素类型占据一个存储槽的容量(256 位、32 字节或 1 个字),Solidity 编译器会将这些元素视为单独的存储变量,从数组存储变量的槽开始依次为它们分配槽。
考虑下面的合约:
contract MyFixedUint256Array {
uint256 public num; // storage slot 0
uint256[3] public myArr = [
4, // storage slot 1
9, // storage slot 2
2 // storage slot 3
];
}
由于 num 的类型是 uint256 并且是合约中的第一个状态变量,它占据了整个存储槽 0。第二个状态变量 myArr 是一个包含三个元素的 uint256 固定大小数组,这意味着每个元素将占据自己的存储槽,从槽 1 开始。
下面的动画展示了如何为每个变量分配存储槽,详细说明了每个存储变量中的值是如何存储在槽中的。
让我们看另一个示例,与上一个类似,但这次数组的数据类型使用 uint32:
contract MyFixedUint32Array {
uint256 public num; // storage slot 0
uint32[3] public myArr = [
4, // storage slot ???
9, // storage slot ???
2 // storage slot ???
];
}
在继续阅读之前,你能说出数组中第三个元素的存储槽吗?如果你认为它可能是槽 3(与上一个示例类似),你可能需要重新考虑一下。
如果每个数组元素的类型没有占据整个存储槽,例如本例中的 uint32,编译器会在单个槽内将多个元素打包在一起,直到该槽被填满,或者没有足够的空间容纳下一个元素时,再移动到下一个槽。这类似于当存储变量不单独占据一个完整的槽时,编译器将它们打包在一起的方式。
打包的值是如何分配槽的:
注意:访问打包元素会消耗更多的 gas,因为 EVM 需要添加除了常规 sload 之外的额外指令。仅当你的元素通常在同一交易中被访问,从而可以共享冷加载(cold load)成本时,才建议对元素进行打包。
动态 Arrays
与在编译时预先确定大小的固定大小数组不同,动态数组可以在运行时改变大小。
动态 Array 的槽分配
通常,动态数组将其长度存储在某个地方,因为在编译时该长度是未知的。Solidity 遵循这一原则,将动态数组的长度存储在一个单独的存储槽中。下面是关于如何为动态数组的长度和元素分配槽的说明。
为数组长度分配的存储槽与数组存储变量的槽(base slot)是同一个槽。下面是一个说明这一点的示例:
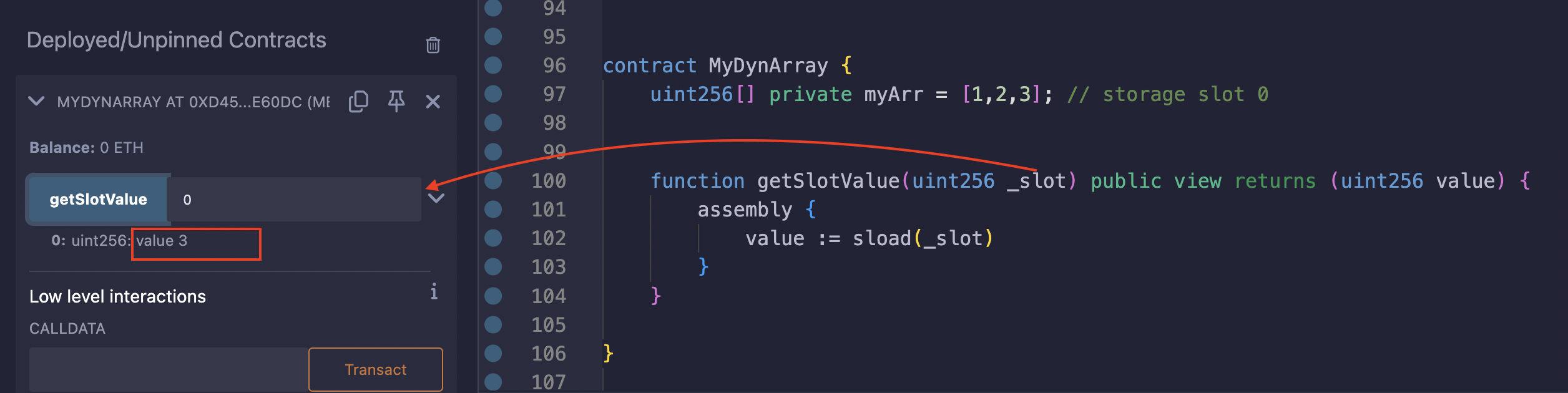
myArr 变量有三个元素,使其长度为 3。顾名思义,getSlotValue 函数接收一个槽号并返回其中存储的值。在我们的例子中,我们将槽 0 作为参数传递,因为那是分配给 myArr 存储变量的槽。然后我们使用 sload 操作码从槽中加载值。
数组的值依次保存在存储槽中,每个存储槽对应数组中的一个索引。第一个元素(索引 0)的存储槽由 base storage slot(声明变量所在的槽)的 keccak256 哈希值决定。下图说明了这一点。
槽 2 的 keccak 哈希指向保存第一个元素的槽,然后我们不断对该值加 1 以获取数组中其他索引的存储位置:
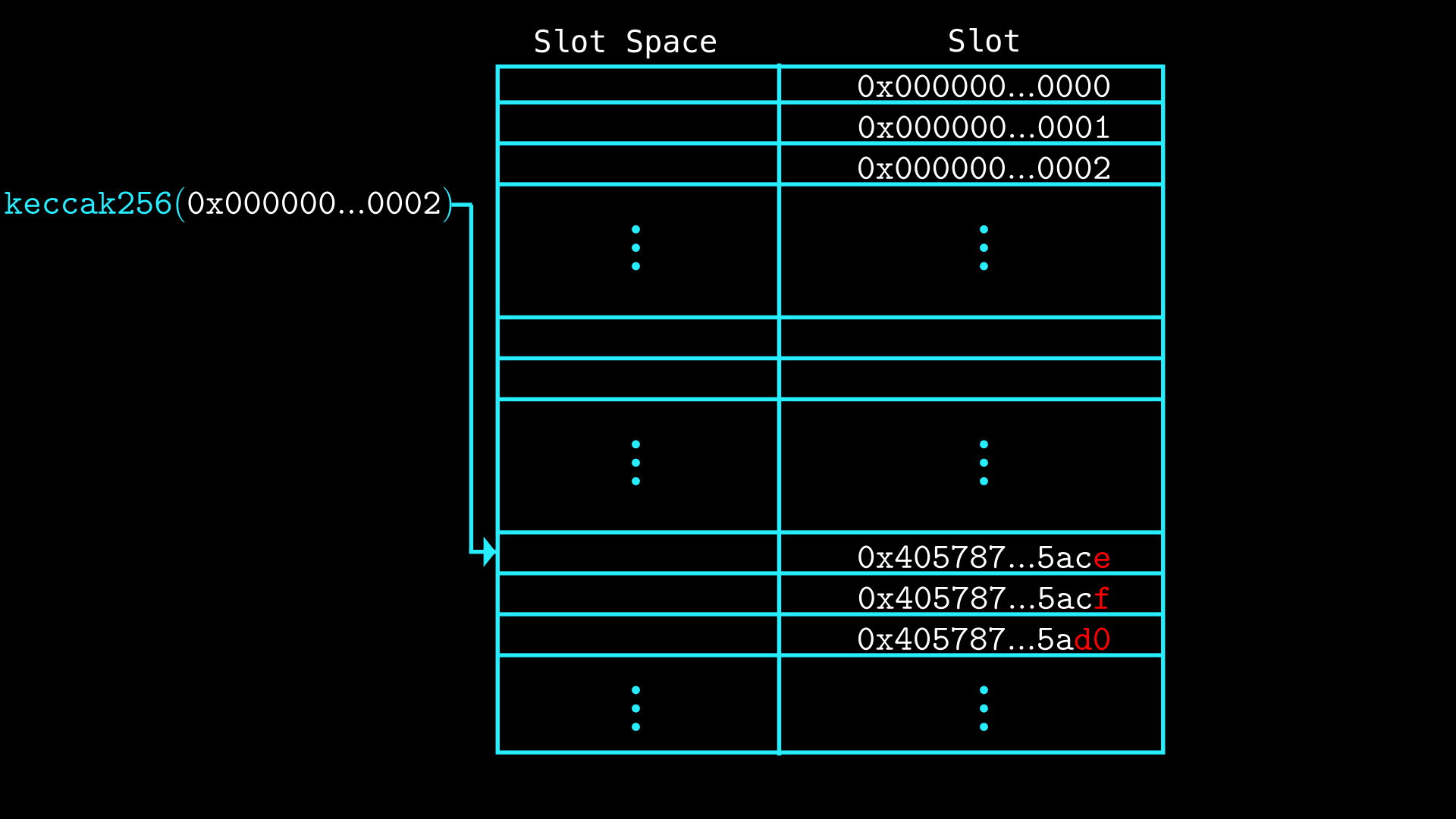
存储槽的编号从 0 到 2²⁵⁶ - 1,这正是 keccak256 输出的值范围。图片中的第一个红色值(0x405787...5ace)代表从槽 2 推导出的哈希存储位置,该位置保存了数组的第一个元素。随后的每一个值(0x405787...5acf,0x405787...5ad0)都是前一个值的递增,对应数组中的下一个元素。此模式对于每一个额外的元素都持续进行,存储位置根据数组的大小依次递增。
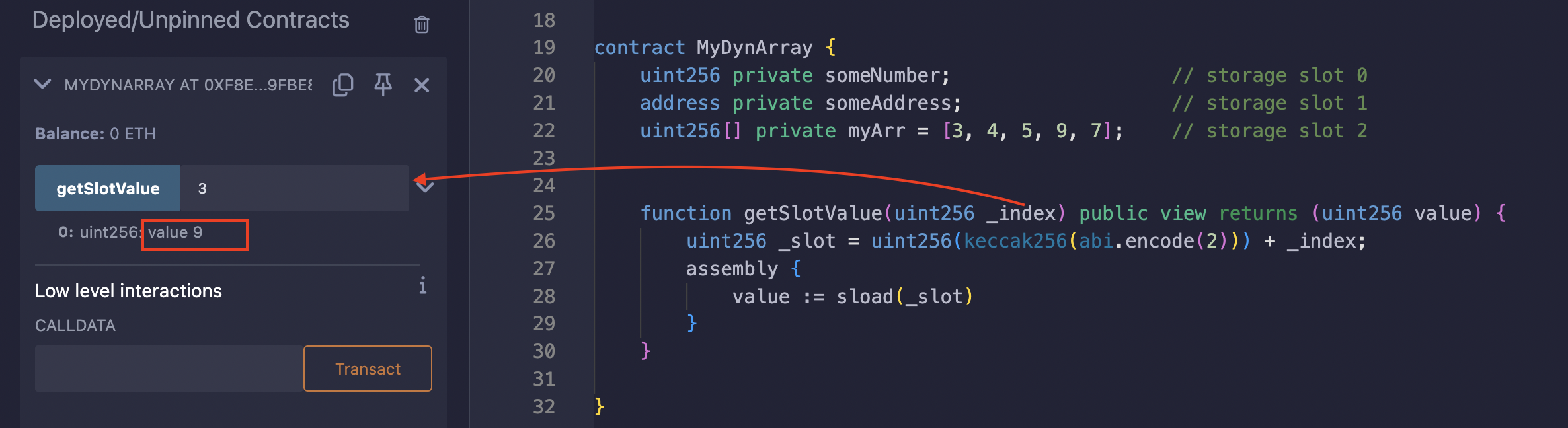
例如,考虑一个长度为 5 的数组位于存储槽 2,包含类型为 uint256 的元素 [3, 4, 5, 9, 7]:
contract MyDynArray {
uint256 private someNumber; // storage slot 0
address private someAddress; // storage slot 1
uint256[] private myArr = [3, 4, 5, 9, 7]; // storage slot 2
function getSlotValue(uint256 _index) public view returns (uint256 value) {
uint256 _slot = uint256(keccak256(abi.encode(2))) + _index;
assembly {
value := sload(_slot)
}
}
}
要找到保存值 9 的存储槽,我们首先使用 keccak256 对 base slot(2)进行哈希处理。然后我们将元素的索引(索引 = 3)加到哈希值上。这个计算结果给了我们保存值 9 的具体存储槽。最后,我们在获取的 _slot 中执行 sload。
在 remix 上测试:
当元素没有耗尽存储槽空间时会发生什么?
元素会被打包到存储槽中,直到可用空间被填满。只有像 128 位(16 字节)或更小的类型才能被打包。然而,每个占用 20 字节的地址类型不会被打包,因为两个地址(40 字节)超过了单个存储槽的大小。
让我们将 MyDynArray 合约中的 myArr 更改为使用 uint32 而不是 uint256:
contract MyDynArray {
uint256 private someNumber; // storage slot 0
address private someAddress; // storage slot 1
uint32[] private myArr = [3, 4, 5, 9, 7]; // storage slot 2
function getSlotValue(uint256 _index) public view returns (bytes32 value) {
uint256 _slot = uint256(keccak256(abi.encode(2))) + _index;
assembly {
value := sload(_slot)
}
}
}
进行了以下更改:
uint256[]⇒uint32[]:动态数组的数据类型。uint256 value⇒bytes32 value:返回值类型,这样我们可以很容易地看到值是如何打包的。
在每个存储槽可用的 32 字节中,每个元素占用 4 字节。对于 5 个元素,总大小为 4 * 5 = 20 字节。这意味着所有元素都可以容纳在一个存储槽中,并且还有剩余空间。
在 remix 上测试:
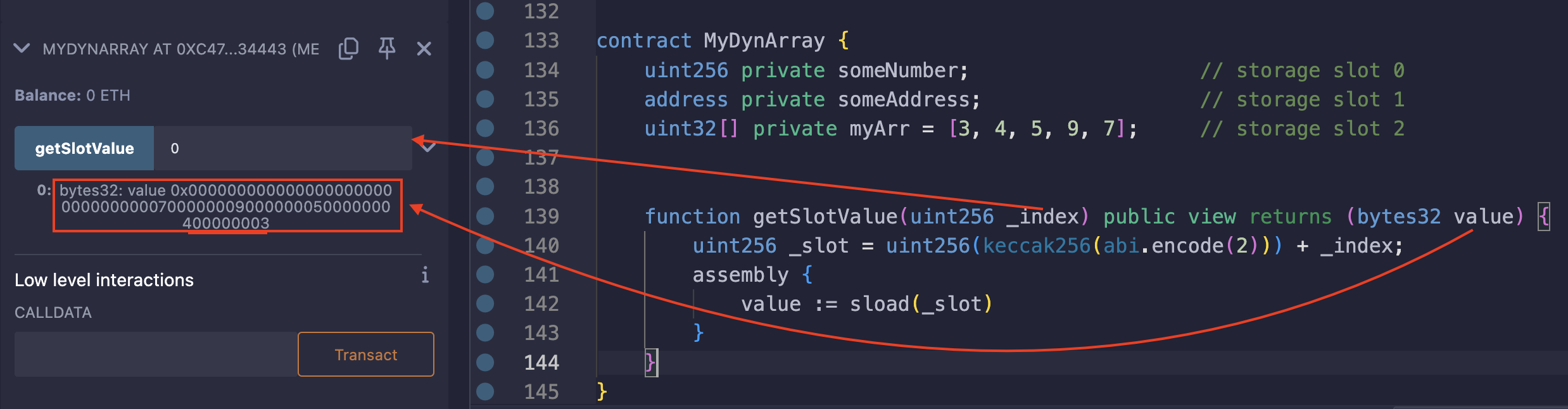
返回值:

嵌套 Array
嵌套数组是包含其他数组的数组。它可以用来表示类似矩阵的数据,其中每行内的元素是一个数组,而列是该数组内的索引。
下面的解释动画使用 C 代表列,R 代表行。
C ⇒ 绿色
R ⇒ 红色
固定大小嵌套 Array 的存储槽
编译器为固定大小的嵌套数组中的元素分配槽的方式与常规固定大小数组相同。如果元素占用整个槽,则从 base slot 开始,为其递增地分配一个槽。否则,它会与其他元素打包在一起,直到槽空间被填满。
下面是一个简单的动画,说明了固定大小的嵌套数组是如何存储数据的:
动态嵌套 Array 的存储槽
正如我们已经知道的,确定动态数组中特定元素的存储槽的步骤如下:
- 对 base slot 进行 keccak 哈希
- 然后将元素的索引加到哈希值上
对于动态嵌套数组,该过程涉及针对每个嵌套层级重复上述步骤以找到最终的槽。
假设我们有一个两层嵌套数组,即数组内部有数组:
确定元素 f 存储槽的步骤是:
- 对数组的 base slot 进行 keccak 哈希处理,然后添加保存该元素的子数组的索引。在我们的例子中,是第二个子数组。
- 对步骤 1 的结果进行 keccak 哈希处理,然后添加元素
f在子数组中的索引。
下面是说明上述步骤的动画:
我们首先对 base slot 进行哈希处理,并加上子数组的索引(sub-array1,即基础数组中的索引 1),这给出了初始哈希值(保存子数组的槽)。接下来,我们对该初始哈希值进行哈希处理,并加上元素 f(即 2)在 sub-array1 中的索引,以确定最终的槽。
获取 uint256 动态嵌套数组中元素槽位的一个实际示例:
contract MyNestedArray {
uint256 private someNumber; // storage slot 0
// Initialize nested array
uint256[][] private a = [[2,9,6,3],[7,4,8,10]]; // storage slot 1
function getSlot(uint256 baseSlot, uint256 _index1, uint256 _index2) public pure returns (bytes32 _finalSlot) {
// keccak256(baseSlot) + _index1
uint256 _initialSlot = uint256(keccak256(abi.encode(baseSlot))) + _index1;
// keccak256(_initialSlot) + _index2
_finalSlot = bytes32(uint256(keccak256(abi.encode(_initialSlot))) + _index2);
}
function getSlotValue(uint256 _slot) public view returns (uint256 value) {
assembly {
value := sload(_slot)
}
}
}
假设我们想要在上述合约的数组 [[2,9,6,3],[7,4,8,10]] 中找到保存元素 8 的存储槽。
-
我们需要确定三件事:
- 嵌套数组的 base slot
- 包含该元素的子数组的索引,
- 以及该元素在该子数组中的索引。
我们需要这些索引来获取我们所需的槽。
-
我们通过传递 baseSlot 和索引的值来调用
getSlot函数:- baseSlot:数组
a的槽,即槽 1。 - _index1:包含该元素的子数组(
[7,4,8,10])位于索引 1。 - _index2:子数组中的元素
8位于索引 2。
调用后返回的槽:
0xea7809e925a8989e20c901c4c1da82f0ba29b26797760d445a0ce4cf3c6fbd33 - baseSlot:数组
-
最后,调用
getSlotValue函数,传递步骤 2 中返回的槽。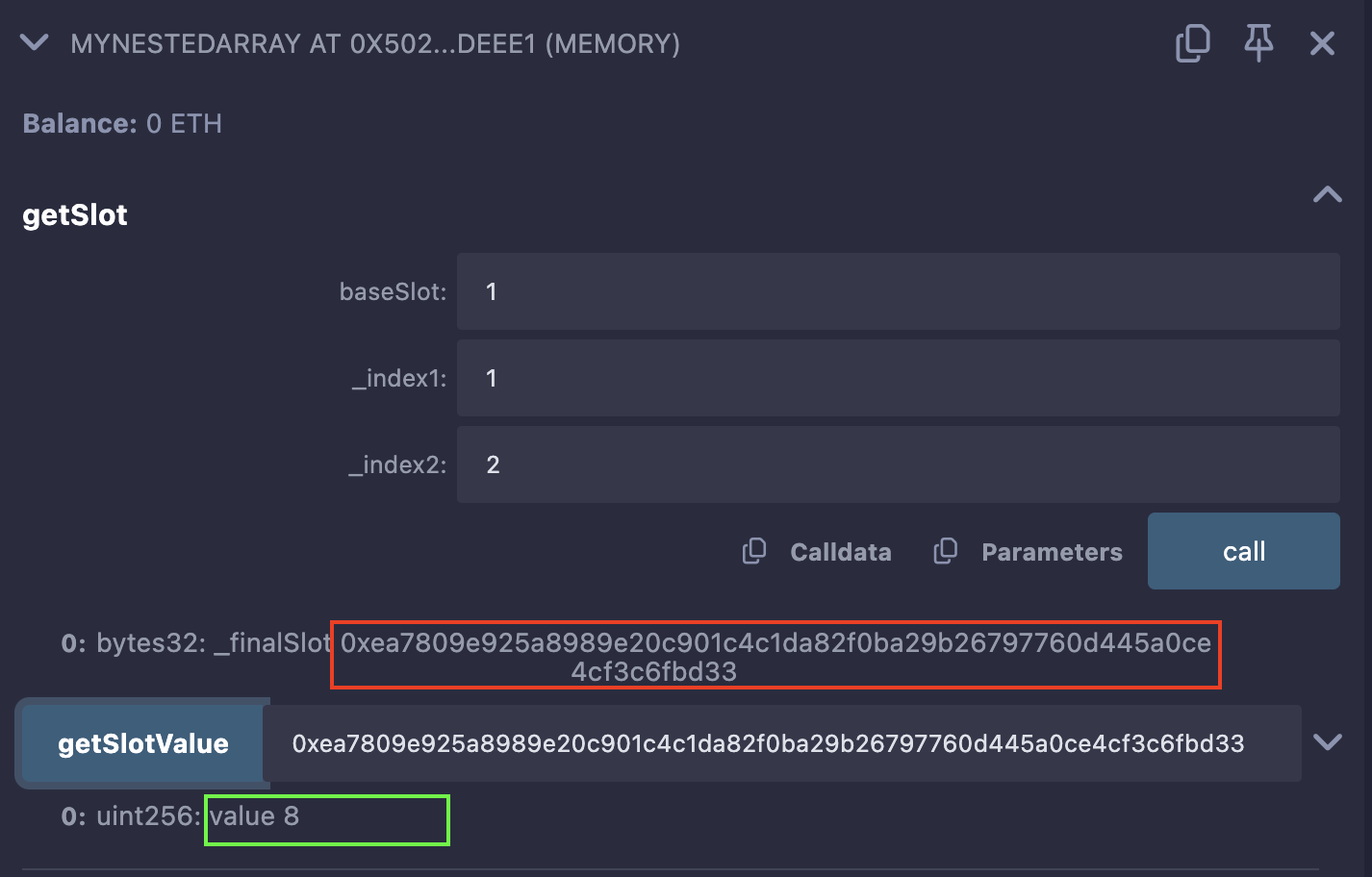
String(字符串)
Solidity 中的 strings 是动态类型,这意味着它们没有固定长度。某些 strings 可能适合放在单个存储槽中,而其他 strings 可能需要多个槽。
考虑以下示例合约:
contract String {
string public myString;
uint256 public num;
}
string 的存储槽是 0,uint256 的存储槽是 1。
如果我们在 myString 中存储较短的 string 数据(小于 32 字节的字符串,稍后我们将讨论为什么 32 字节的 string 也被视为长字符串),我们可以毫无问题地从槽 0 中检索它。
然而,如果我们存储更长的 string 数据,假设它占用 42 个字节,它会溢出槽 0 并覆盖槽 1,而槽 1 最初是为 num 变量保留的。
发生这种情况是因为槽 0 不够大,无法容纳较长的 string。为了防止这个问题,Solidity 会根据 string 的长度,采用不同的方法为 string 类型分配存储槽。
Strings 的存储槽
存储变量槽(base slot)会将 string 与其长度信息一起存储(对于短 strings),或者仅存储其长度信息(对于长 strings),下面将在不同的部分中研究这些情况。
短 String(≤ 31 字节):
string 数据及其长度一起存储在 base slot 中。string 从左侧开始打包,其长度存储在槽的最右侧字节中。对于短 strings,string 的最大长度是 31 个字符(字节)。然而,协议实际存储的是 string 长度乘以 2 的结果,因为在存储中每个字符占用一个字节。这意味着短 string 可以存储的最大值为 31 * 2 = 62,在十六进制中即为 0x3e。
下面是一个短 string Hello World 的十六进制示例。零表示空闲空间,可用于存储最长 31 字节的长字符串,而最后一个字节保存 (string 的长度) * 2。
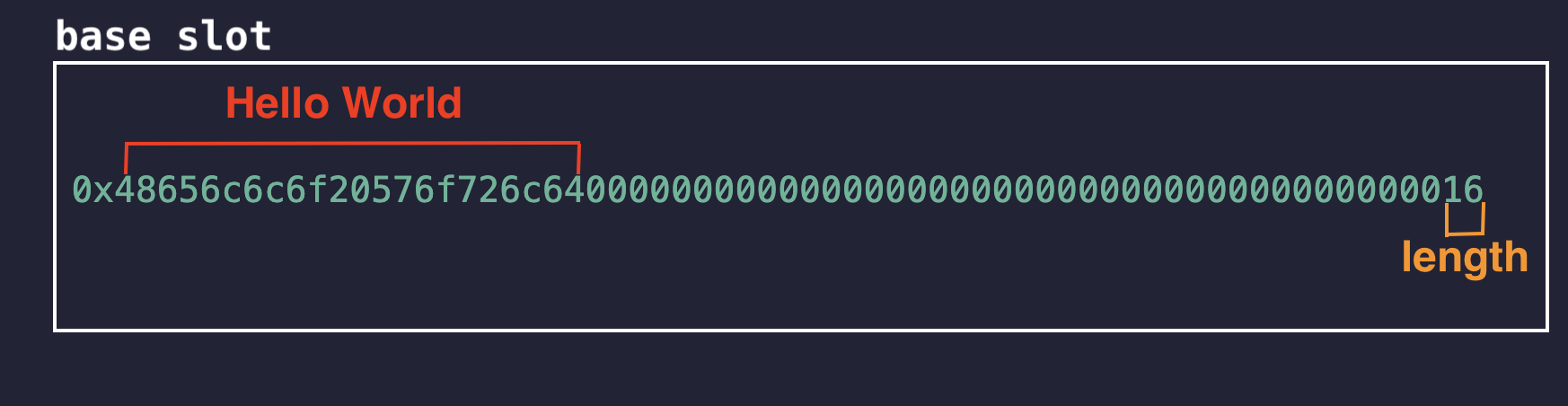
这里 0x16 = 22 是 2 * 11 的结果,其中 11 是 string Hello World 的长度。
长 String(> 31 字节):
(string 的长度 * 2) + 1(我们将稍后解释加 1 的原因)保存在 base slot 中,然后以十六进制形式的 string 被保存在连续的存储槽空间中。string 数据的前 32 字节保存在 base slot 的 keccak256 哈希处。接下来的 32 字节保存在 base slot 的哈希加一处,再下一段保存在哈希加二处,依此类推,直到整个 string 存储完毕。
下面的动画展示了长度和长 string(十六进制形式)是如何保存在存储槽中的:
在保存长 string 的长度之前,编译器会将其加一(使其从偶数变为奇数)。例如,上述动画中的 string 占用 47 字节(32 + 15),这意味着其长度为 47 * 2 = 94(十六进制的 0x5e)。然后 Solidity 编译器将此长度加 1,使其变为 95(十六进制的 0x5f),并将该值保存在 base slot 中。
这样做的原因是为了让运行时字节码能够高效地区分短 strings 和长 strings。对于短 strings,长度总是偶数,因此保存在 base slot 中的值的最后一位总是零。另一方面,长 strings(32 字节或更长)总是具有奇数的长度值,这意味着最后一位将总是一。
优化的奇偶校验
在大多数编程语言中,检查一个数字是偶数还是奇数的常见方法是使用取模运算符(num % 2)并检查余数是否为 0。这也适用于 Solidity。然而,更优化的方法是使用按位与(AND)操作:num & 1 == 0。下面是这两种方法及其各自消耗成本的示例:
contract ModMethod {
// Gas cost: 761
function isEven(uint256 num) public pure returns (bool x) {
x = (num % 2) == 0;
}
}
contract BitwiseAndMethod {
// Gas cost: 589
function isEven(uint256 num) public pure returns (bool x) {
x = (num & 1) == 0;
}
}
获取 String 的长度
Solidity 中的 String 类型没有 length 属性。这是因为某些字符(特别是那些非 ASCII 字符)可能占据多个字节,所以在字符可能具有不同大小的情况下跟踪字符的数量会产生过多的开销。然而,我们可以通过将 string 转换为 bytes 来查看它占据了多少个字节,如下面的示例所示:
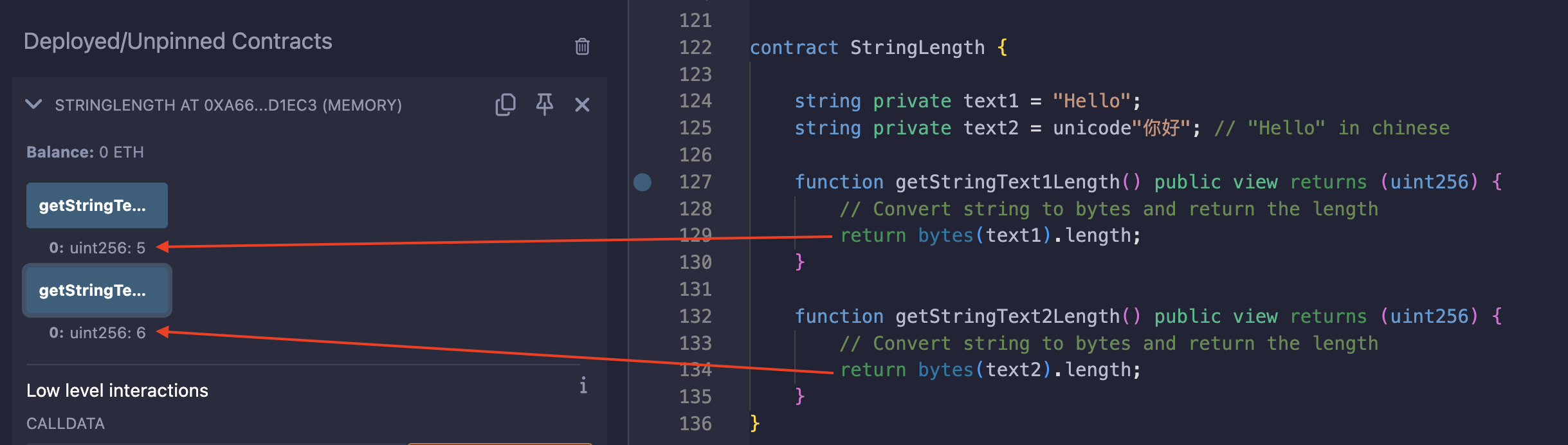
在 text2 中,每个字符占据 3 个字节,总共 6 个字节。要在 string 上使用 length 属性,你需要像截图中那样将 string 转换为 bytes。
Bytes(字节)
与 strings 一样,bytes 也是 Solidity 中的一种动态类型,并且遵循相同的一套槽分配规则。
- 短 ****bytes(≤ 31 字节):完全保存在 base slot 中,包括它的长度(
字节数 * 2)。 - 长 ****bytes(> 31 字节):base slot 保存长度(
(字节数 * 2) + 1),实际数据则从 base slot 的keccak256哈希处开始保存在连续的槽中。
固定大小的 Bytes
它们是用于存储固定数量字节的类型。这些类型从 bytes1 到 bytes32 不等,这意味着你可以拥有容纳 1 到 32 字节的固定大小字节数组。
存储比使用的 bytes 大小多或少的值都会引发编译时错误。在下图中,变量 value2 和 value4 被分配了不符合预期字节大小的值,从而导致编译错误。
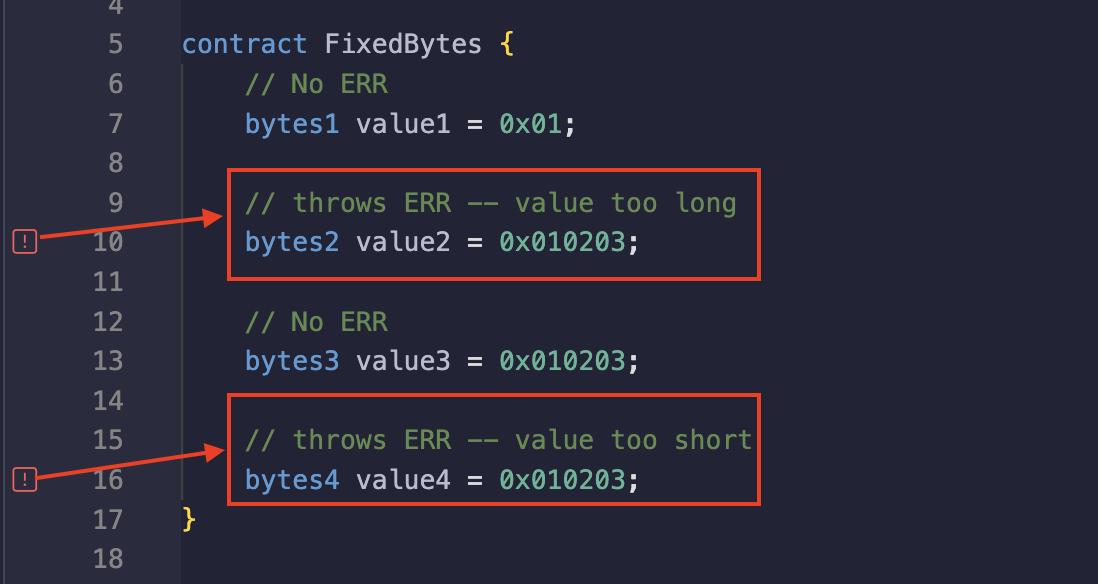
我们在前面的大多数代码示例中都使用了 bytes32 来保存 keccak256 哈希值。
访问单个字节
可以使用其索引来访问固定大小 bytes 数组内的某个字节。
例如,以下合约访问了第一个字节:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.9;
contract FixedBytes {
bytes4 value = hex"01020304";
function accessFirstByte() public view returns (bytes1) {
bytes1 individualByte = value[0]; // Access the first byte
return individualByte; // Returns the first byte
}
}
accessFirstByte 函数返回单个字节(bytes1)。在函数内部,value[0] 访问了 value 数组的第一个字节。然后返回此字节。
在 Solidity 0.8.0 版本之前,使用 byte 类型代替 bytes1 来表示单个字节。在 0.8.0 及以上版本中,bytes1 现在是保存单字节值的首选类型。
string/bytes 和 bytes1[] 的比较
两者都是存储字节值的动态类型,在两种情况下,都可以通过索引访问字节。然而,关键的区别在于字节值的存储方式。
考虑以下合约,它们为 bytes 和 bytes1[] 类型存储了相同的字节值:
contract Bytes {
bytes foo_bytes = hex"ffeedd";
// helper to get slot value
function getSlotValue() public view returns (bytes32 x) {
assembly {
x := sload(0)
}
}
}
contract Bytes1Array {
bytes1[] bar_bytes = [bytes1(hex"ff"), bytes1(hex"ee"), bytes1(hex"dd")];
// helper to get slot value
function getSlotValue() public view returns (bytes32 x) {
bytes32 _slot = keccak256(abi.encode(0));
assembly {
x := sload(_slot)
}
}
}
由于分配给 foo_bytes 变量的值是一个短 bytes 序列(即 ≤ 31 字节),该值及其长度(字节数 * 2)都保存在同一个存储槽(base slot)中,如下所示:
另一方面,bar_bytes 变量的类型为 bytes1[](一个动态数组),它将数组的长度和值保存在单独的槽中:
长度保存在 base slot 中:
值保存在 base slot 的哈希位置:
换句话说,带有短序列的 bytes 类型比 bytes1[] 使用更少的存储槽。然而,对于长于 31 字节的序列,bytes 类型使用与 bytes1[] 相同的槽计算方式,导致使用的槽数量相同。
bytes 和 bytes1[] 之间的另一个区别是它们的值在槽中的存储方式。对于 foo_bytes,整个值一次性放入其槽中。相比之下,对于 bar_bytes,第一个元素保存在最低有效字节中,然后是下一个元素,此模式一直持续到最后一个字节。
该动画展示了分配给 foo_bytes 和 bar_bytes 变量的新值是如何各自占据两个槽(绿色和黄色的槽)的,其中 foo_bytes 占据槽 0,bar_bytes 占据槽 1:
Struct(结构体)
Solidity 中的 Structs 允许我们将多个不同数据类型的变量组合在一个名称下,并将其用作新类型。例如,如果我们想要一个合约来存储诸如 playerId、score 和 level 等玩家信息,使用 struct 将是理想的选择。这样,我们就可以将关于每个玩家的所有相关详细信息组合成一个单一且有条理的结构。
Struct 中的存储槽
Solidity 中的 struct 充当变量的容器,struct 内部每个字段的存储槽分配遵循我们之前讨论过的相同规则。
让我们看一个示例:
contract MyStruct {
// Define a Player struct
struct Player {
address playerId;
uint256 score;
uint256 level;
}
uint256 private someNumber = 99;
/*
AFTER DIFFERENT DECLARATIONS ABOVE, THE NEXT AVAILABLE SLOT IS: 6
*/
// Declare a state variable of type Player
Player private thePlayer;
}
在不运行代码的情况下,你能猜出槽 0 中的值吗?如果你认为它是 99,那么你猜对了。这是因为 在 Solidity 中定义 struct 在被声明之前不会占用存储槽空间,所以编译器将 someNumber 变量视为第一个存储变量。
声明一个 Player Struct 类型的变量:
让我们检查一下 struct 的存储是如何工作的,首先声明一个 struct——这将导致它实际占用存储空间。注意这里是我们声明它,而不是像之前那样定义它。
/*
AFTER DIFFERENT DECLARATIONS ABOVE, THE NEXT AVAILABLE SLOT IS: 6
*/
// Declare a state variable of type Player
Player private thePlayer;
当被声明时,Player struct 内的字段将占据三个连续的存储槽,从 base slot 开始计算。playerId 字段属于 address 类型,在槽的 32 字节可用空间中使用了 20 字节。由于 score 和 level 字段的类型是 uint256,它们各自占据了完整的 256 位(32 字节)的槽空间。了解了这一点,我们可以说这些字段的存储槽分别是 6、7 和 8。
Struct 内动态类型的存储槽分配
另一个例子是在 struct 内拥有动态类型。让我们修改上一个示例以使用 mappings,并为其分配一些值:
contract MyStruct {
// Define a Player struct
struct Player {
address playerId;
mapping(uint256 level => uint256 score) playerScore;
}
uint256 private someNumber = 23; // storage slot 0
uint256 private someNumber1 = 77; // storage slot 1
// Declare a state variable of type Player
Player private thePlayer;
constructor () {
// Set deployer's address as player's id
thePlayer.playerId = msg.sender;
// Set player's score to 100 for level 1 and 68 for level 2
thePlayer.playerScore[1] = 100;
thePlayer.playerScore[2] = 68;
}
}
计算 struct 内的 mapping 中值的存储槽的步骤如下:
- 确定
thePlayerstruct 的 base slot:此槽在合约中声明 struct 时确定。 - 计算 struct 内
playerScoremapping 的槽:此槽由 mapping 在 struct 中声明的顺序决定。 - 对键与 mapping 的 base slot(即在步骤 2 中获取的槽)拼接的结果进行哈希处理。
了解了这些步骤后,我们就可以计算出保存级别 2 玩家分数的存储槽。
第 1 步:确定 thePlayer 的 base slot
thePlayer是上述合约中声明的 struct,并且因为它是在someNumber和someNumber1变量之后声明的,所以它的 base slot 将是槽2(因为someNumber占据槽 0,someNumber1占据槽 1)。
第 2 步:计算 struct 内 playerScore mapping 的槽
// Define a Player struct
struct Player {
address playerId;
mapping(uint256 level => uint256 score) playerScore;
}
- 从 struct 的 base slot(槽 2)开始,依次为每个字段分配槽。这意味着类型为
address的第一个字段playerId占据槽 2(base slot),而第二个字段playerScoremapping 则放在下一个槽中,也就是槽3(mapping 的 base slot)。
第 3 步:对键与 mapping 的 base slot 的拼接结果进行哈希处理
-
由于键和 mapping 的 base slot 已知,我们可以通过将它们拼接并进行哈希处理来计算出我们的目标存储槽。
下图展示了通过传递正确的键(在本例中为 level
2)和 mapping 的 base slot(3),然后对目标槽执行sload,是如何确定目标槽(绿框)的: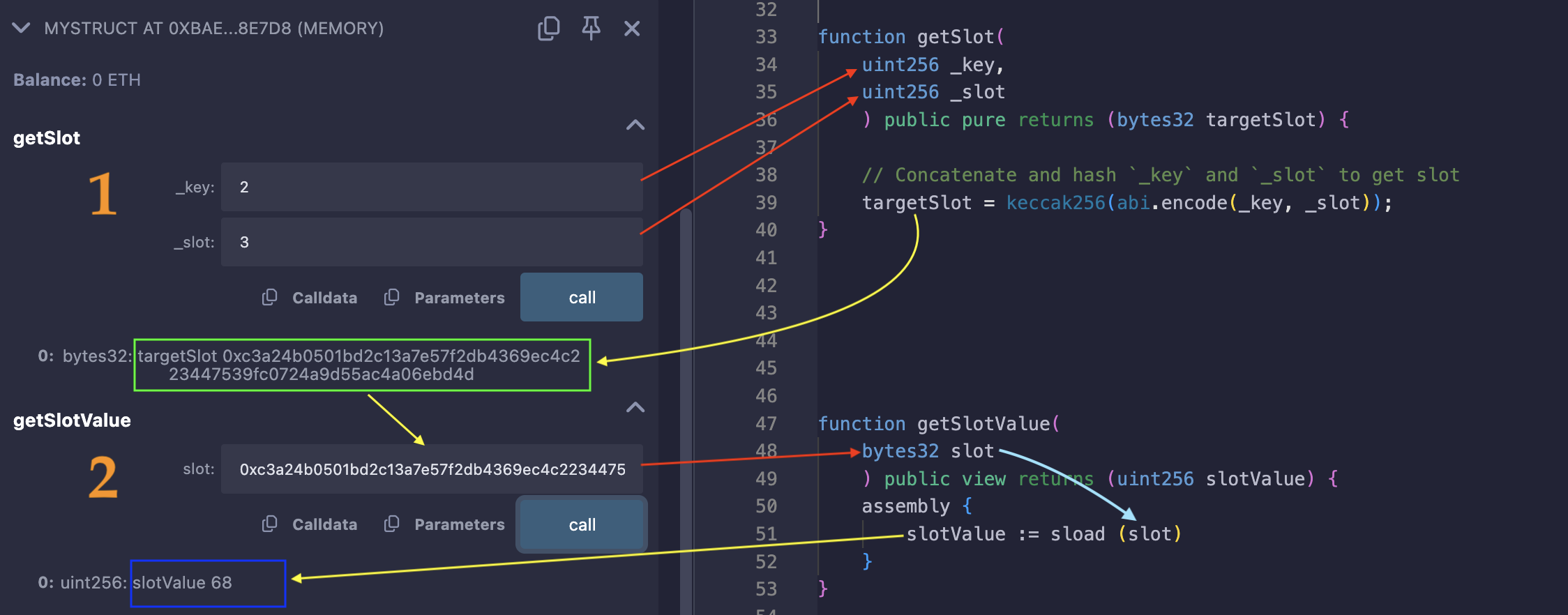
在蓝框中,是从对目标槽执行 sload 操作返回的值(玩家在 level 2 的分数)。