本文解释了 BPF loader 如何序列化程序指令输入、entrypoint 如何接收它们,以及程序如何反序列化该输入以读取程序 ID、账户和指令数据。在本文的第二部分中,我们将介绍程序如何将传入的指令路由到适当的处理程序,以及 entrypoint 为实现这一点而设置的辅助代码。
Solana BPF Loader
BPF Loader 是 Solana 的原生程序之一,其实现位于这里。它负责在链上部署、升级、加载和执行 BPF 程序。
原生程序是验证节点实现的一部分,可以作为集群升级的一部分进行升级(例如修复错误或添加功能)。
Solana 有多个 BPF Loader,但较旧的版本(V1 和 V2)已被弃用,不再用于新部署。BPF Loader Upgradeable 是当前的标准,除非另有说明,本文中的“BPF Loader”均指代它——包括此处描述的序列化格式。
BPF Loader 设置执行环境并启动 Solana 虚拟机。然后,虚拟机调用程序 entrypoint,程序开始执行。
程序 Entrypoint
回顾在上一篇文章中,当我们分析执行轨迹时,字节码执行从一个 <entrypoint> 标签开始,这是标记程序 entrypoint 函数的符号。这就是执行开始的地方。
在 Anchor 程序中,#[program] 宏会自动为你生成此 entrypoint。该宏创建 entrypoint 函数,设置指令分发(根据指令数据的前 8 个字节路由到你的指令处理程序),并处理输入反序列化和输出序列化。你无需自己查看或编写 entrypoint。
在原生 Rust 程序中,你必须使用 solana_program crate 中的 entrypoint! 宏亲自定义 entrypoint,然后自行处理指令分发。
entrypoint! 宏生成用于设置程序入口点的代码。为了理解这段代码的样子,让我们看一看生成的函数签名:
#[no_mangle]
pub unsafe extern "C" fn entrypoint(input: *mut u8) -> u64;
该函数接受一个参数(input),这是指向存储在 VM 内存中的序列化指令输入的指针。指令输入由三个参数组成:
program_id:被调用程序的公钥accounts:程序可以访问的账户数组instruction_data:特定于指令的数据(类似于 Solidity 中的 calldata)
你可能会认出,这些指令输入参数与我们在上一篇文章中生成执行轨迹时,在 instructions.json 文件中提供的数据完全相同:
{
"accounts": [],
"program_id": "HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC",
"instruction_data": [175, 175, 109, 31, 13, 152, 155, 237]
}
BPF Loader 如何序列化程序指令输入
当你调用 Solana 程序时,Solana 运行时(通过 BPF loader)会将指令输入(program_id、账户列表和 instruction_data)以及每个账户的链上状态(其 lamports 余额、所有者、数据字节和其他元数据)序列化为字节数组,并将其存储在 VM 的内存中。指向此数组起点的指针会作为 input 参数传递给程序的 entrypoint。然后,被调用的程序反序列化该字节数组,以恢复其执行所需的 program_id、账户和指令数据。
BPF loader 使用一种已知的序列化格式,Solana 程序在反序列化指令输入时必须遵循完全相同的格式(我们稍后将对此进行讨论)。
在 Anchor 程序中,#[program] 宏会自动生成遵循此格式的反序列化代码。在原生 Rust 程序中,solana_program crate 中的 entrypoint! 宏提供了一个实现此格式的 deserialize 内部函数。无论哪种方式,反序列化逻辑都已经为你提供,因此你无需从头开始实现。
现在我们来梳理一下 BPF loader 是如何在内存中序列化程序输入数据的。所有值都以小端序(little-endian)编码,所以在我们检查布局时请记住这一点。以下各节详细拆解了指令输入的结构。
账户数量
首先被序列化的是该程序调用需要多少个账户。这占用 8 个字节。
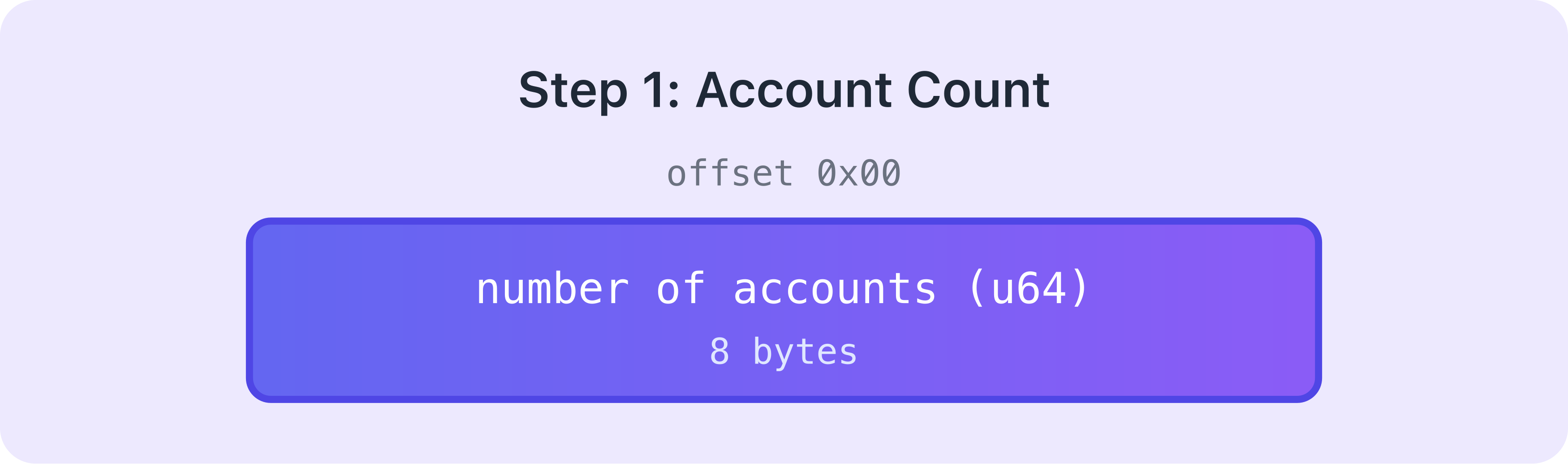
然后,依次序列化 accounts 数组中的每个账户
在账户数量之后,loader 会逐个序列化每个账户。每个账户以一个 1 字节的重复标记开头,该标记指示这是否是该账户在账户数组中的首次出现,或是重复项(意味着同一账户在账户数组中出现了多次)。

重复账户
如果账户是重复的(即该特定账户已经在之前的账户数组中被序列化过),loader 不会再次序列化其所有数据。相反,这 1 个字节的标记包含了该账户首次出现位置的索引,随后是 7 个字节的填充。因此,重复账户的总大小为 8 个字节(1 字节索引 + 7 字节填充)。
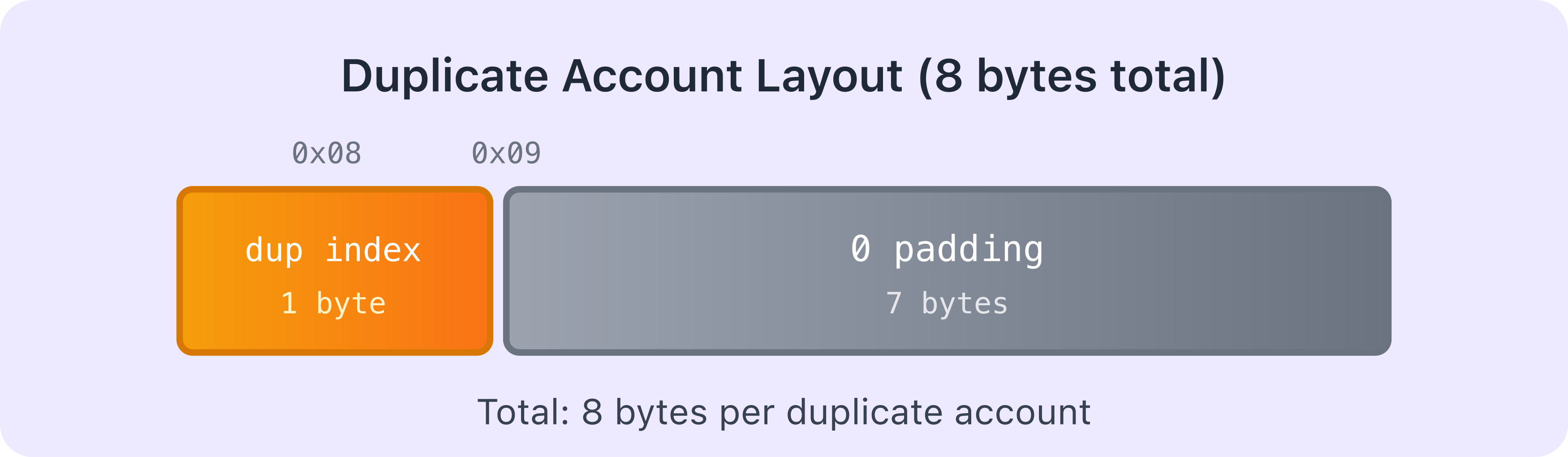
非重复账户
如果这是该账户在数组中的首次出现,loader 会序列化其所有信息。由于不同的账户包含不同数量的数据,这里也就是整个序列化数据大小变得可变的原因。
loader 按顺序写入每个账户。它以 1 字节的非重复标记(0xff)开头,随后是两个 1 字节的标志,用于指示该账户是否为签名者以及是否可写,然后是 4 个字节的填充——这个起始部分总共 7 个字节。之后,它写入账户的公钥(32 字节)、lamports 字段(8 字节)和数据长度(8 字节)。在任何账户数据之前,这些字段总计 55 个字节。
接下来,它写入账户的数据字节(x 字节)。一旦写入完成,loader 会附加 10,240 字节的保留空间(以便账户在执行期间可以增长而无需重新分配),加上 y 个对齐填充字节——这里的 y 是将下一个字段对齐到 16 字节边界所需的任意字节数(在序列化源码中定义为 BPF_ALIGN_OF_U128)。在填充之后,它写入账户所有者的公钥(32 字节)、1 字节的可执行标志和 8 字节的 rent epoch。
因此,非重复账户的总大小为:7(头部)+ 32(公钥)+ 8(lamports)+ 8(data_len)+ x(数据)+ 10,240 + y(保留 + 对齐)+ 32(所有者)+ 1(可执行标志)+ 8(rent epoch)= 10,336 + x + y 字节。

这种模式对账户数组中的每个非重复账户都会重复出现。
在所有账户(非重复或重复)序列化之后,序列化指令数据
一旦所有账户都被序列化,loader 就会序列化指令数据。首先,它将指令数据的长度写入为一个 8 字节的无符号整数(u64),然后是实际的指令数据本身(z 字节,因指令而异)。总计:8 + z 字节。

最后,放置程序 ID
最后被序列化的是程序 ID(被调用程序的公钥)。这始终是 32 个字节。

如果我们考虑一个包含单个非重复账户的序列化输入,则整个序列化输入的总大小将是: 8 字节(账户数量)+ 10,336 字节(固定账户字段 + 保留空间 + rent epoch)+ x 字节(实际账户数据)+ y 字节(对齐填充)+ 8 字节(指令数据长度)+ z 字节(实际指令数据)+ 32 字节(程序 ID)= 总计 10,384 + x + y + z 字节。如果你有多个账户,则将每个账户序列化数据的大小相加。

下图展示了完整的序列化输入结构(非重复账户):
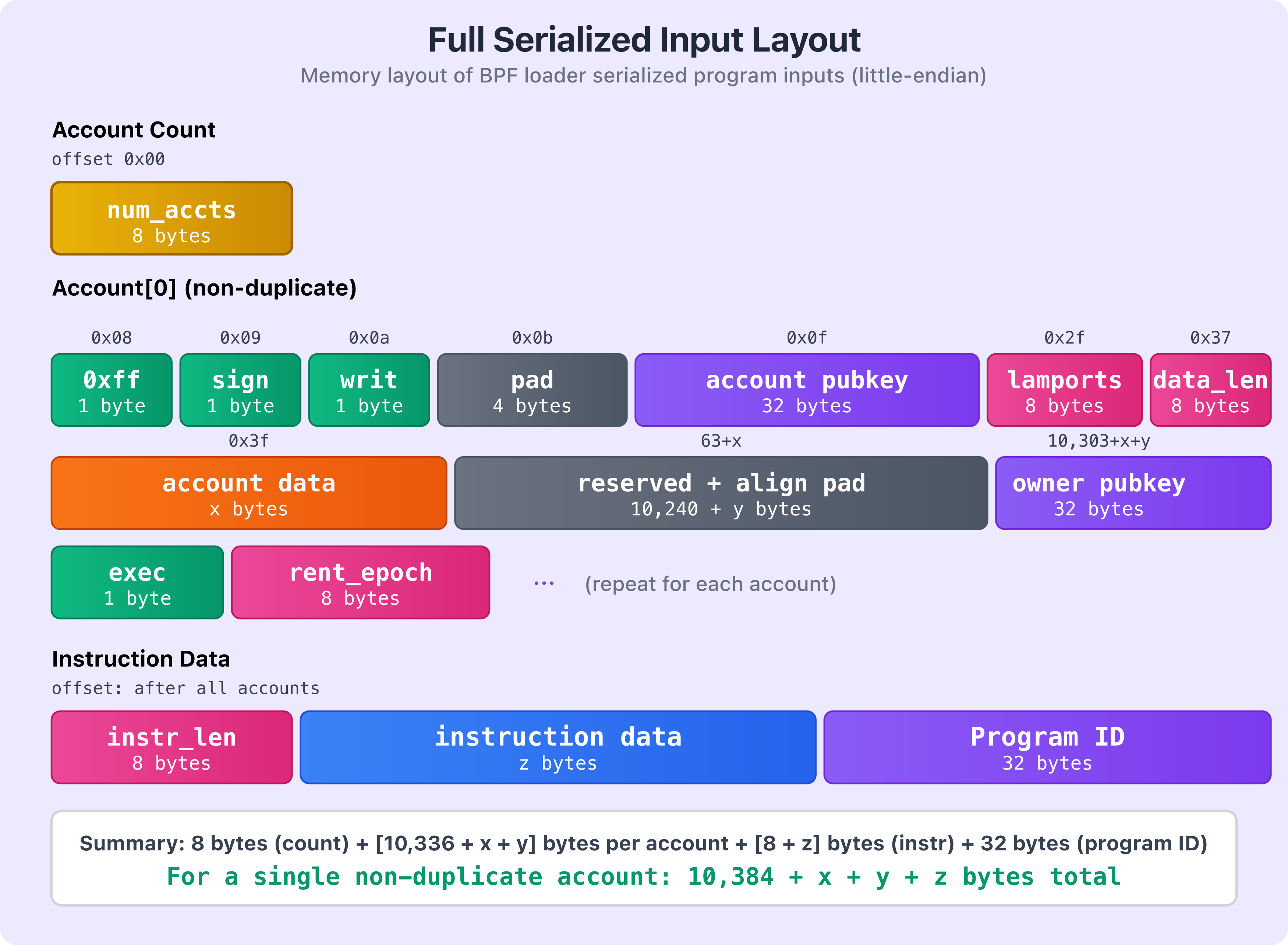
该图显示了不同组件在内存中的布局方式。黄色显示账户数量,绿色显示头部标志,紫色显示公钥(包括程序 ID),粉色表示像 lamports 和数据长度这样的数字字段,橙色显示账户数据,蓝色显示指令数据,灰色代表填充和保留部分。
如前所述,如果 accounts 数组中有多个账户,该模式将重复出现。在第一个账户的数据之后,我们会遇到第二个账户的另一个 1 字节重复标志。如果它不是重复的(0xff),则遵循完整的账户结构。如果是重复的,这个 1 字节的值包含其在账户数组中首次出现的索引,随后是 7 个字节的填充。
请注意,序列化数据的总大小并不是固定的;它取决于你传递的账户数量、每个账户包含的数据量,以及指令数据的大小。
程序如何反序列化指令输入
既然我们已经了解了 BPF loader 如何将指令输入序列化为字节数组,下面让我们看看你的程序如何反序列化这个字节数组。
当运行时调用程序 entrypoint 时,它会调用一个 deserialize 函数,将原始输入字节数组转换为执行所需的程序 ID、账户和指令数据。
这个反序列化函数存在于 Solana SDK 中,并由 Solana crate 中的 entrypoint! 宏调用。在原生 Rust Solana 程序中,该宏定义了程序的 entrypoint,并在将控制权移交给指令处理器之前调用 SDK 提供的反序列化器(我们将在下一节中讨论这点)。
反序列化函数通读 BPF loader 序列化的字节数组,并提取出程序 ID(作为 Pubkey)、账户(作为 AccountInfo 的 vector)以及指令数据(作为字节切片)。
pub unsafe fn deserialize<'a>(input: *mut u8) -> (&'a Pubkey, Vec<AccountInfo<'a>>, &'a [u8]) {
let mut offset: usize = 0;
// Number of accounts present
#[allow(clippy::cast_ptr_alignment)]
let num_accounts = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
// Account Infos
let mut accounts = Vec::with_capacity(num_accounts);
for _ in 0..num_accounts {
let dup_info = *(input.add(offset) as *const u8);
offset += size_of::<u8>();
if dup_info == NON_DUP_MARKER {
let (account_info, new_offset) = deserialize_account_info(input, offset);
offset = new_offset;
accounts.push(account_info);
} else {
offset += 7; // padding
// Duplicate account, clone the original
accounts.push(accounts[dup_info as usize].clone());
}
}
// Instruction data
let (instruction_data, new_offset) = deserialize_instruction_data(input, offset);
offset = new_offset;
// Program Id
let program_id: &Pubkey = &*(input.add(offset) as *const Pubkey);
(program_id, accounts, instruction_data)
}
现在让我们逐步拆解这段代码块。
理解反序列化过程
函数签名
pub unsafe fn deserialize<'a>(input: *mut u8) -> (&'a Pubkey, Vec<AccountInfo<'a>>, &'a [u8]) {
deserialize 函数被标记为 unsafe,因为它涉及原始指针操作。它接收 input(一个指向内存中序列化字节的指针),并返回三个值:
- 对程序
Pubkey的引用 AccountInfo结构体的 vector(交易中使用的账户)- 包含指令数据的字节切片
跟踪当前位置
首先,deserialization 函数创建一个 offset 变量来跟踪其在 input 字节数组中的当前位置。正如我们从 BPF loader 序列化此数据的方式中所知,前 8 个字节(一个 u64)指定了账户的数量。该函数将此值读入 num_accounts,然后将 offset 向前推进 8 个字节。
let mut offset: usize = 0;
// Number of accounts present
#[allow(clippy::cast_ptr_alignment)]
let num_accounts = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
初始化 Accounts Vector
接下来,deserialize 函数创建一个容量为 num_accounts 个元素的 vector。这比让 vector 动态增长更高效,因为 Rust 不需要随着 vector 填满而重新分配并复制整个 vector。
let mut accounts = Vec::with_capacity(num_accounts);
反序列化每个账户
在创建了一个 vector 来保存要反序列化的账户之后,该函数循环遍历每个账户并检查重复标志。如果是 NON_DUP_MARKER (0xff),这意味着这是一个唯一的账户,因此它调用 deserialize_account_info 将完整的账户结构(我们接下来解释)读取到 accounts vector 变量中。如果是重复项(该标志包含的则是一个索引),它只会跳过 7 个填充字节,并复制在该索引处已经反序列化的账户。
for _ in 0..num_accounts {
// 1 byte indicating if this is a duplicate account
// If not a duplicate, the value is 0xff (NON_DUP_MARKER)
// Otherwise, the value is the index of the account it duplicates
let dup_info = *(input.add(offset) as *const u8);
offset += size_of::<u8>();
if dup_info == NON_DUP_MARKER {
// Not a duplicate: deserialize the full account
let (account_info, new_offset) = deserialize_account_info(input, offset);
offset = new_offset;
accounts.push(account_info);
} else {
// Duplicate account: skip 7 bytes of padding and copy the original
offset += 7; // padding
accounts.push(accounts[dup_info as usize].clone());
}
}
deserialize_account_info 辅助函数定义如下:
此辅助函数完全按照 BPF loader 写入它们的顺序遍历序列化字节。它读取三个布尔标志(is_signer、is_writable、executable),跳过 4 字节的填充,读取两个公钥(账户密钥和所有者),读取 lamports 和数据长度,然后创建一个指向账户数据的切片。之后,它将 offset 推进到越过账户数据本身、10,240 字节的保留空间和 8 字节的 rent epoch(它实际上并未存储在 AccountInfo 结构体中——仅是被跳过)。最后,它添加对齐填充以确保下一个账户从 8 字节对齐的地址开始。
unsafe fn deserialize_account_info<'a>(input: *mut u8, mut offset: usize) -> (AccountInfo<'a>, usize) {
// 1 byte boolean, true if account is a signer
let is_signer = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 1 byte boolean, true if account is writable
let is_writable = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 1 byte boolean, true if account is executable
let executable = *(input.add(offset) as *const u8) != 0;
offset += size_of::<u8>();
// 4 bytes of padding
offset += size_of::<u32>();
// 32 bytes of the account's public key
let key: &Pubkey = &*(input.add(offset) as *const Pubkey);
offset += size_of::<Pubkey>();
// 32 bytes of the account owner's public key
let owner: &Pubkey = &*(input.add(offset) as *const Pubkey);
offset += size_of::<Pubkey>();
// 8 bytes unsigned number of lamports owned by the account
let lamports = &mut *(input.add(offset) as *mut u64);
offset += size_of::<u64>();
// 8 bytes unsigned number of bytes of account data
let data_len = *(input.add(offset) as *const u64) as usize;
offset += size_of::<u64>();
// x bytes of account data (variable length)
let data = from_raw_parts_mut(input.add(offset), data_len);
offset += data_len;
// 10,240 bytes of reserved space (for account data growth)
offset += MAX_PERMITTED_DATA_INCREASE;
// 8 bytes rent epoch (skipped, not deserialized into AccountInfo)
offset += size_of::<u64>();
// Alignment padding to ensure next account starts at 8-byte boundary
offset += (offset as *const u8).align_offset(BPF_ALIGN_OF_U128);
(AccountInfo::new(key, is_signer, is_writable, lamports, data, owner, executable), offset)
}
反序列化指令数据和程序 ID
在反序列化所有账户之后,deserialize 函数继续处理指令数据。它调用 deserialize_instruction_data 辅助函数。该辅助函数定义如下:
// Instruction data
let (instruction_data, new_offset) = deserialize_instruction_data(input, offset);
offset = new_offset;
此辅助函数读取 8 字节的指令数据长度,创建一个指向指令数据字节的切片,并返回该切片以及更新后的 offset。
unsafe fn deserialize_instruction_data<'a>(input: *mut u8, mut offset: usize) -> (&'a [u8], usize) {
// Read the length of the instruction data (first 8 bytes at the current offset)
let instruction_data_len = *(input.add(offset) as *const u64) as usize;
// Move the offset past the u64 length field, so it now points to the start of the instruction data
offset += size_of::<u64>();
// Create a slice pointing to the instruction data bytes
let instruction_data = from_raw_parts(input.add(offset), instruction_data_len);
// Move the offset past the instruction data itself
offset += instruction_data_len;
// Return the instruction data slice and the updated offset
(instruction_data, offset)
}
最后,主反序列化函数(deserialize)提取出程序 ID(最后的 32 字节),并返回你的程序所需的所有三个组件:程序 ID、账户 vector 和指令数据。
// Program Id
let program_id: &Pubkey = &*(input.add(offset) as *const Pubkey);
我们已经探讨了 Solana BPF loader 如何将程序指令输入序列化为字节数组,以及程序如何将它们反序列化为程序 ID、账户和指令数据。在本文的下一部分中,我们将看看这些输入一旦到达程序后会发生什么。
本文是Solana 开发教程系列的一部分