Este artículo explica cómo el BPF loader serializa las entradas de las instrucciones de los programas, cómo el entrypoint las recibe y cómo los programas deserializan esa entrada para leer el program ID, las cuentas y los datos de la instrucción. En la segunda parte de este artículo, cubriremos cómo los programas enrutan las instrucciones entrantes a los handlers adecuados y el código de soporte que el entrypoint configura para hacerlo posible.
El BPF Loader de Solana
El BPF Loader es uno de los programas nativos de Solana, con su implementación aquí. Es responsable del despliegue, las actualizaciones, la carga y la ejecución de programas BPF on-chain.
Los programas nativos son programas que forman parte de la implementación del validador y pueden ser actualizados como parte de las actualizaciones del clúster (por ejemplo, para corregir errores o añadir funcionalidades).
Solana tiene múltiples BPF Loaders, pero los más antiguos (V1 y V2) están obsoletos y ya no se usan para nuevos despliegues. El BPF Loader Upgradeable es el estándar actual, y a menos que se indique lo contrario, “el BPF Loader” en este artículo se refiere a él — incluyendo el formato de serialización descrito aquí.
El BPF Loader configura el entorno de ejecución e inicia la máquina virtual de Solana. Luego, la máquina virtual llama al entrypoint del programa y comienza la ejecución del programa.
El Entrypoint del Programa
Recordemos que en el artículo anterior, cuando analizamos la traza de ejecución, la ejecución del bytecode comenzó en una etiqueta <entrypoint>, el símbolo que marca la función entrypoint del programa. Aquí es donde comienza la ejecución.
En los programas de Anchor, la macro #[program] genera automáticamente este entrypoint por ti. La macro crea la función entrypoint, configura el despacho de instrucciones (enrutando hacia tus handlers de instrucciones basándose en los primeros 8 bytes de los datos de la instrucción) y maneja la deserialización de entrada y la serialización de salida. Nunca ves ni escribes el entrypoint tú mismo.
En los programas nativos de Rust, debes definir el entrypoint tú mismo usando la macro entrypoint! del crate solana_program, y luego manejar el despacho de instrucciones tú mismo.
La macro entrypoint! genera el código que configura el punto de entrada del programa. Para entender cómo se ve este código, echemos un vistazo a la firma de la función generada:
#[no_mangle]
pub unsafe extern "C" fn entrypoint(input: *mut u8) -> u64;
La función toma un solo parámetro (input), un puntero a las entradas de instrucciones serializadas y almacenadas en la memoria de la VM. La entrada de la instrucción consta de tres parámetros:
program_id: La clave pública del programa que está siendo llamadoaccounts: Un array de cuentas a las que el programa puede accederinstruction_data: Los datos específicos de la instrucción (similar al calldata en Solidity)
Es posible que reconozcas estos parámetros de entrada de instrucciones exactamente como los mismos datos que proporcionamos en nuestro archivo instructions.json en el artículo anterior al generar las trazas de ejecución:
{
"accounts": [],
"program_id": "HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC",
"instruction_data": [175, 175, 109, 31, 13, 152, 155, 237]
}
Cómo el BPF Loader Serializa las Entradas de Instrucciones del Programa
Cuando invocas un programa de Solana, el entorno de ejecución de Solana (a través del BPF loader) serializa las entradas de la instrucción (el program_id, la lista de cuentas y los instruction_data) junto con el estado on-chain de cada cuenta (su saldo de lamports, owner, bytes de datos y otros metadatos) en un array de bytes y lo almacena en la memoria de la VM. Un puntero al inicio de este array se pasa al entrypoint del programa como el parámetro input. El programa invocado luego deserializa este array de bytes para recuperar el program_id, las cuentas y los datos de la instrucción que necesita para ejecutarse.
El BPF loader utiliza un formato de serialización conocido, y los programas de Solana deben seguir exactamente el mismo formato al deserializar las entradas de instrucciones (discutiremos esto más adelante).
En los programas de Anchor, la macro #[program] genera automáticamente el código de deserialización que sigue este formato. En los programas nativos de Rust, la macro entrypoint! del crate solana_program proporciona una función interna deserialize que implementa este formato. De cualquier manera, la lógica de deserialización se te proporciona, por lo que no tienes que implementarla desde cero.
Ahora veremos paso a paso cómo el BPF loader serializa los datos de entrada del programa en memoria. Todos los valores están codificados en little-endian, así que tenlo en cuenta a medida que examinamos el diseño. Las secciones a continuación desglosan cómo está estructurada la entrada de la instrucción.
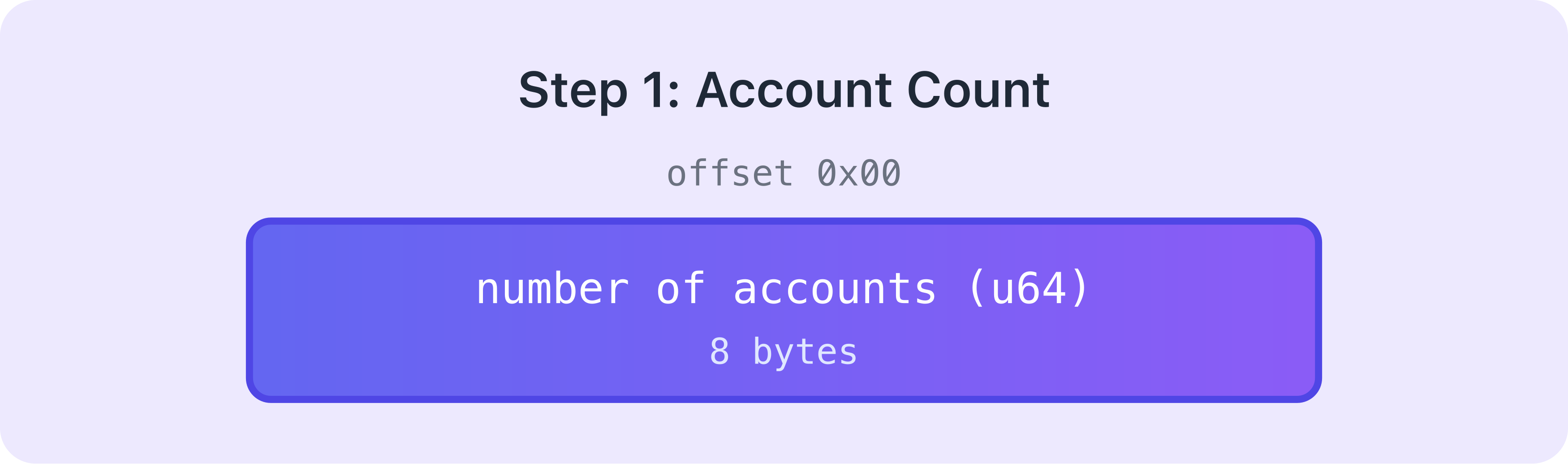
Recuento de cuentas
Lo primero que se serializa es cuántas cuentas necesita esta llamada al programa. Esto ocupa 8 bytes.
Luego, se serializa cada cuenta en el array de cuentas
Después del recuento de cuentas, el loader serializa cada cuenta una por una. Cada cuenta comienza con un marcador de duplicado de 1 byte que indica si esta es la primera aparición de esta cuenta dentro del array de cuentas o si es un duplicado (lo que significa que la misma cuenta aparece múltiples veces en el array de cuentas).

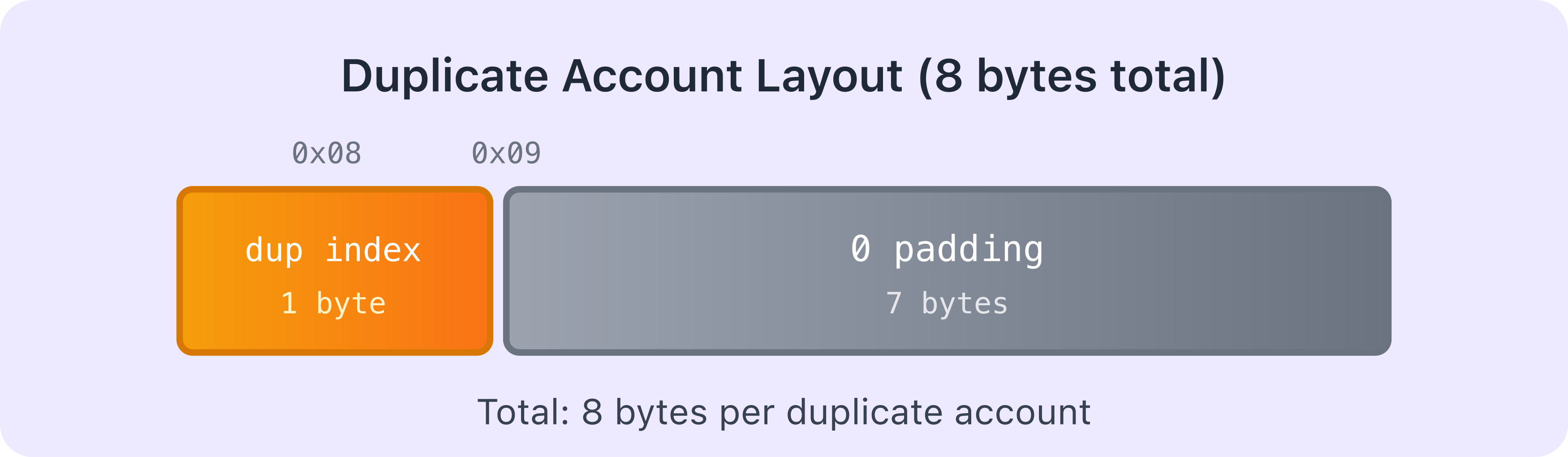
Cuentas duplicadas
Si la cuenta es un duplicado (es decir, esta cuenta exacta ya fue serializada anteriormente en el array de cuentas), el loader no vuelve a serializar todos sus datos. En cambio, el marcador de 1 byte contiene el índice de donde apareció esta cuenta por primera vez, seguido de 7 bytes de padding. Por lo tanto, el tamaño total de un duplicado es de 8 bytes (1 byte de índice + 7 bytes de padding).
Cuentas no duplicadas
Si esta es la primera aparición de esta cuenta en el array, el loader serializa toda su información. Aquí es donde el tamaño de todos los datos serializados se vuelve variable porque las diferentes cuentas contienen diferentes cantidades de datos.
El loader escribe cada cuenta en secuencia. Comienza con un marcador de no duplicado de 1 byte (0xff), seguido de dos flags de 1 byte que indican si la cuenta es signer y writable, y luego 4 bytes de padding — 7 bytes en total para esta sección inicial. Después de eso, escribe la public key de la cuenta (32 bytes), el campo lamports (8 bytes) y la longitud de los datos (8 bytes). Esos campos suman 55 bytes antes de cualquier dato de la cuenta.
A continuación, escribe los bytes de datos de la cuenta (x bytes). Una vez escrito esto, el loader añade 10,240 bytes de espacio reservado (para que la cuenta pueda crecer durante la ejecución sin necesidad de reasignación) más y bytes de padding de alineación — donde y es lo que sea necesario para alinear el siguiente campo a un límite de 16 bytes (definido como BPF_ALIGN_OF_U128 en el código fuente de serialización). Después del padding, escribe la public key del owner de la cuenta (32 bytes), el flag executable de 1 byte y el rent epoch de 8 bytes.
Por lo tanto, el tamaño total para una cuenta no duplicada es: 7 (encabezado) + 32 (pubkey) + 8 (lamports) + 8 (data_len) + x (datos) + 10,240 + y (reservado + alineación) + 32 (owner) + 1 (executable) + 8 (rent epoch) = 10,336 + x + y bytes.

Este patrón se repite para cada cuenta no duplicada en el array de cuentas.
Después de que todas las cuentas son serializadas (no duplicadas o duplicadas), se serializan los datos de la instrucción
Una vez que todas las cuentas están serializadas, el loader serializa los datos de la instrucción. Primero, escribe la longitud de los datos de la instrucción como un entero sin signo de 8 bytes (u64), y luego los propios datos de la instrucción (z bytes, lo cual varía según la instrucción). Total: 8 + z bytes.

Finalmente, se coloca el ID del programa
Lo último que se serializa es el program ID (la clave pública del programa que está siendo llamado). Esto es siempre de 32 bytes.

Si consideramos una entrada serializada con una sola cuenta no duplicada, el tamaño total de toda la entrada serializada será: 8 bytes (recuento de cuentas) + 10,336 bytes (campos fijos de la cuenta + espacio reservado + rent epoch) + x bytes (datos reales de la cuenta) + y bytes (padding de alineación) + 8 bytes (longitud de los datos de la instrucción) + z bytes (datos reales de la instrucción) + 32 bytes (program ID) = 10,384 + x + y + z bytes en total. Si tienes múltiples cuentas, sumas el tamaño de los datos serializados de cada cuenta.

El diagrama a continuación muestra la estructura completa de la entrada serializada (cuenta no duplicada):
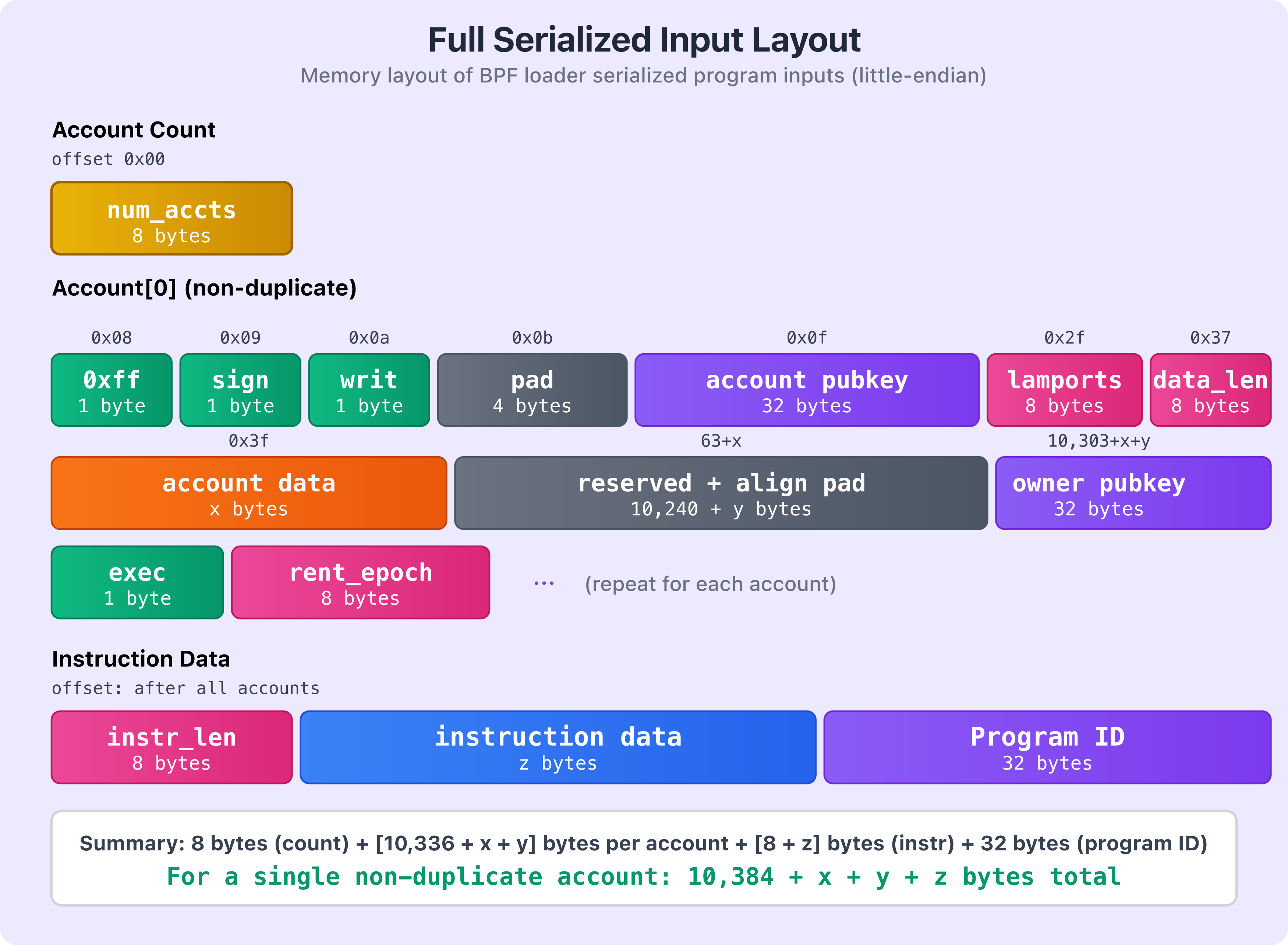
El diagrama muestra cómo los diferentes componentes están dispuestos en la memoria. El amarillo muestra el recuento de cuentas, el verde muestra los flags del encabezado, el morado muestra las claves públicas (incluido el program ID), el rosa indica los campos numéricos como lamports y longitudes de datos, el naranja muestra los datos de la cuenta, el azul muestra los datos de la instrucción y el gris representa el padding y las secciones reservadas.
Como se mencionó anteriormente, si hay múltiples cuentas en el array de cuentas, el patrón se repite. Después de los datos de la primera cuenta, tendríamos otro flag de duplicado de 1 byte para la segunda cuenta. Si no es un duplicado (0xff), le sigue la estructura completa de la cuenta. Si es un duplicado, el valor de 1 byte contiene el índice de su primera aparición en el array de cuentas, seguido de 7 bytes de padding.
Ten en cuenta que el tamaño total de los datos serializados no es fijo; depende de cuántas cuentas estés pasando, cuántos datos contenga cada cuenta y del tamaño de los datos de tu instrucción.
Cómo los Programas Deserializan las Entradas de las Instrucciones
Ahora que hemos visto cómo el BPF loader serializa las entradas de las instrucciones en un array de bytes, veamos cómo tu programa deserializa este array de bytes.
Cuando el runtime invoca el entrypoint del programa, llama a una función deserialize que convierte el array de bytes de entrada cruda en el program ID, las cuentas y los datos de la instrucción necesarios para la ejecución.
Esta función de deserialización vive en el Solana SDK, y es invocada por la macro entrypoint! del crate de Solana. En los programas nativos de Solana en Rust, esta macro define el entrypoint del programa y llama al deserializador del SDK antes de ceder el control al procesador de instrucciones (discutimos esto en la siguiente sección).
La función de deserialización lee a través del array de bytes serializado por el BPF loader y extrae el program ID (como una Pubkey), las cuentas (como un vector de AccountInfo) y los datos de la instrucción (como un byte slice).
pub unsafe fn deserialize<'a>(input: *mut u8) -> (&'a Pubkey, Vec<AccountInfo<'a>>, &'a [u8]) {
let mut offset: usize = 0;
// Number of accounts present
#[allow(clippy::cast_ptr_alignment)]
let num_accounts = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
// Account Infos
let mut accounts = Vec::with_capacity(num_accounts);
for _ in 0..num_accounts {
let dup_info = *(input.add(offset) as *const u8);
offset += size_of::<u8>();
if dup_info == NON_DUP_MARKER {
let (account_info, new_offset) = deserialize_account_info(input, offset);
offset = new_offset;
accounts.push(account_info);
} else {
offset += 7; // padding
// Duplicate account, clone the original
accounts.push(accounts[dup_info as usize].clone());
}
}
// Instruction data
let (instruction_data, new_offset) = deserialize_instruction_data(input, offset);
offset = new_offset;
// Program Id
let program_id: &Pubkey = &*(input.add(offset) as *const Pubkey);
(program_id, accounts, instruction_data)
}
Ahora desglosaremos este bloque de código paso a paso.
Comprendiendo el Proceso de Deserialización
Firma de la Función
pub unsafe fn deserialize<'a>(input: *mut u8) -> (&'a Pubkey, Vec<AccountInfo<'a>>, &'a [u8]) {
La función deserialize está marcada como unsafe porque implica la manipulación de punteros crudos. Toma input, un puntero a los bytes serializados en memoria, y devuelve tres valores:
- Una referencia a la
Pubkeydel programa - Un vector de structs
AccountInfo(las cuentas usadas en la transacción) - Un byte slice que contiene los datos de la instrucción
Rastreando la Posición Actual
Primero, la función de deserialización crea una variable offset para rastrear su posición actual en el array de bytes input. Como sabemos por la forma en que el BPF loader serializa estos datos, los primeros 8 bytes (un u64) especifican el número de cuentas. La función lee este valor en num_accounts y luego avanza el offset en 8 bytes.
let mut offset: usize = 0;
// Number of accounts present
#[allow(clippy::cast_ptr_alignment)]
let num_accounts = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
Inicializando el Vector de Cuentas
A continuación, la función deserialize crea un vector con capacidad para num_accounts elementos. Esto es más eficiente que dejar que el vector crezca dinámicamente porque Rust no necesitará reasignar y copiar el vector entero a medida que se llena.
let mut accounts = Vec::with_capacity(num_accounts);
Deserializando Cada Cuenta
Después de crear un vector para contener las cuentas a deserializar, la función itera sobre cada cuenta y comprueba el flag de duplicado. Si es NON_DUP_MARKER (0xff), significa que es una cuenta única, por lo que llama a deserialize_account_info para leer la estructura completa de la cuenta (explicamos esto a continuación) en la variable del vector accounts. Si es un duplicado (el flag contiene un índice en su lugar), simplemente salta los 7 bytes de padding y copia la cuenta que ya fue deserializada en ese índice.
for _ in 0..num_accounts {
// 1 byte indicating if this is a duplicate account
// If not a duplicate, the value is 0xff (NON_DUP_MARKER)
// Otherwise, the value is the index of the account it duplicates
let dup_info = *(input.add(offset) as *const u8);
offset += size_of::<u8>();
if dup_info == NON_DUP_MARKER {
// Not a duplicate: deserialize the full account
let (account_info, new_offset) = deserialize_account_info(input, offset);
offset = new_offset;
accounts.push(account_info);
} else {
// Duplicate account: skip 7 bytes of padding and copy the original
offset += 7; // padding
accounts.push(accounts[dup_info as usize].clone());
}
}
La función auxiliar deserialize_account_info se define de la siguiente manera:
Esta función auxiliar recorre los bytes serializados en el orden exacto en que el BPF loader los escribió. Lee los tres flags booleanos (is_signer, is_writable, executable), salta los 4 bytes de padding, lee las dos claves públicas (la de la cuenta y el owner), lee los lamports y la longitud de los datos, y luego crea un slice que apunta a los datos de la cuenta. Después de eso, avanza el offset más allá de los propios datos de la cuenta, los 10,240 bytes de espacio reservado y el rent epoch de 8 bytes (que en realidad no se almacena en el struct AccountInfo—simplemente se salta). Finalmente, añade el padding de alineación para asegurar que la siguiente cuenta comience en una dirección alineada a 8 bytes.
unsafe fn deserialize_account_info<'a>(input: *mut u8, mut offset: usize) -> (AccountInfo<'a>, usize) {
// 1 byte boolean, true if account is a signer
let is_signer = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 1 byte boolean, true if account is writable
let is_writable = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 1 byte boolean, true if account is executable
let executable = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 4 bytes of padding
offset += size_of::<u32>();
// 32 bytes of the account's public key
let key: &Pubkey = &*(input.add(offset) as *const Pubkey);
offset += size_of::<Pubkey>();
// 32 bytes of the account owner's public key
let owner: &Pubkey = &*(input.add(offset) as *const Pubkey);
offset += size_of::<Pubkey>();
// 8 bytes unsigned number of lamports owned by the account
let lamports = &mut *(input.add(offset) as *mut u64);
offset += size_of::<u64>();
// 8 bytes unsigned number of bytes of account data
let data_len = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
// x bytes of account data (variable length)
let data = from_raw_parts_mut(input.add(offset), data_len);
offset += data_len;
// 10,240 bytes of reserved space (for account data growth)
offset += MAX_PERMITTED_DATA_INCREASE;
// 8 bytes rent epoch (skipped, not deserialized into AccountInfo)
offset += size_of::<u64>();
// Alignment padding to ensure next account starts at 8-byte boundary
offset += (offset as *const u8).align_offset(BPF_ALIGN_OF_U128);
(AccountInfo::new(key, is_signer, is_writable, lamports, data, owner, executable), offset)
}
Deserializando los Datos de la Instrucción y el Program ID
Después de deserializar todas las cuentas, la función deserialize pasa a los datos de la instrucción. Llama a la función auxiliar deserialize_instruction_data. Esta función auxiliar se define de la siguiente manera:
// Instruction data
let (instruction_data, new_offset) = deserialize_instruction_data(input, offset);
offset = new_offset;
Esta función auxiliar lee la longitud de 8 bytes de los datos de la instrucción, crea un slice apuntando a los bytes de los datos de la instrucción y devuelve tanto el slice como el offset actualizado.
unsafe fn deserialize_instruction_data<'a>(input: *mut u8, mut offset: usize) -> (&'a [u8], usize) {
// Read the length of the instruction data (first 8 bytes at the current offset)
let instruction_data_len = *(input.add(offset) as *const u64) as usize;
// Move the offset past the u64 length field, so it now points to the start of the instruction data
offset += size_of::<u64>();
// Create a slice pointing to the instruction data bytes
let instruction_data = from_raw_parts(input.add(offset), instruction_data_len);
// Move the offset past the instruction data itself
offset += instruction_data_len;
// Return the instruction data slice and the updated offset
(instruction_data, offset)
}
Finalmente, la función principal de deserialización (deserialize) extrae el program ID (los últimos 32 bytes) y devuelve los tres componentes que tu programa necesita: el program ID, el vector de cuentas y los datos de la instrucción.
// Program Id
let program_id: &Pubkey = &*(input.add(offset) as *const Pubkey);
Hemos explorado cómo el BPF loader de Solana serializa las entradas de instrucciones del programa en un array de bytes y cómo los programas las deserializan en el program ID, las cuentas y los datos de la instrucción. En la siguiente parte de este artículo, veremos qué sucede con estas entradas una vez que llegan al programa.
Este artículo es parte de una serie de tutoriales sobre desarrollo en Solana