Solana 程序并不强制要求特定的代码库结构,因此代码的组织通常取决于开发者的偏好和程序的复杂程度。事实上,正如我们在本系列文章中已经看到的,一个 Solana 程序可以仅作为一个单一的 lib.rs 文件存在。
但随着程序复杂度的增加,你会希望将逻辑和数据分离到具有上下文关联的文件以及清晰的文件夹结构中,从而使代码更容易查找、维护和扩展。
Solana 开发生态系统遵循一种通用的模式来组织程序的不同部分。本文将教你如何按照这种模式来组织 Anchor 程序和原生 Solana 程序。
Solana 程序结构的组成部分
Solana 程序的基本单元结构
每个 Solana 程序都是一个 Rust Cargo 库 crate。这意味着其默认结构始于一个 Cargo 项目,其中包含定义依赖项和构建配置的 Cargo.toml,以及包含程序逻辑的 lib.rs。你可以通过运行 cargo init --lib my_program 命令来生成这个结构,生成的程序结构将如下所示:
my_program/
├── Cargo.lock
├── Cargo.toml
└── src
└── lib.rs
要使其成为一个 Solana 程序,我们需要将以下代码添加到 Cargo.toml 文件中。
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.0.0"
以上配置的含义如下:
- 带有
crate-type = ["cdylib", "lib"]的[lib]部分告诉 Cargo 将程序同时编译为动态库(cdylib,这是 Solana 部署为.so文件所要求的格式)和标准 Rust 库(lib,用于本地测试或在程序间重用逻辑)。 solana-program = "2.0.0"依赖项引入了 Solana SDK crates,它们提供了对 Solana 运行时类型、宏和用于编写链上程序的辅助函数的访问。
Solana 程序的组件
要想正确理解如何构建 Solana 程序的代码库结构,让我们首先了解构成 Solana 程序的逻辑组件****。每个程序通常包括以下部分:
- Entry point(入口点):定义了 Solana 运行时将调用的第一个函数。
- Instructions(指令):定义了程序可以执行的操作以及输入数据的序列化和反序列化方式,即函数参数的结构是如何组织的。
- Instruction processing(指令处理):实现了执行每条指令的逻辑——这是核心计算发生的地方。
- Accounts(账户):描述了链上数据的布局。每种账户类型都指定了它持有的状态以及它是如何被序列化的(通常直接使用
borshcrate 或Anchor宏)。我们还需要定义我们将要交互的账户。 - Error handling(错误处理):提供具描述性的错误代码,以简化调试和客户端的错误解释。
- Tests(测试):验证你的程序在本地部署时是否按预期运行。
我们可以用代表上述概念的文件来构建一个简单的 Solana 程序,如下所示。在这个结构中,lib.rs 作为程序的根;它暴露模块并将它们链接在一起。entrypoint.rs 文件定义了 Solana 运行时在调用程序时所执行的函数。这个入口点函数按照惯例命名为 process_instruction,它实现了一个调度器,将每条传入的指令路由到其对应的处理程序(如之前的教程中所述)。
其余每个文件对应于上述的逻辑组件之一。
program/
├── src/
│ ├── entrypoint.rs // Program entry point (process_instruction)
│ ├── instruction.rs // Instruction enum and data structures
│ ├── processor.rs // Business logic for each instruction
│ ├── state.rs // Account data structures
│ ├── error.rs // Custom error types
│ └── lib.rs // Module declarations and re-exports
虽然这些文件名可以是任意的,但约定俗成的做法是使用与正在实现的概念相关的名称。
上述结构在 Anchor 程序和原生 Solana 程序中都很相似。主要区别在于 Anchor 使用宏来自动生成入口点和处理器,而在原生 Solana 程序中,你需要手动定义它们。这种结构适用于简单的程序,但随着程序规模的增长,你将拥有多个指令、处理器或状态,这意味着你可能需要将它们组织到文件夹中。
让我们深入探讨应该如何组织一个 Solana 程序。
Anchor 项目结构
Anchor 通过抽象原生 Solana 程序所需的大部分样板代码,简化了 Solana 程序的开发。它还提供了一个一致的项目模板,支持从编写程序到构建、测试和部署的整个工作流程。
下面是一个典型的 Anchor 项目结构,在本系列中你已经多次见过。
├── Anchor.toml
├── app
├── Cargo.lock
├── Cargo.toml
├── migrations
│ └── deploy.ts
├── package.json
├── programs
│ ├── hello-program
│ │ ├── Cargo.toml
│ │ ├── src
│ │ │ └── lib.rs
│ │ └── Xargo.toml
│ ├── token_vault
│ ├── Cargo.toml
│ ├── src
│ │ └── lib.rs
│ └── Xargo.toml
├── tests
│ └──hello-program.ts
├── tsconfig.json
└── yarn.lock
此结构中的每个部分在 Anchor 的工作流程中都有特定的作用:
Anchor.toml文件定义了构建和部署设置migrations文件夹存储部署脚本tests目录包含在本地验证节点上运行的集成测试app目录可以包含与已部署程序交互的客户端代码
请注意,Anchor 中的 programs 目录包含的子目录反映了我们之前讨论过的基本 Cargo 样板结构,之前的结构仅针对单个程序。
Anchor 项目的结构使你可以在一个项目内处理多个链上 Solana 程序。下图对比了典型的 Rust Cargo 项目与 Anchor 组织其项目的方式。
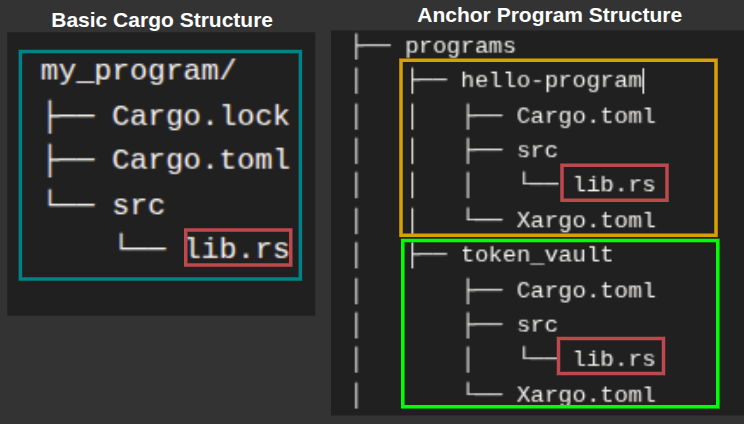
Anchor 结构与原生 Solana 结构的区别
- Anchor 生成的这些文件已完全配置好以供立即编译。你在创建项目后即可直接运行
anchor build并获得一个可运行的程序二进制文件。 - 对于使用 Cargo 设置的原生 Solana 程序,正如我们之前讨论的那样,你需要通过向
Cargo.toml添加依赖项和 crate 类型设置,手动将 Cargo 样板配置为 Solana 程序。如果你想在一个项目中运行多个程序,你需要一个类似于 Anchor 的programs目录。尽管你可以使用任何名称,但通常约定使用programs这个名称来存放程序目录,并通过每个程序各自的Cargo.toml文件对其进行配置。
请注意,在 Anchor 生成的项目结构中存在 Xargo.toml 文件。
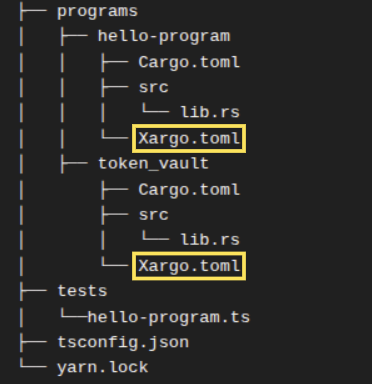
它们是 Anchor 的默认配置文件,负责处理 Anchor 程序如何被编译成 Extended Berkeley Packet Filter (eBPF) bytecode。我们将在下一节中了解更多相关内容。
Anchor 如何处理到 eBPF 的交叉编译
每个程序内部的 Xargo.toml 文件告诉 Rust 如何针对 Solana 的区块链环境编译你的代码。你的 Solana 程序运行在验证节点的 Solana Virtual Machine (SVM) 中,该虚拟机执行 Extended Berkeley Packet Filter (eBPF) bytecode。
当你在你的机器上编写 Rust 代码并对其进行编译时,Rust 编译器通常会生成针对你计算机处理器(如 x86 或 ARM)的指令。但是 Solana 验证节点无法执行这些指令。它们只理解 eBPF 字节码。
这种针对不同架构的编译过程被称为交叉编译。Xargo.toml 文件指定了 Rust 编译器应该如何为 eBPF 而不是你的本地机器构建代码。该文件控制着 Rust 标准库的哪些部分会被包含在最终编译的程序中。
Solana 程序有严格的大小限制 (10 MB),因此 Xargo.toml 配置可确保编译后的程序仅包含你程序所需的内容。当你运行 anchor init {project-name} 或 anchor new {program-name} 时,Anchor 会自动生成 Xargo.toml 文件。你不需要修改它。Xargo.toml 文件的内容如下所示:
[target.bpfel-unknown-unknown.dependencies.std]
features = []
目标名称 bpfel-unknown-unknown 是一个 Rust 编译目标三元组 (Rust compilation target triple)。它告诉 Rust 编译器它正在为哪种机器和环境进行构建。它包含 3 个部分,由连字符分隔。以下是每个部分的含义:
bpfel- 针对具有小端字节序的 BPF 架构进行编译unknown- 第一个 unknown 意味着,不要针对任何特定的操作系统进行编译unknown- 最后一个 unknown 意味着,不要针对任何特定的 ABI (应用程序二进制接口) 进行编译
空的 features (features = []) 数组意味着你正在使用的是针对区块链部署进行了优化的最小版本的标准库。
原生 Solana 程序处理交叉编译的方式有所不同。你可以使用 cargo-build-sbf 来构建你的程序,它将你的 Rust 代码编译成 eBPF 字节码,而不需要单独的 Xargo.toml 文件。
Anchor 如何组织多个程序
Anchor 使用 Cargo workspace 来管理一个项目中的多个程序。工作区 (workspace) 允许你开发共享依赖项和构建配置的几个相关程序。
Anchor 使用两种不同用途的 Cargo.toml 文件。根目录的 Cargo.toml 定义了工作区结构和共享的构建配置。每个程序目录包含其自己的 Cargo.toml,用于声明该特定程序的依赖项。
即使两个 Solana 程序使用相同的 Rust crate,每一个也必须在其程序目录内的 Cargo.toml 文件中单独声明它。你不能在工作区级别仅声明一次依赖项就让所有程序继承它。
如果在同一个 Anchor 工作区中的两个程序(例如 A 和 B)依赖于同一个 crate,它们可能会以不同的方式使用它。程序 A 可能使用一个库函数,而程序 B 使用五个。这会影响在编译期间可以修剪掉多少库代码。
但程序会共享构建配置。 工作区依赖项和构建配置在位于你的 Anchor 项目根目录的 Cargo.toml 文件中定义,其中还包含几个默认设置,如下面的屏幕截图所示。
根目录 Cargo.toml 文件中的 [workspace] 部分定义了一个 members 数组,它指定了属于工作区一部分的特定目录。请注意它包含 [”programs/”],这是默认的 Solana 程序目录名称。下面的 Cargo 文件是一个根 Cargo.toml 文件:
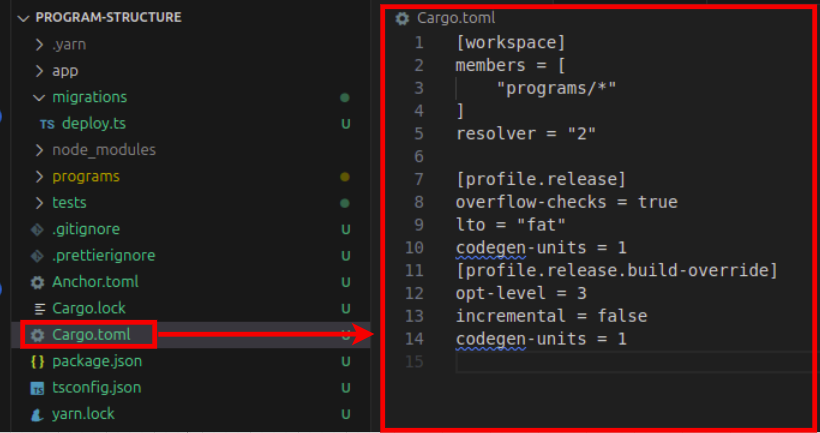
以下是根 Cargo.toml 文件中各个部分的含义:
[workspace] 部分定义了哪些程序属于工作区,并控制 Cargo 如何处理跨多个相关包的依赖项。
members = ["programs/*"]-programs中的每一个子目录都属于此工作区resolver = "2"- 该设置告诉 Cargo 使用其较新的依赖关系解析算法(版本 2)
[profile.release] 部分控制在 release 模式下构建时的编译设置。它允许你配置优化级别、调试信息和代码生成行为
overflow-checks = true- 在发布构建中保持启用算术溢出检查,防止可能破坏程序状态的整数溢出错误lto = "fat"- 此设置启用了链接时优化 (LTO),它在编译器链接阶段(即编译器将所有编译后的代码组合成最终可执行文件的过程)对整个程序进行分析,以删除未使用的代码和内联函数,从而缩减最终二进制文件的大小。如果我们不想要更快的 LTO 但伴随较少的优化,我们可以将lto参数设置为thincodegen-units = 1- 在一次遍历中编译你的整个程序,而不是将编译工作分割成多个并行的块。该值越高,编译将被划分成的块就越多。将其设置为1允许编译器一次性在整个代码库上执行优化,从而生成更小且优化程度更高的二进制文件,但代价是编译时间更长。默认的 Rust 设置是codegen-units = 16,这会加快构建速度,但可能导致稍大的二进制文件。
[profile.release.build-override] 部分专门为构建脚本指定编译设置,构建脚本是在主代码编译之前运行以生成代码或配置构建的程序。
opt-level = 3- 对构建脚本应用最大级别的优化incremental = false- 禁用增量编译。每次编译都是从头到尾完整执行。这会减慢编译时间,但降低了遗留产物干扰编译过程的风险codegen-units = 1- 对构建脚本应用相同的单一构建单元优化
Anchor 自动生成的代码
整个 Anchor 项目及其内部的单个程序都不包含显式的 entrypoint.rs 和 processor.rs 文件,而这两个文件是 Solana 项目中的关键要素。正如我们前面所讨论的,lib.rs 文件内的 #[program] 属性会自动生成入口点源代码以及处理指令解码、分发和账户反序列化的逻辑(在原生 Solana 程序中,这通常位于 processor.rs 文件内)。
下面的代码展示了 #[program] 属性是如何在 Anchor 程序中使用的:
#[program]
pub mod hello_program {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
msg!("Program initialized!");
Ok(())
}
}
Anchor 1.0 中的更优项目组织
Anchor 1.0 引入了一种项目布局,鼓励在每个程序内部实现更好的文件组织形式。
在 Anchor 1.0 中运行 anchor init,会在单独的模块中生成所有的标准项目组件,如 instructions、state、errors 和 constants。
这一改变有助于新开发者学习用于组织大型 Solana 程序的更整洁的模式。你仍然可以使用 --template single 标志(anchor init --template single)来生成旧的单文件布局。
以下是新的默认结构示例:
programs
└── vote
├── Cargo.toml
└── src
├── instructions
│ ├── initialize.rs
│ └── mod.rs
├── state
│ └── mod.rs
├── constants.rs
├── error.rs
└── lib.rs
有两个新增项需要注意:每个目录内的 mod.rs 文件和 initialize.rs 指令模块。我们将在后面的小节中讨论它们。
采用这种新结构后,你不再以混合了账户和指令的单个 lib.rs 文件来启动程序。取而代之的是,你的 state(状态)存放在其自己的目录中,并且每个 instruction(指令)都位于其自己的模块中。
下面的例子展示了 Anchor 默认使用的较旧的单文件模式,其中程序逻辑和账户类型一起放在 lib.rs 中。
use anchor_lang::prelude::*;
declare_id!("6uAEFiYjmgJhCCqw8JPH8chZRWJPzHFBJYuZFMWaML3w");
#[program]
pub mod program_structure {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
msg!("Greetings from: {:?}", ctx.program_id);
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize {}
标准 Solana 程序结构
到目前为止,你已经看到了 Solana 程序的各个部分分别执行什么操作,以及 Anchor 是如何自动组织它们的。但即使没有 Anchor,你也可以遵循一致的、模块化的布局,以确保你的程序是易于维护的。
我们研究了一些顶级 Solana 项目构建程序的方式,并注意到了一种促进协作、可维护性和可扩展性的一致模式。一个典型的 Solana 程序遵循下面的结构,仅在原生 Solana 程序中才显式定义入口点和处理器目录。
program/
├── Cargo.toml
└── src/
├── entrypoint.rs
├── instructions/
│ ├── mod.rs
│ ├── initialize.rs
│ └── transfer.rs
├── processor/
│ ├── mod.rs
│ ├── initialize.rs
│ └── transfer.rs
├── state/
│ ├── mod.rs
│ ├── account.rs
│ └── config.rs
├── error.rs
├── utils/
│ ├── mod.rs
│ ├── pda.rs
│ ├── math.rs
│ └── validation.rs
└── lib.rs
我们在上一节以及上述结构中引入了新文件:针对每个目录的 mod.rs 和 initialize.rs。让我们来解释一下它们:
mod.rs 文件
mod.rs 文件在 Rust 中用作某个目录的模块声明点。当你将相关代码组织到如 instructions/ 这样的文件夹中时,Rust 不会自动识别里面的文件作为你的程序的一部分。你需要显式地告诉 Rust 哪些文件应该被编译并被允许你的代码库的其他部分访问,这就是 mod.rs 的工作(它不是随意的,当通过目录定义模块时,Rust 期望正是这个文件名)。
下面是 instructions/mod.rs 的样子:
pub mod initialize;
pub mod transfer;
每一行声明目录中的一个文件作为模块。pub 关键字使这些模块可以在 instructions 目录之外被公开访问。如果没有这些声明,Rust 不会编译 initialize.rs 或 transfer.rs,你程序的其他部分也无法导入它们的内容。
随后,在你的 lib.rs 文件中,你公开 instructions 模块以使其在你的整个程序中可用:
pub mod instructions;
pub use instructions::*;
这个模式在你程序的每一个目录中重复。
processor/mod.rs文件声明了处理器模块state/mod.rs声明了状态模块- 而
utils/mod.rs声明了工具模块。
instructions/initialize.rs 文件
Anchor 的 lib.rs 文件中的 initialize 函数是 Anchor 用于为指令设置程序的初始状态的一种约定俗成的做法。我们可以将这种状态初始化迁移到一个不同的文件中,以保持你的 lib.rs 文件整洁。
下面是 lib.rs 文件中默认生成的 initialize 函数的样子:
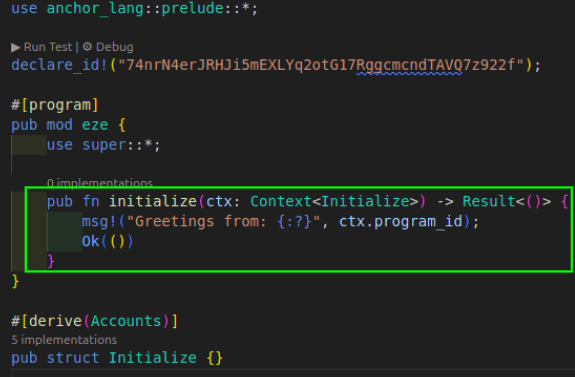
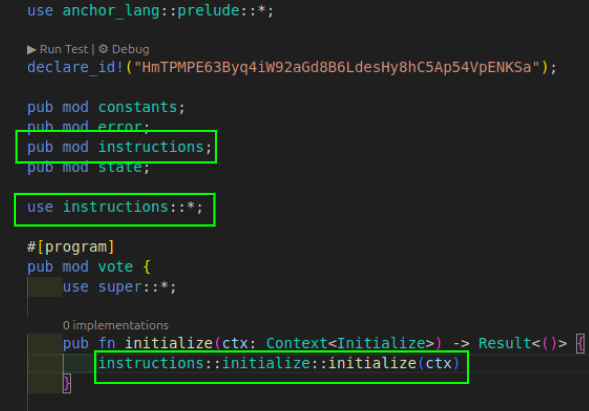
在 Anchor 项目中,当你已将其移动到专用的 initialize.rs 文件并将其设为 instructions 目录中的模块时,下面是你在 lib.rs 文件中使用 initialize 函数的方式:
processors 目录
在原生 Solana 中,processor/ 实现了指令处理程序。每个 processor 模块都与 instructions/ 中的一个 instruction 模块相对应。
模块化的 Anchor 结构
适用于单个程序的标准 Anchor 风格的程序结构将如下所示,没有入口点或处理器文件。此结构反映了 Anchor 1.0 版本的项目结构:
programs/
└── my_program/
├── Cargo.toml
└── src/
├── lib.rs
├── instructions/
│ ├── transfer.rs
│ └── mod.rs
├── state/
│ ├── config.rs
│ ├── account.rs
│ └── mod.rs
├── error.rs
├── utils/
│ ├── mod.rs
│ ├── pda.rs
│ ├── math.rs
│ └── validation.rs
无论它是原生 Solana 程序还是 Anchor 程序,有了这种结构,开发者都会更容易定位相关的逻辑、梳理程序流,并在不破坏现有行为的前提下扩展功能。
本文是 Solana 开发教程系列的一部分