पिछले लेख में, हमने sBPF VM आर्किटेक्चर, रजिस्टर कन्वेंशंस और इंस्ट्रक्शन सेट को कवर किया था। अब हम agave-ledger-tool (एक CLI टूल जो Solana टूलचेन के साथ आता है) का उपयोग करके वास्तविक बाइटकोड निष्पादन (execution) का विश्लेषण करेंगे, ताकि execution traces उत्पन्न किए जा सकें और किसी प्रोग्राम द्वारा उपयोग की जाने वाली compute units की मैन्युअल रूप से गणना की जा सके।
हालाँकि opcodes को मैन्युअल रूप से ट्रेस करना चुनौतीपूर्ण है, लेकिन हम स्वचालित रूप से एक दृश्य (visual) ट्रेस उत्पन्न कर सकते हैं कि प्रत्येक opcode निष्पादन के साथ हर रजिस्टर कैसे अपडेट हुआ। इससे हमें यह देखने में मदद मिलती है कि वास्तव में कौन से instructions चलते हैं और compute units कैसे जमा (accumulate) होते हैं।
एक Simple Program का विश्लेषण करना
आइए एक साधारण Anchor प्रोग्राम के बाइटकोड का विश्लेषण करके देखें कि प्रत्येक भाग SBF instructions में कैसे बदलता है और वे रजिस्टरों का उपयोग कैसे करते हैं। यह हमें मैन्युअल रूप से compute unit लागत की गणना करने की भी अनुमति देगा।
प्रोजेक्ट सेटअप
सबसे पहले, एक नए प्रोजेक्ट को इसके साथ इनिशियलाइज़ (initialize) करें:
anchor init compute_unit
cd compute_unit
programs/compute_unit/src/lib.rs में मौजूद कोड को नीचे दिए गए न्यूनतम (minimal) प्रोग्राम से बदलें। हम एक खाली initialize फ़ंक्शन का उपयोग करते हैं ताकि हम बिना किसी बिज़नेस लॉजिक के बेसलाइन compute costs को मापने पर ध्यान केंद्रित कर सकें:
use anchor_lang::prelude::*;
declare_id!("CR33kP6d39mBZv1ryjufVXoRm6djnWW8uKoQXwU5kgDV");
#[program]
pub mod compute_unit {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize {}
हम एक लोकल वैलिडेटर (local validator) पर initialize फ़ंक्शन चलाएंगे (हम आगे देखेंगे कि कैसे) और यह देखने के लिए solana logs का उपयोग करेंगे कि यह कितनी compute units की खपत करता है। फिर हम प्रोग्राम को डिसअसेंबल (disassemble) करेंगे और यह देखने के लिए एक execution trace उत्पन्न करेंगे कि कौन से SBF opcodes चले। ऐसा करने पर, हम मैन्युअल रूप से गणना कर सकते हैं कि प्रत्येक इंस्ट्रक्शन कुल compute unit लागत में कैसे जुड़ता है।
एक लोकल वैलिडेटर बनाएं (build) और शुरू करें:
anchor keys sync
anchor build
फिर एक नए टर्मिनल में:
solana-test-validator
यह एक लोकल वैलिडेटर चालू करता है और एक test-ledger/ डायरेक्टरी बनाता है—प्रोग्राम ट्रेस उत्पन्न करते समय लेजर स्टेट को लोड करने के लिए agave-ledger-tool इस डायरेक्टरी का उपयोग करता है।
किसी अन्य टर्मिनल में solana logs चलाएँ, फिर यह देखने के लिए कि initialize फ़ंक्शन वास्तव में कितनी compute units का उपयोग करता है, एक अलग टर्मिनल में anchor test --skip-local-validator चलाएँ। यदि हम ऐसा करते हैं, तो हमें 272 compute units प्राप्त होती हैं। हम इस पर बाद में वापस आएंगे।

प्रोग्राम को Disassemble करना
Solana बाइटकोड विश्लेषण में पहला कदम निष्पादन योग्य (executable) Solana प्रोग्राम बाइनरी (जो आमतौर पर target/deploy/<project_name>.so फ़ाइल में संग्रहीत होता है) को बाइटकोड निमोनिक्स (mnemonics) में बदलना है जिसे हम थोड़ा बेहतर समझ सकें। निमोनिक्स (Mnemonics) केवल बाइनरी/हेक्साडेसिमल opcodes का एक मानव-पठनीय (human-readable) प्रतिनिधित्व है, उदाहरण के लिए, EVM से, 0x60 = PUSH1, 0x52 = MSTORE इत्यादि।
हमें प्रोजेक्ट रूट में एक test-ledger फ़ोल्डर की आवश्यकता है जिसमें genesis.bin फ़ाइल हो। हमने पहले जो solana-test-validator चलाया था, वह इन्हें स्वचालित रूप से उत्पन्न करता है। प्रोग्राम्स को डिसअसेंबल करते समय लेजर स्टेट को लोड करने के लिए agave-ledger-tool (Solana टूलचेन का हिस्सा) इस फ़ाइल का उपयोग करता है।
अब हम अपने प्रोग्राम को इसके साथ डिसअसेंबल कर सकते हैं:
agave-ledger-tool program --ledger test-ledger disassemble target/deploy/compute_unit.so --output json > output.txt
यह असेंबली निमोनिक्स को output.txt में डंप कर देता है। आप कुछ ऐसा देखेंगे:
function_0:
mov64 r0, r2
and64 r0, 1
jeq r0, 0, lbb_32
mov64 r0, 0
jslt r5, 0, lbb_34
stxdw [r10-0x8], r3
jeq r5, 0, lbb_41
...
...
function_0: जैसे लेबल्स बाइटकोड में जंप डेस्टिनेशन (jump destinations) होते हैं जिन पर अन्य इंस्ट्रक्शन्स call इंस्ट्रक्शन का उपयोग करके जंप कर सकते हैं। Rust फ़ंक्शंस इंस्ट्रक्शन्स के क्रम (sequences) में संकलित (compile) होते हैं, और कंपाइलर फ़ंक्शन एंट्रीज़ या आंतरिक कोड ब्लॉक्स को चिह्नित करने के लिए इन लेबल्स को उत्पन्न करता है। इसलिए जब आप call function_11561 जैसा कुछ देखते हैं, तो निष्पादन बाइटकोड में उस ऑफ़सेट पर जंप कर जाता है और वहां के इंस्ट्रक्शन्स को चलाता है।
यह हमारे Solana प्रोग्राम का निमोनिक्स है। हालाँकि, हम इसके साथ बहुत कुछ नहीं कर सकते, यह बहुत बड़ा है और मैन्युअल रूप से विश्लेषण करना बेहद चुनौतीपूर्ण है।
एक Execution Trace उत्पन्न करना
ट्रेस उत्पन्न करने के लिए, हमें agave-ledger-tool को बताना होगा कि हमारे प्रोग्राम में किस फ़ंक्शन को कॉल करना है। हम एक instructions.json फ़ाइल बनाकर ऐसा करते हैं, जिसे हम टूल को पास करेंगे जैसा कि आप जल्द ही देखेंगे।
अब, हमारे प्रोजेक्ट रूट फ़ोल्डर में एक instructions.json फ़ाइल बनाएं और नीचे दिए गए कोड को पेस्ट करें:
{
"accounts": [],
"program_id": <program_id>,
"instruction_data": [175, 175, 109, 31, 13, 152, 155, 237]
}
उपरोक्त पैरामीटर्स दर्शाते हैं: accounts सूची (यहाँ खाली है क्योंकि हमारा initialize फ़ंक्शन कोई accounts नहीं लेता है), इनवोक (invoke) करने के लिए program_id (<program_id> को अपने असली प्रोग्राम आईडी से बदलें), और इंस्ट्रक्शन डेटा।
instruction_data फ़ील्ड में केवल initialize फ़ंक्शन के लिए 8-बाइट डिस्क्रिमिनेटर (discriminator) होता है (कोई अतिरिक्त आर्ग्यूमेंट नहीं क्योंकि हमारा फ़ंक्शन कोई भी आर्ग्यूमेंट नहीं लेता है)। Anchor sha256("<namespace>:<function_name>") के पहले 8 बाइट्स लेकर इन डिस्क्रिमिनेटर्स को जनरेट करता है। हमारे मामले में, यह sha256("global:initialize") है। नेमस्पेस ग्लोबल है क्योंकि हमारा प्रोग्राम हमारे कोडबेस के सबसे बाहरी स्कोप (outermost scope) में समाहित है।
अब चलिए ट्रेस उत्पन्न करते हैं:
agave-ledger-tool program run target/deploy/compute_unit.so --limit 200000 --trace trace.txt --ledger test-ledger --input instructions.json
यह हमारे इंस्ट्रक्शन डेटा (initialize फ़ंक्शन) के साथ प्रोग्राम को चलाता है और निष्पादन ट्रेस को trace.txt.0 में आउटपुट करता है। --limit फ़्लैग एक compute unit लिमिट सेट करता है। यह आवश्यक नहीं है, लेकिन यह टेस्टिंग के लिए उपयोगी है।
नोट: यदि आपको Err(JitNotCompiled) कहते हुए कोई एरर (error) मिलता है (उदाहरण के लिए, ARM MacBook का उपयोग करते समय), तो डिफ़ॉल्ट JIT compilation मोड के बजाय इंटरप्रेटर मोड का उपयोग करने के लिए अपने कमांड में --mode interpreter जोड़ें।
Execution Trace को पढ़ना
trace.txt.0 फ़ाइल कुछ इस तरह दिखती है। हमने स्पष्टता के लिए प्रत्येक अनुभाग को लेबल किया है और केवल पहले 6 इंस्ट्रक्शन्स दिखाते हैं:

यह हमें प्रोग्राम और इसके द्वारा खपत की गई compute units का विश्लेषण करने और समझने के लिए पर्याप्त जानकारी देता है।
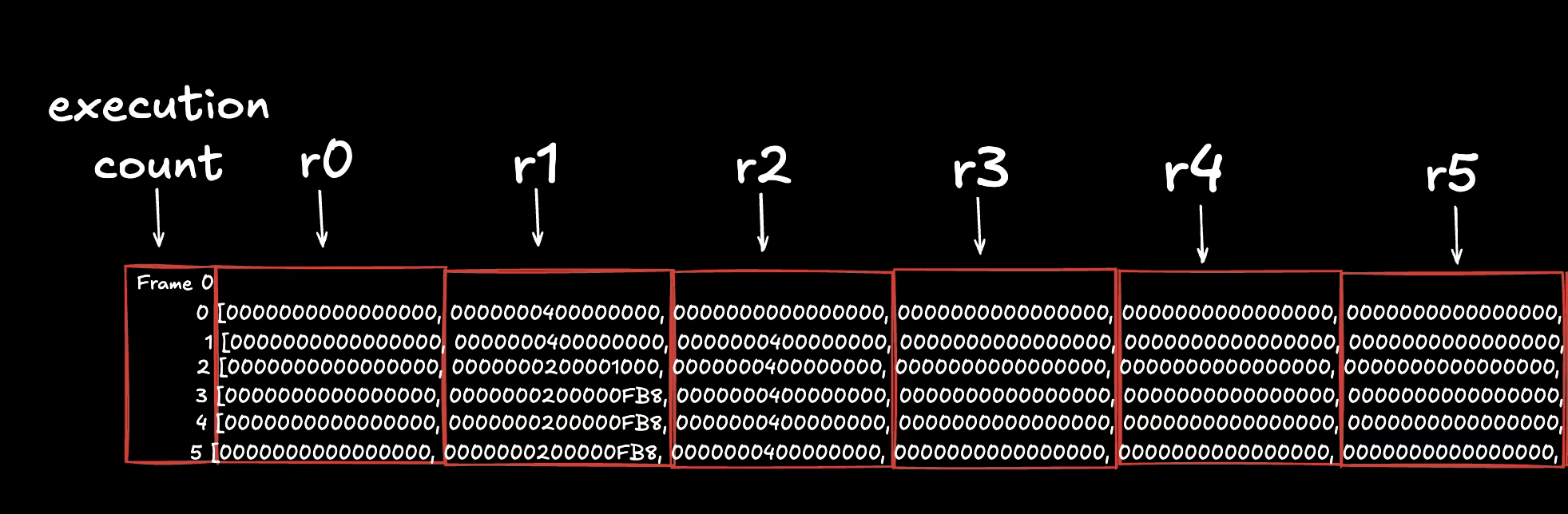
आइए देखें कि प्रत्येक कॉलम क्या दर्शाता है:
- निष्पादन गणना कॉलम (Execution count column - पहला कॉलम): यह निष्पादन काउंटर (execution counter) है।
- r-उपसर्ग वाले कॉलम (r-prefixed columns - कॉलम 2-12): इसके ऊपर के इंस्ट्रक्शन को निष्पादित किए जाने के बाद Solana VM के 11 रजिस्टरों (
r0-r10) में से प्रत्येक की स्थिति/वैल्यू (state/value) को दर्शाता है। - प्रोग्राम काउंटर कॉलम (Program counter column - कॉलम 13): प्रोग्राम की बाइनरी में दिए गए इंस्ट्रक्शन/opcode का प्रोग्राम काउंटर (PC) या इंडेक्स।
- इंस्ट्रक्शन कॉलम (Instruction column - कॉलम 14): वह इंस्ट्रक्शन/opcode और उसके ऑपरेंड्स (operands) जिन्हें आगे निष्पादित किया जाना है।
अब ट्रेस आउटपुट के पहले 6 इंस्ट्रक्शन्स को देखते हैं ताकि हम यह समझ सकें कि निष्पादन के दौरान रजिस्टरों में वैल्यूज कैसे बदलती हैं। रजिस्टरों की वैल्यूज को अधिक स्पष्ट रूप से देखने के लिए आइए छवि को विभाजित करें:
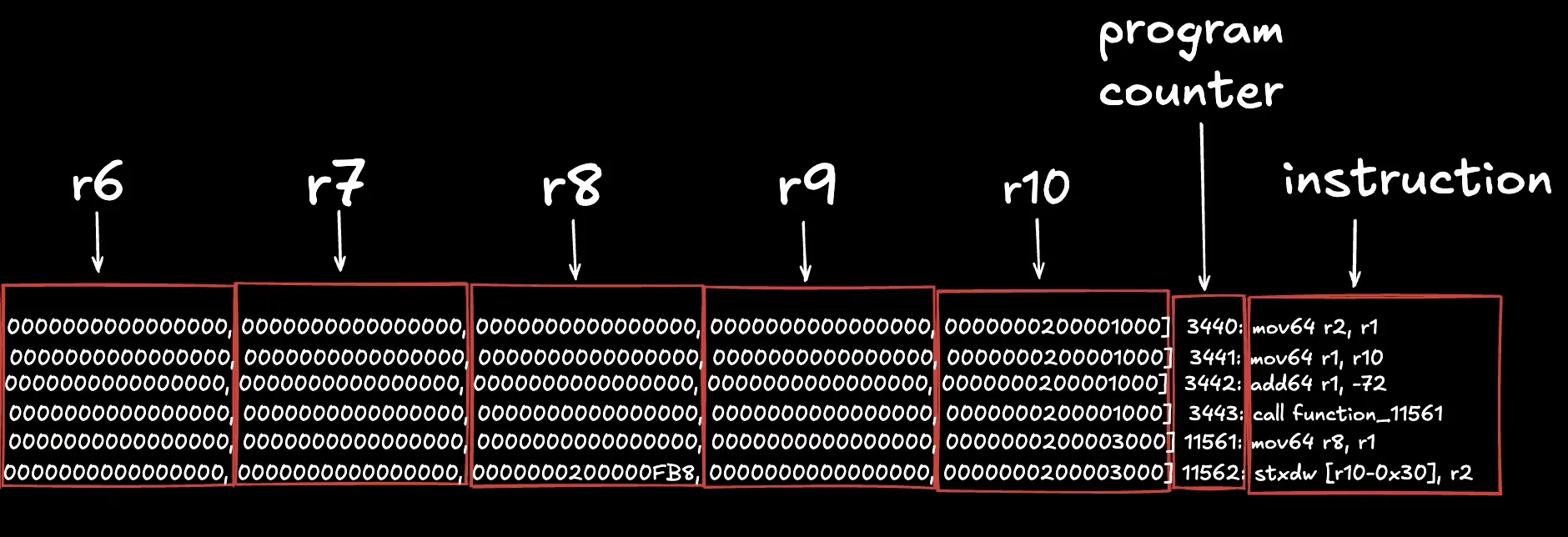
- पहला इंस्ट्रक्शन (
mov64 r2, r1) रजिस्टर 1 से 64-बिट वैल्यू को रजिस्टर 2 में कॉपी करता है। अगली पंक्ति में,r1औरr2दोनों एक ही वैल्यू रखते हैं। - दूसरा इंस्ट्रक्शन (
mov64 r1, r10) रजिस्टर 10 से वैल्यू को रजिस्टर 1 में कॉपी करता है। - तीसरा इंस्ट्रक्शन (
add64 r1, -72)r1की वैल्यू में से 72 घटाता है और परिणाम को वापसr1में स्टोर करता है। - चौथा इंस्ट्रक्शन (
call function_11561) एक अन्य फ़ंक्शन पर जंप करता है; फ़ंक्शन के वापस लौटने (return) पर कॉल के बाद निष्पादन फिर से शुरू होता है। - पांचवां इंस्ट्रक्शन (
mov64 r8, r1) रजिस्टर 1 की वैल्यू को रजिस्टर 8 में कॉपी करता है (कॉल किए गए फ़ंक्शन के अंदर, जैसा कि PC परिवर्तन द्वारा दिखाया गया है। इस फ़ंक्शन कॉल के कारण PC 3443 से 11561 हो गया)। - छठा इंस्ट्रक्शन (
stxdw [r10-0x30], r2) रजिस्टर 2 से 64 बिट्स कोr10में मौजूद एड्रेस से मेमोरी ऑफ़सेट0x30को घटाकर प्राप्त एड्रेस पर मेमोरी में स्टोर करता है। यह देखते हुए कि, इस छठे निष्पादन में, रजिस्टर 2 की वैल्यू0x0000000400000000है और रजिस्टर 10 की वैल्यू0x0000000200003000है, इसका मतलब है कि इंस्ट्रक्शन 64-बिट वैल्यू0x0000000400000000को मेमोरी एड्रेस0x0000000200002FF0पर स्टोर करेगा (जोr10 - 0x30है, जहांr10में संग्रहीत एड्रेस से निर्दिष्ट ऑफ़सेट घटाकर एक नए एड्रेस की गणना की जाती है)।
Compute Units की गणना करना
अब जब हमने देख लिया है कि execution trace कैसे प्रदर्शित होता है और प्रत्येक कॉलम क्या दिखाता है, तो अगला सवाल यह है कि यहाँ compute unit की भूमिका कहाँ आती है?
प्रत्येक sBPF इंस्ट्रक्शन की कीमत 1 compute unit होती है। हालाँकि, syscall इंस्ट्रक्शन अतिरिक्त शुल्क लगाते हैं जो प्रकार के अनुसार भिन्न होते हैं। Total compute units = instruction count + syscall instruction charges.
आइए इसे व्यवहार में (in action) देखते हैं। इसी प्रोग्राम में, यदि हम execution trace के अंत तक स्क्रॉल करते हैं (trace.txt.0 फ़ाइल में), तो हम देख सकते हैं कि अंतिम निष्पादन गणना/इंडेक्स 171 है जिसका अर्थ है कि इस प्रोग्राम ने 172 इंस्ट्रक्शन्स (इंडेक्स 0-171) निष्पादित किए। उसी कॉल के लिए वैलिडेटर लॉग (नीचे दिखाया गया है) में 272 compute units की खपत दर्ज की गई है।
यह अंतर (100) लॉगिंग syscall से आता है जो इंस्ट्रक्शन का नाम प्रिंट करता है (“Program log: Instruction: Initialize”)।
वह syscall sol_log_ है, जो syscall_base_cost के रूप में 100 compute units (लिखते समय) का शुल्क लगाता है। अब, यदि हम इसे 172 इंस्ट्रक्शन काउंट में जोड़ते हैं, तो हमें 172 + 100 = 272 कुल compute units मिलते हैं।
हम अपनी trace.txt.0 फ़ाइल में syscall opcode खोजकर इसे सत्यापित कर सकते हैं। यह एक बार दिखाई देता है — निष्पादन गणना 157 पर syscall sol_log_।
PC 0 से शुरू क्यों नहीं होता है?
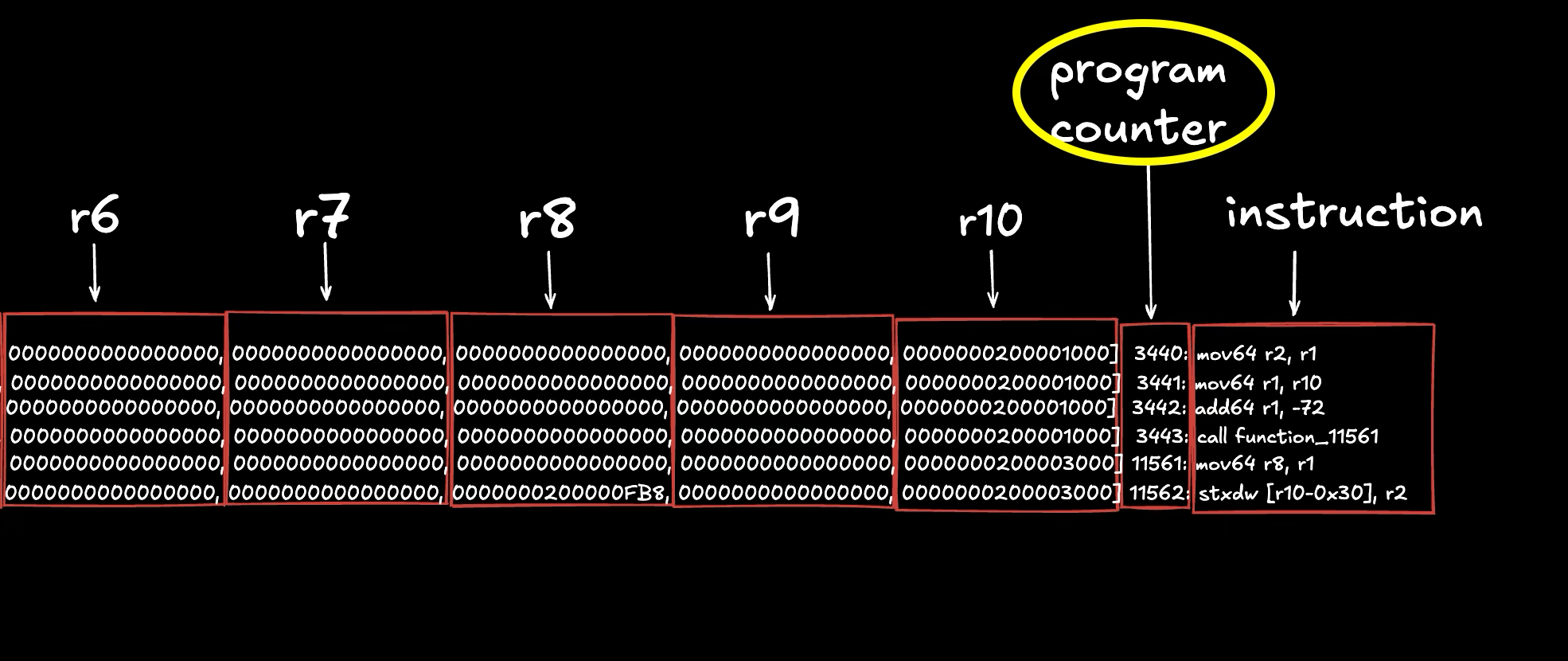
EVM बाइटकोड के विपरीत जहां निष्पादन पहले PC से शुरू होता है, Solana बाइटकोड में, निष्पादन वहीं से शुरू होता है जहां entrypoint जंप लेबल होता है (हम अगले ट्यूटोरियल में इस पर चर्चा करेंगे, लेकिन आप इसे देखने के लिए हमारे द्वारा पहले जनरेट की गई output.txt फ़ाइल में <entrypoint> खोज सकते हैं)। आपके प्रोग्राम को लागू (invoke) करते समय Solana रनटाइम सीधे इस लेबल पर जंप करता है। यदि आप हमारे निष्पादन ट्रेस को दर्शाने वाली ऊपर दी गई छवि को देखते हैं, तो आप देखेंगे कि पहला इंस्ट्रक्शन mov64 r2, r1 PC 0 के बजाय एक गैर-शून्य (non‑zero) PC (इस ट्रेस में 3440) पर है। इसका मतलब है कि PC 0 से PC 3439 तक का बाइटकोड संकलित (compiled) प्रोग्राम में मौजूद है लेकिन जब तक स्पष्ट रूप से उस पर जंप न किया जाए, तब तक निष्पादित नहीं होता है।
उस छोड़े गए (skipped) भाग में क्या है? इसमें अन्य लेबल किए गए कोड ब्लॉक (जैसे हेल्पर फ़ंक्शंस, एरर हैंडलिंग रूटीन, या Anchor-जनरेटेड कोड) शामिल हैं जो केवल मुख्य निष्पादन पथ से जंप किए जाने पर ही निष्पादित होते हैं। यदि आप output.txt (पूर्ण बाइटकोड डंप) में <entrypoint> लेबल खोजते हैं, तो आप देखेंगे कि यह ऑफ़सेट 3440 पर परिभाषित है, और इसके पहले के ऑफ़सेट पर function_0, function_11561 जैसे अन्य लेबल परिभाषित हैं। रनटाइम <entrypoint> पर निष्पादन शुरू करता है, फिर आवश्यकतानुसार इन अन्य लेबलों पर जंप करता है (आप ऊपर दिए गए ट्रेस में call function_11561 देख सकते हैं)। फिर से, हम अगले ट्यूटोरियल में entrypoint पर चर्चा करेंगे।
यदि प्रोग्राम अपने कोड से कुछ भी लॉग नहीं करता है, तो लॉग कहाँ से आ रहा है?
हमने देखा है कि हमारा प्रोग्राम इंस्ट्रक्शन निष्पादन (instruction execution) और syscall लागत दोनों से compute units का उपभोग करता है। इसे बेहतर ढंग से समझने के लिए, हम पहले यह पहचानेंगे कि हमारे ट्रेस में लॉग कहाँ से आता है, फिर यह देखने के लिए स्पष्ट लॉगिंग (explicit logging) जोड़ेंगे कि विभिन्न syscalls कुल compute unit संख्या को कैसे प्रभावित करते हैं। इससे हम ठोस संख्याओं के साथ अपने सूत्र (instructions + syscall costs = total CU) को सत्यापित कर सकेंगे।
sol_log_ syscall के साथ प्रोग्राम क्या लॉग आउट करने का प्रयास कर रहा है? यह पता लगाने के लिए, आइए चल रहे Solana लॉग के साथ अपने टेस्ट वैलिडेटर के विरुद्ध एक टेस्ट चलाएं। (यदि आप इसे पहले से ही चला रहे हैं तो आप इस चरण को छोड़ सकते हैं):
# start up a test validator
solana-test-validator
# get solana logs running in a separate terminal
solana logs
एक अलग टर्मिनल में anchor test --skip-local-validator चलाएं। हमें Solana लॉग टर्मिनल में कुछ चीजें लॉग आउट होते हुए देखनी चाहिए और अंतिम लॉग हमें उत्तर देता है। किसी प्रोग्राम के लॉग को उस ट्रांज़ैक्शन के Log Messages: के अंतर्गत Program log: की एक कुंजी (key) होने के रूप में पहचाना जा सकता है।
ऊपर दिए गए उदाहरण में, उस ट्रांज़ैक्शन का आउटपुट जिसमें सख्ती से initialize को कॉल करना शामिल है, वह यह है:

इसे देखते हुए, इसके तीन गुण (properties) हैं:
- Signature: जो कि हस्ताक्षरकर्ता (signer) का सिग्नेचर है
- Status: क्या ट्रांज़ैक्शन सफल रहा
- Log Messages: उस विशेष कॉल से लॉग
हम ऊपर दिए गए लॉग आउटपुट के Log Messages अनुभाग में रुचि रखते हैं। इसके कुछ गुण भी हैं:
- First लाइन हमें इनवोक किए जा रहे प्रोग्राम की ID और 1 से शुरू होने वाली उसकी इनवोक डेप्थ (invoke depth) बताती है।
- Second to last लाइन हमें बताती है कि हमारे प्रोग्राम ने कितनी compute units की खपत की और उस ट्रांज़ैक्शन के लिए सेट की गई अधिकतम compute unit कितनी है।
- Last लाइन हमें बताती है कि क्या कॉल सफल रहा।
- Everything in between (इस मामले में, केवल एक पंक्ति) वास्तविक प्रोग्राम लॉग हैं। इन्हें आसानी से पहचाना जा सकता है क्योंकि ये हमेशा
Program xxx:से शुरू होते हैं जहाँxxxलॉग आउट करने के लिए उपयोग किए जाने वालेsyscallके आधार पर भिन्न हो सकता है।
हमारे ऊपर दिए गए मामले में, हमारे पास एक लॉग है जो बस हमें हमारे प्रोग्राम से इंस्ट्रक्शन का नाम बताता है या दूसरे शब्दों में, वह फ़ंक्शन जिसे हमने कॉल किया था। यह लॉग Anchor द्वारा स्वचालित रूप से डाला जाता है। हमारा प्रोग्राम कोड स्पष्ट रूप से किसी भी लॉगिंग फ़ंक्शन को कॉल नहीं करता है, लेकिन Anchor का मैक्रो एक्सपेंशन (macro expansion) एक sol_log_ syscall जोड़ता है जो फ़ंक्शन के चलने पर “Instruction: Initialize” प्रिंट करता है। यदि आपने बिना Anchor के नेटिव Rust में समान प्रोग्राम लिखा होता, तो आपको यह लॉग तब तक दिखाई नहीं देता जब तक कि आप इसे स्पष्ट रूप से नहीं जोड़ते।
यह देखते हुए कि Anchor हर फ़ंक्शन कॉल के लिए स्वचालित रूप से इंस्ट्रक्शन का नाम लॉग करता है, हर Anchor प्रोग्राम इनवोकेशन में कम से कम एक लॉग लाइन (इंस्ट्रक्शन का नाम) होगी।
syscall लागत को देखने के लिए स्पष्ट लॉगिंग (explicit logging) जोड़ना
अब चलिए अपनी स्वयं की लॉगिंग कॉल जोड़कर देखते हैं कि कई syscalls गणना को कैसे प्रभावित करते हैं। programs/compute_unit/Cargo.toml में एक डिपेंडेंसी के रूप में solana-program = "1.18.17" जोड़ें और हमारे प्रोग्राम कोड को इस प्रकार अपडेट करें:
use anchor_lang::prelude::*;
use solana_program::log::sol_log_compute_units;
declare_id!("CR33kP6d39mBZv1ryjufVXoRm6djnWW8uKoQXwU5kgDV"); // Run anchor sync to update your program ID
#[program]
pub mod compute_unit {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
sol_log_compute_units();
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize {}
इसके लिए टेस्ट चलाने पर, हम देख सकते हैं कि हमारे ट्रांज़ैक्शन के लिए solana log इस प्रकार आएगा:

हम देख सकते हैं कि अब हमारे पास 2 Program xxx: लॉग हैं। पहला हमारा सामान्य Instruction: Initialize लॉग है, और दूसरा दिखाता है कि जिस बिंदु पर sol_log_compute_units() को कॉल किया गया था, उस समय कितनी compute units बची थीं।
लॉग से, हम यह भी देखते हैं कि जब sol_log_compute_units() निष्पादित होता है तो 199,641 compute units शेष हैं। जब हम इस वैल्यू को compute unit सीमा (200,000) से घटाते हैं, तो हमें उस बिंदु तक पहुंचने के लिए खपत की गई 359 compute units प्राप्त होती हैं। हम इसे ब्रेक डाउन करेंगे और सत्यापित करेंगे कि ये 359 इकाइयाँ कहाँ गईं।
नोट: बची हुई compute units को लॉग करते समय, फॉर्मेट हमेशा Program consumption: X units remaining होता है।
Compute unit की गणना को ब्रेक डाउन करना
अपने प्रोग्राम में sol_log_compute_units() जोड़ने और एक नया ट्रेस उत्पन्न करने के बाद (आप ऐसा कर सकते हैं जैसा हमने पहले किया था)। trace.txt.0 से:
- निष्पादन गणना 0-172 है (लॉगिंग के बिना हमारे पहले के ट्रेस में 172 से बढ़कर, अब कुल 173 इंस्ट्रक्शन्स निष्पादित हुए)
- निष्पादन गणना 157 में
syscall sol_log_है (यह “Instruction: Initialize” लॉग करता है) - निष्पादन गणना 158 में
syscall sol_log_compute_units_है (यह शेष CUs को लॉग करता है)
ट्रेस आउटपुट में ये कहाँ दिखाई देते हैं, इसकी पुष्टि करने के लिए आप इन्हें स्वयं trace.txt.0 (sol_log_ और sol_log_compute_units_) में खोज सकते हैं।
अब यहाँ यह दिलचस्प हो जाता है। प्रत्येक syscall का एक रनटाइम चार्ज होता है। प्रोग्राम्स को हमेशा के लिए चलने से रोकने के लिए Syscalls में ये शुल्क होने चाहिए (यदि syscalls मुफ़्त होते, तो एक प्रोग्राम अनंत syscall लूप बना सकता था और नेटवर्क को जाम कर सकता था):
sol_log_की कीमत 100 CU है (syscall_base_costद्वारा यहाँ परिभाषित किया गया है)sol_log_compute_units_की कीमत भी 100 CU है (get_remaining_compute_units_costद्वारा यहाँ परिभाषित किया गया है)
इसलिए कुल खपत की गई compute units:
Instructions executed: 173
Runtime syscall charges: 200 (100 + 100)
---
Total compute units: 373
यह उस चीज़ से मेल खाता है जो वैलिडेटर लॉग दिखाते हैं: “consumed 373 of 200000 compute units”
लॉगिंग पॉइंट पर compute units को सत्यापित करना
याद रखें कि जब sol_log_compute_units() निष्पादित हुआ था तब लॉग ने “199641 units remaining” दिखाया था। इसका मतलब है कि उस बिंदु तक 359 इकाइयों की खपत हो चुकी थी (200,000 - 199,641 = 359)।
आइए सत्यापित करें कि यह सही है। ट्रेस को देखते हुए, sol_log_compute_units_ निष्पादन गणना 158 पर दिखाई देता है, जिसका अर्थ है:
- अब तक 159 इंस्ट्रक्शन्स निष्पादित हुए (निष्पादन गणना 0-158)
- पहले
sol_log_syscall से 100 CU शुल्क (निष्पादन गणना 157 पर) - स्वयं
sol_log_compute_units_से 100 CU शुल्क (निष्पादित होने पर लागू होता है) - कुल: 159 + 100 + 100 = 359 CU
उत्तम! यह पुष्टि करता है कि हमारा ट्रेस हमें दिखा रहा है कि वास्तव में प्रत्येक syscall कब होता है और निष्पादन के दौरान compute units कैसे जमा होते हैं।
ट्रेस में पैरामीटर हैंडलिंग का निरीक्षण करना
आइए हमारे वर्तमान प्रोग्राम से solana_program::log::sol_log_compute_units(); को हटाकर उसकी जगह solana_program::log::sol_log_64(1, 2, 3, 4, 5); को प्रतिस्थापित करें। यहाँ, हम इसके बजाय एक syscall के साथ पाँच 64-बिट संख्याओं को लॉग कर रहे हैं।
अब अपना टेस्ट चलाने पर, हम अपने प्रासंगिक लॉग इस प्रकार देख सकते हैं:

वास्तव में हमारे पास 2 लॉग हैं। हमारा सामान्य इंस्ट्रक्शन नाम लॉग और उम्मीद के मुताबिक हमारे 5 नंबर लॉग आउट हुए।
यदि हम अपना execution trace कमांड चलाते हैं और trace.txt.0 में syscall खोजते हैं, तो हमें दो प्रविष्टियाँ (entries) मिलती हैं। दूसरा sol_log_64_ का एक syscall है, जो हमारे द्वारा अभी किए गए कार्य से मेल खाता है।

Solana compute unit कोडबेस दिखाता है कि log_64_units की कीमत 100 यूनिट है, जो get_remaining_compute_units_cost के समान ही है। लेकिन ध्यान दें कि इसमें 5 अतिरिक्त compute unit लगते हैं (अब पहले की तरह 373 नहीं, बल्कि 378)। इसे इस तथ्य से आसानी से समझाया जा सकता है कि sol_log_64_ के syscall से ठीक पहले, हमारे पास 5 नए इंस्ट्रक्शन्स हैं। हम इसे नीचे दिखाते हैं।
एक बार फिर, रजिस्टरों की वैल्यूज को अधिक स्पष्ट बनाने के लिए छवियों को विभाजित किया गया है:


यह स्वयं स्पष्ट (self-explanatory) है। छवि से, हम पांच mov इंस्ट्रक्शन्स देखते हैं जो रजिस्टर r1-r5 में पांच नंबर स्टोर करते हैं। वे नंबर बिल्कुल वही हैं जो हमने लॉग किए थे।
यह लेख Solana development पर एक ट्यूटोरियल श्रृंखला का हिस्सा है