使用内联汇编(inline assembly)来回退(revert)交易,相比使用高级 Solidity 的 revert 或 require 语句,在 Gas 消耗上可能更高效。在本指南中,我们将通过在汇编中模拟实现它们,来探索 Solidity 中不同类型的 revert 是如何在底层工作的。
下面的示例显示,汇编版本的 revert 语句将 Gas 成本从 157 Gas 降低到了 126 Gas,节省了 31 Gas:

作为前置知识,我们假设你已经阅读过 Try Catch and All the Ways Solidity Reverts 这篇文章,以及我们关于 ABI 编码的文章。
在 EVM 中,内存(memory)是一个以字节为索引的长字节数组。也就是说,我们可以根据它们的索引来读写字节。尽管内存是按字节索引的,但我们通常一次读写 32 个字节。
汇编中的 mstore 及其工作原理
使用汇编进行 revert 很大程度上依赖于 Yul 的 mstore 操作码(opcode)将数据存储到内存中,所以我们首先来深入探讨一下这个操作码。
mstore 操作码接受两个参数:
- 内存位置 (Memory location):将要存储数据的字节地址。
- 数据 (Data):要存储的 32 字节数据。
以下是使用 mstore 的示例:
assembly {
mstore(memoryLocation, dataToStore)
}
如果你想在内存位置 0x00 存储 32 字节的 0xFF,你可以这样写:
assembly {
mstore(
0x00,
0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
)
}
这会从索引 0x00 开始存储完整的 32 字节值。如果你想将该值存储在内存位置 0x01,你可以这样写:
assembly {
mstore(
0x01,
0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
)
}
这会将数据的起始位置偏移一个字节,而 0x00 处的第一个字节将不受影响。下图展示了 mstore 是如何在内存中存储数据的:
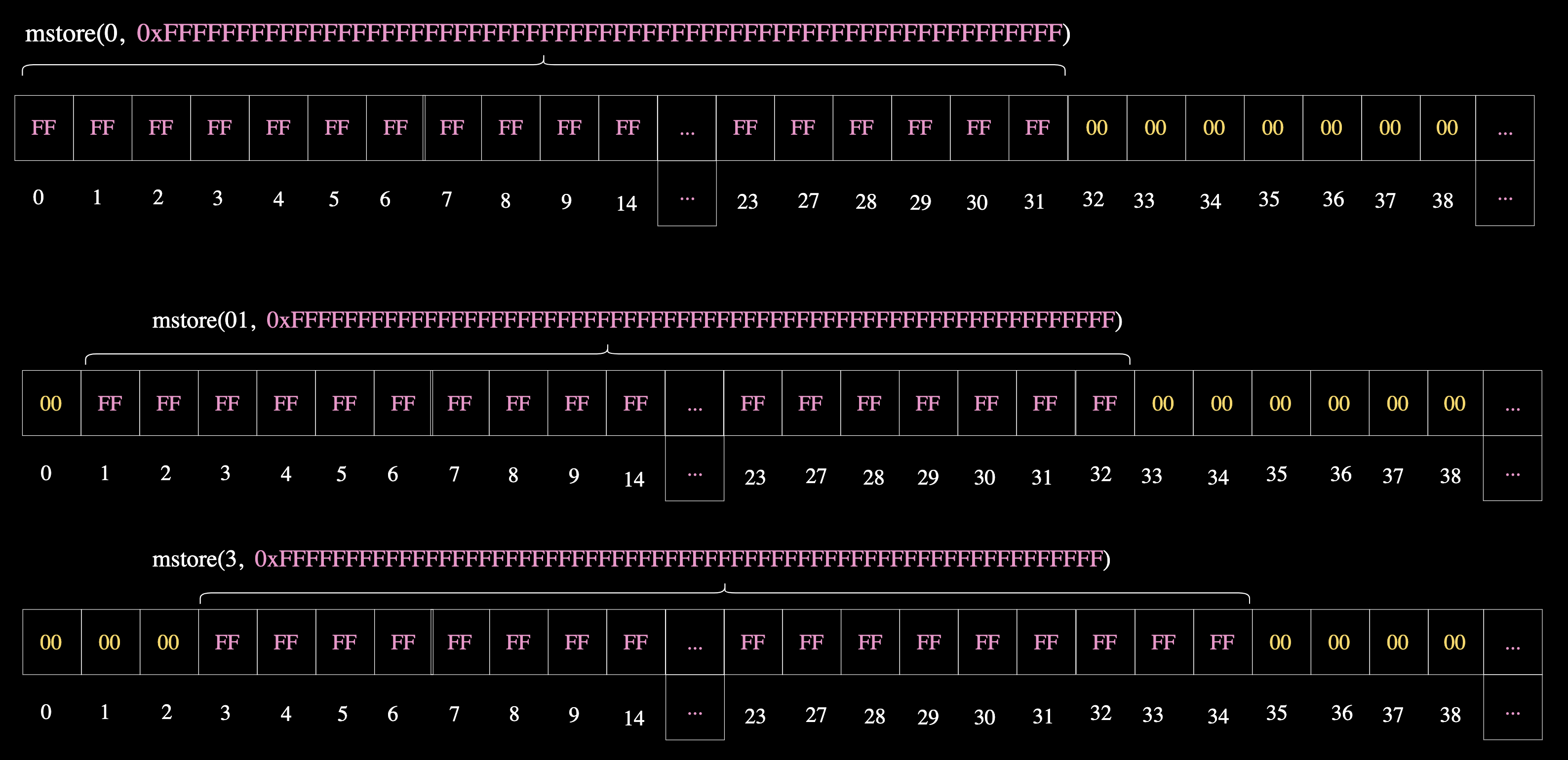
请注意,尽管我们在 mstore(0, ...) 中指定写入字节索引 0,但我们不仅写入了 0 的位置,还写入了随后的 31 个字节——mstore 会一次性写入 32 个字节。
mstore 中的隐式数据填充
如果我们在第二个参数中指定了少于 32 字节(64 个十六进制字符)的数据,Solidity 编译器将会用零在左侧(较高有效字节)进行填充,直到该值达到 32 字节长,然后它会从 mstore 第一个参数指定的字节索引开始,写入这 32 个字节。
考虑以下示例:
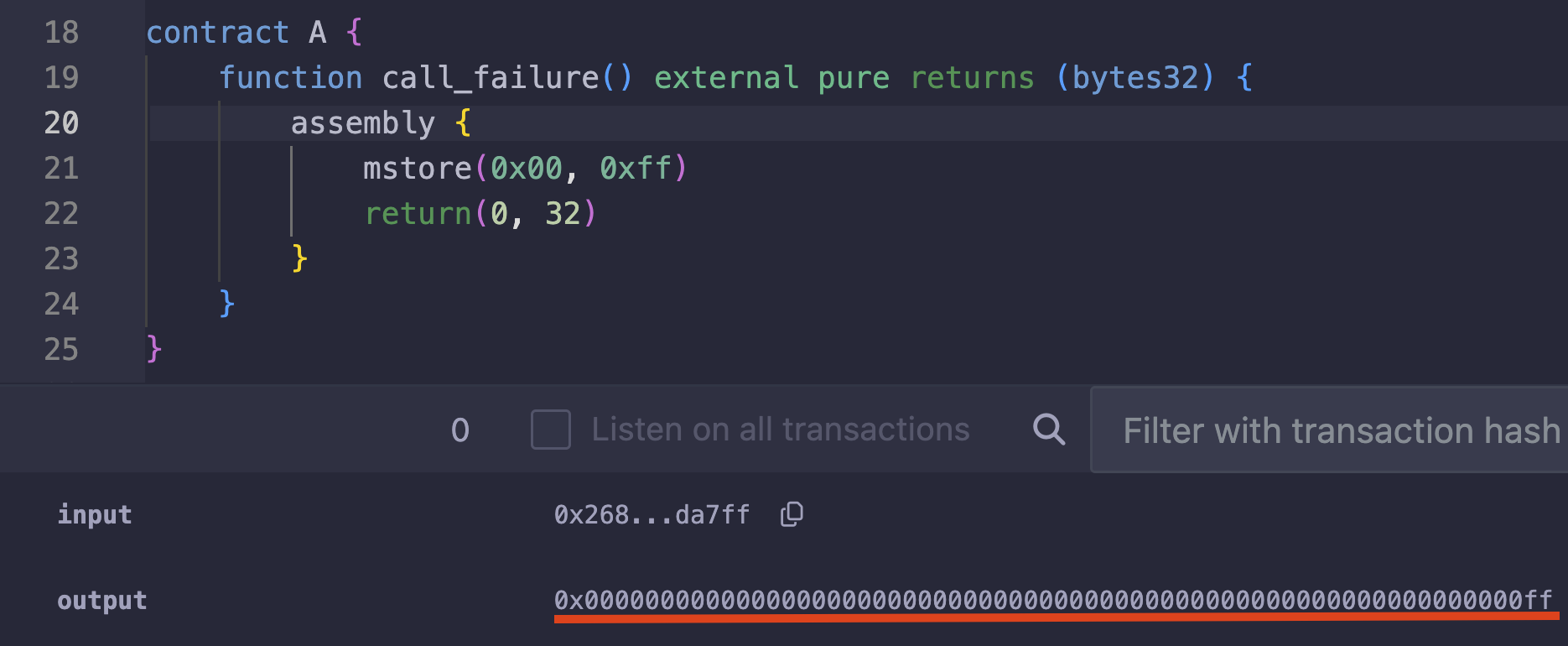
assembly {
mstore(0x00, 0xff)
}
上面的代码会将数据以 0x00000000000000000000000000000000000000000000000000000000000000ff 的形式存储在内存中,其中 0xff 占据最后一个字节,前面的 31 个字节被填充为零。
换句话说,mstore(0x00, 0xff) 隐式地变成了 mstore(0x00, 0x00000000000000000000000000000000000000000000000000000000000000ff)
内存中该值的结果显示如下:

回想一下,mstore 会写入 32 字节,但在这种情况下,其中 31 个字节是零,范围涵盖从第 0 个字节到第 30 个字节(包含在内)。这意味着 0-31 字节范围内的任何数据都会被零覆盖。
如果我们像下面的截图那样返回存储的数据,就可以看到它在内存中的样子:
下图展示了 mstore 是如何隐式地对各种十六进制值进行左填充的,第一行就是我们刚刚看过的示例。

使用 mstore8 将数据存储在内存中
另外,我们可以使用 mstore8 操作码,它与 mstore 类似,但它只在特定内存位置存储一个字节的数据。
assembly {
mstore8(memoryLocation, exactlyOneByteOfData)
}
例如,如果我们想要在第 31 个字节存储单字节数据(0xff),我们可以像这样直接使用 mstore8 进行存储:
assembly {
mstore8(31, 0xff)
}
其输出将与使用 mstore 相同,0xff 会占据最后一个字节。
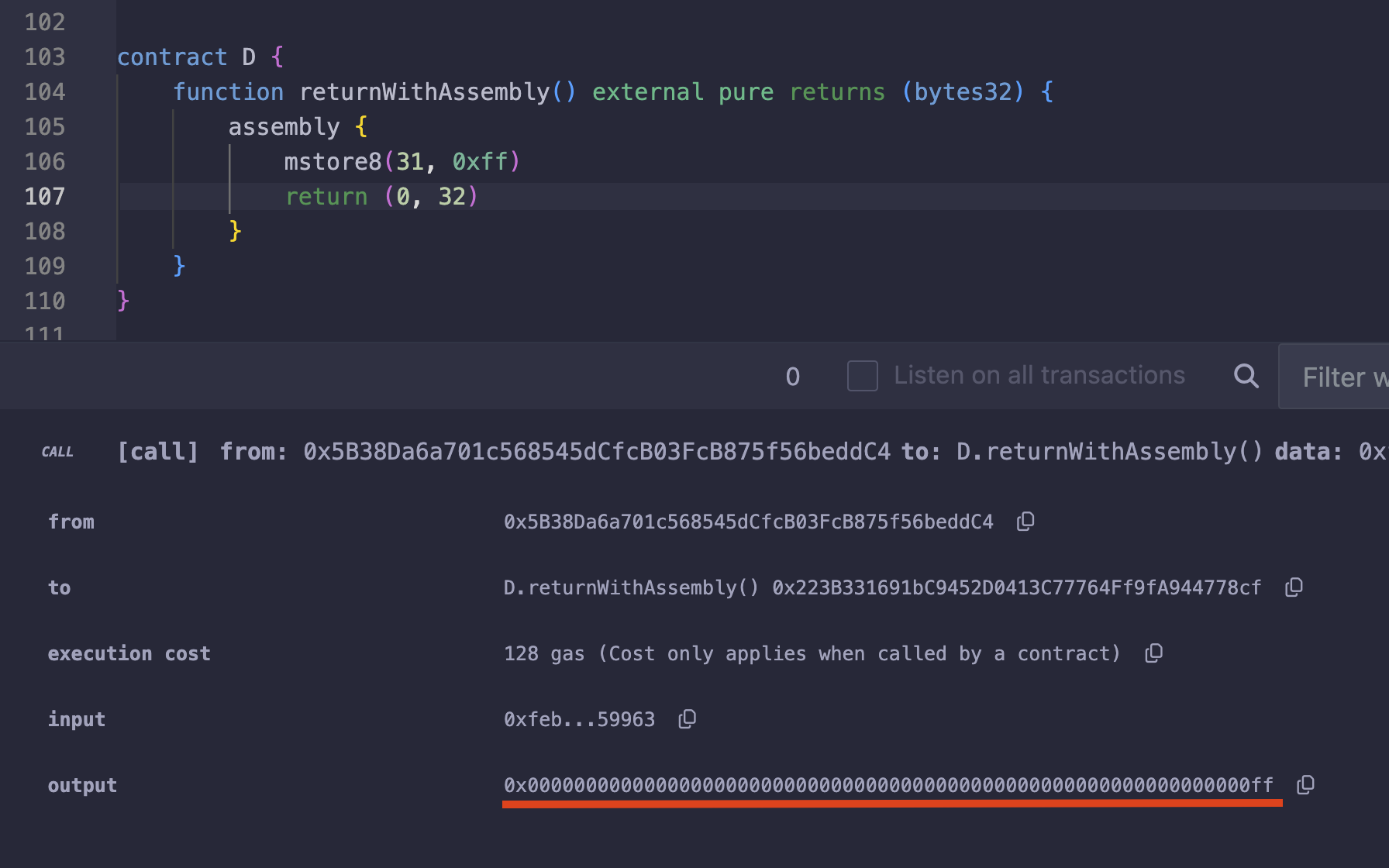

mstore8 与 mstore 之间的关键区别在于,mstore8 不会像 mstore 那样额外添加 31 个零,从而不会覆盖先前存储在第 0 到第 31 个字节范围内的数据。
使用 mstore 在右侧填充零写入 0xff
如果你想使用 mstore(而不是 mstore8)在第 0 个字节写入 0xff,你可以将 0xff 存储为第一个字节,并用零填充剩余的 31 个字节,如下所示:
assembly {
mstore(
0x00, 0xff00000000000000000000000000000000000000000000000000000000000000
)
}
这会完全按照你指定的方式存储该值,0xff 位于开头,剩余的字节全为零:

以下是在 Remix 中运行该代码的测试:
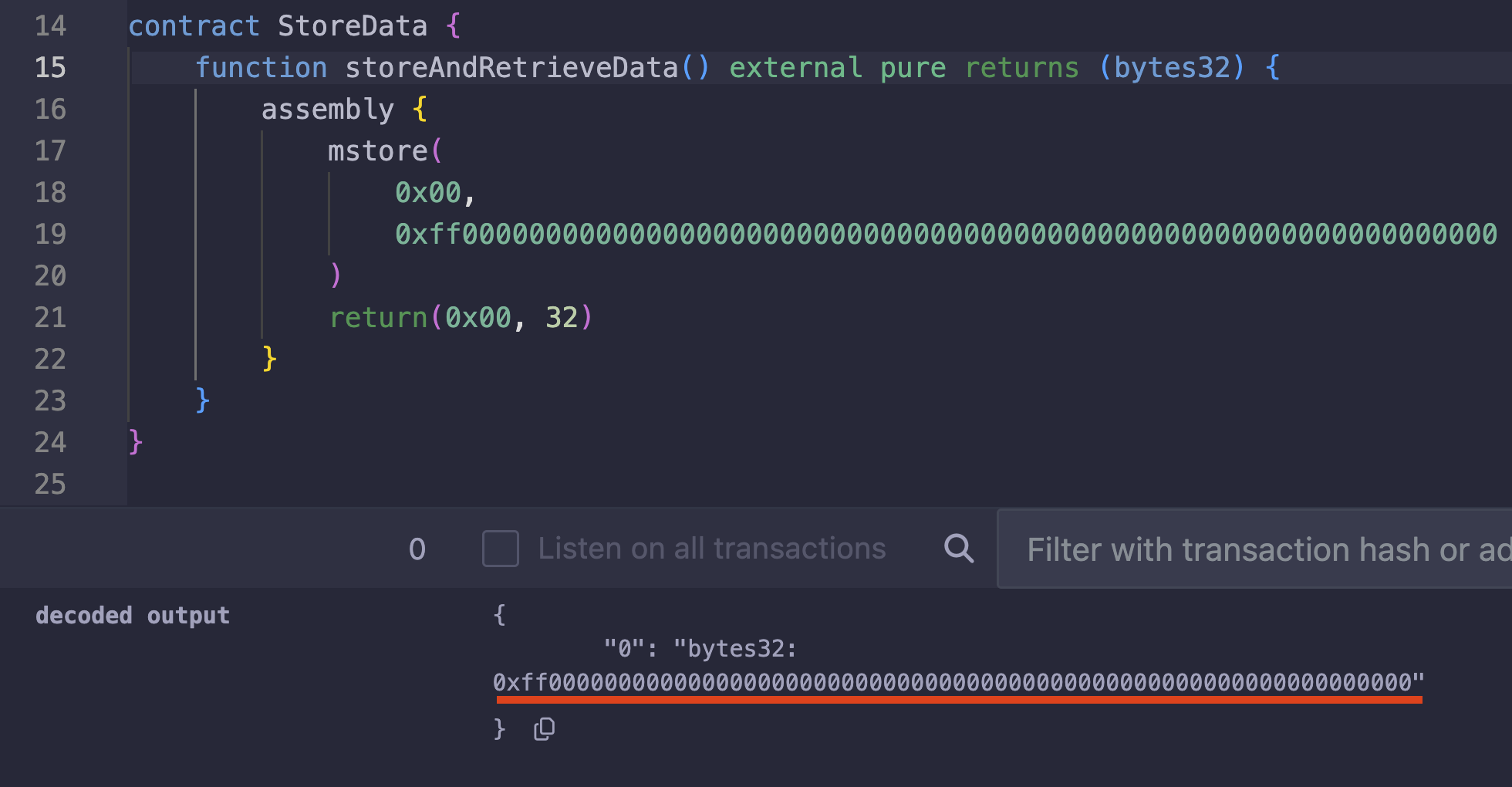
看起来零很多,对吧?作为替代方案,我们可以使用 mstore8 在特定的内存位置存储一个字节的数据。在下面的示例中,我们使用 mstore8 将 0xff 存储在第 0 个字节:
这是一个紧凑得多的代码,它实现了与上一个截图相同的功能,唯一的区别是它不会在字节 1 到 31 中写入零。
请注意:
mstore存储完整的 32 字节数据,而mstore8仅在指定的内存位置存储单字节数据。- 使用
mstore时,如果你的数据少于 32 个字节,它将自动在左侧(较低索引的内存位置)填充零字节,以填满 32 个字节。这些零将会覆盖之前位于该处的任何其他内存内容。
如果多次写入同一个位置,你将覆盖内存中的数据
还记得我们提到过,mstore 在左侧填充的额外零会覆盖从第 0 个字节到第 30 个字节范围内的任何现有内容吗?我们来探讨一下这种覆盖是如何发生的。
如果我们使用 mstore8 将 0xCC 写入第 0 个字节:
assembly {
mstore8(0, 0xCC)
}
我们现在将在第 0 个位置拥有 0xCC,而其余的内存保持不变,如下图所示。

随后,如果我们像这样使用 mstore(0, 0xFF) 存储 0xFF:
assembly {
mstore8(0, 0xCC)
mstore(0, 0xFF)
}
0xFF 会覆盖先前存储在第 0 个字节的 0xCC,并用 0xFF 填满整个 32 字节插槽(从第 0 个字节到第 31 个字节)。
回想一下,mstore 会将数据写入整个 32 字节插槽,如果我们只有少于 32 个字节的数据,它会用零填充剩余的字节,如下所示:
0x00000000000000000000000000000000000000000000000000000000000000**FF**
下面的动画展示了这种覆盖是如何发生的:
这证明了 mstore 填充的 31 个零实际上会改变内存的内容。
如何记住 mstore 的填充方式
与其死记硬背 mstore 会用零左填充十六进制值,我们不如将 mstore(0, 0xff) 视为与 mstore(0, 255) 完全等效。
换句话说,mstore(0, 255) 的意思是“在从字节 0 开始的 32 个字节中存储数字 255,其中字节 0 保存最高有效字节(most significant bytes)。”
由于 255 相对于 32 字节所能容纳的数值(uint256 的最大值)来说是一个“小数字”,因此只会用到最低有效位(least significant bits)。最低有效位在右侧,而左侧的较高有效位则被设置为零。
同样地,数字 0xff00000000000000000000000000000000000000000000000000000000000000 则相当大。
在十进制中,它是 115339776388732929035197660848497720713218148788040405586178452820382218977280。因此,它用尽了位于左侧的最高有效位。
使用存储的数据进行 revert
我们已经看到了如何使用 mstore 在内存中存储数据。在一次 revert 过程中,我们需要将错误数据存储在内存中,并将其作为 revert 的错误信息返回。
revert 操作码接受两个参数:起始内存插槽,以及我们打算返回的数据总大小。
revert(startingMemorySlot, totalMemorySize)
从这里开始,我们将展示如何在以下情况中模拟 Solidity revert 的行为:
- 不带原因字符串的 revert
- 带有自定义错误的 revert
- 带有自定义错误和原因字符串的 revert
1. 不带原因(消息)的 revert
对于一个简单的、不带消息的 revert,汇编代码 revert(0,0) 在行为和 Gas 成本上与 Solidity 中的 revert() 等效。它不会向调用者返回任何数据。
在底层,使用 revert(0,0) 意味着“不使用数据”,因为引用的数据长度为零。通常约定使用内存位置 0 作为起点,但由于我们不返回任何内容,我们也可以使用 revert(1,0) 来实现相同的效果。
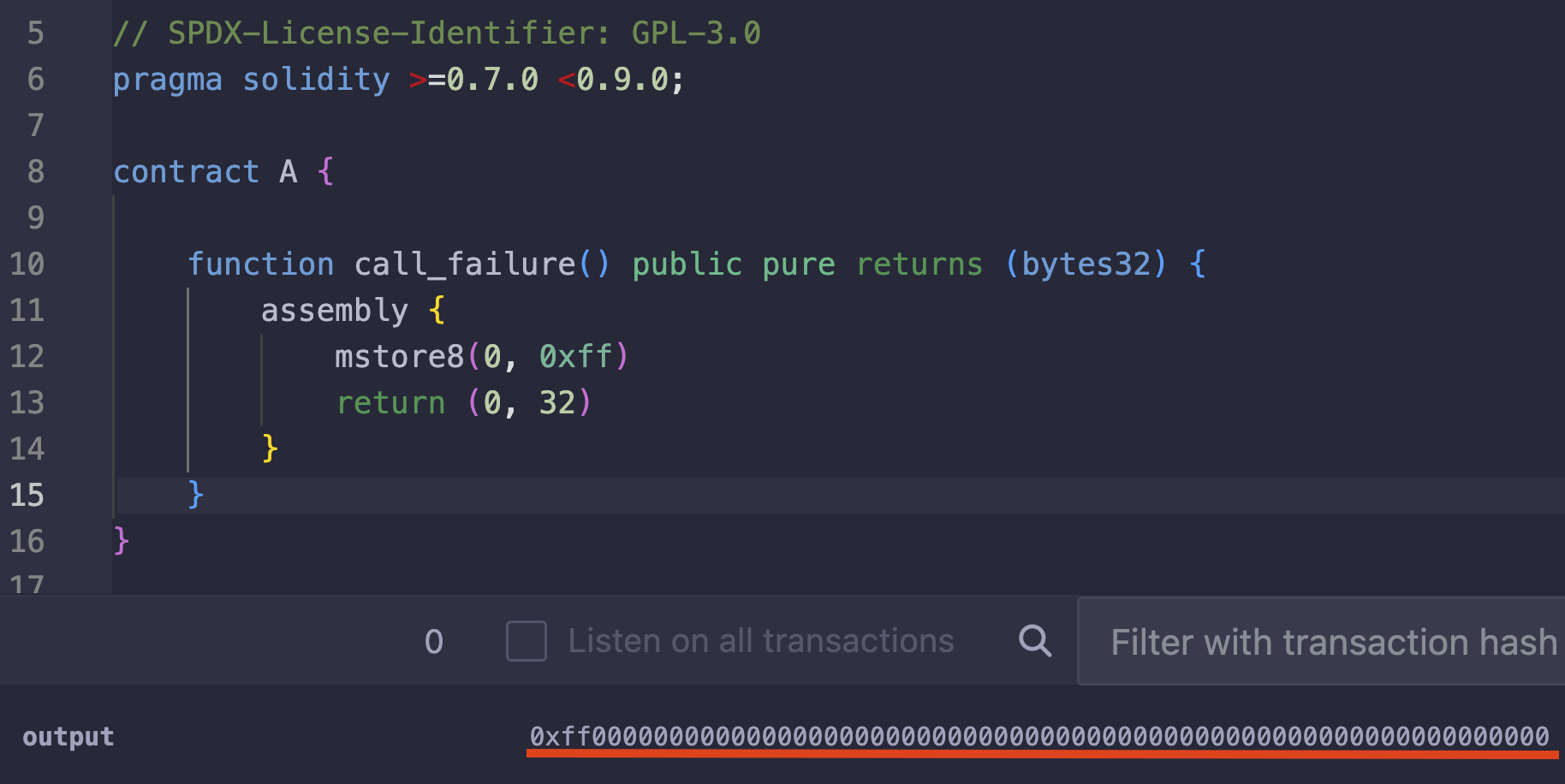
以下是使用汇编进行无原因 revert 的简单示例:
contract ContractA {
function zero() external {
assembly {
revert(0,0) //<--- simple revert without reason
}
}
}
下面的截图展示了从 ContractA 到 ContractB 的 底层调用(low-level call),以及该底层调用如何因为 ContractB 发生 revert 而返回 false,同时由于我们使用的是 revert(0,0),因此没有返回任何数据。
2a. 汇编中不带参数的自定义 revert
为了说明如何使用汇编模拟不带参数的自定义错误,让我们以 revert Unauthorized() 为例。
我们将把自定义 revert 的 错误函数选择器(error function selector)存储在内存中的特定位置(按惯例是 0x00),然后 revert 将指向该内存位置。
以下是我们用作示例的 Solidity 代码:
contract CustomError {
error Unauthorized();
function revertCustomError() {
revert Unauthorized();
}
}
我们将按照以下步骤在汇编中实现自定义 revert:
- 将函数选择器存储在内存中
- 触发 revert,将选择器的内存位置以及选择器的大小(4 字节)作为参数传递给
revert
assembly {
mstore(memoryLocation, selector)
revert(memoryLocation, sizeOfSelector)
}
1. 存储函数选择器
当 Solidity 触发自定义错误时,返回值是该自定义错误本身的 ABI 编码,其中包括 函数选择器(function selector)(自定义错误签名的 keccak256 哈希值的前四个字节)。
由于我们以自定义错误 Unauthorized() 为例,我们将首先存储函数选择器(Unauthorized() 的 keccak256 哈希值的前四字节),即 0x82b42900,并用额外的零进行填充,将该值加长至 32 字节,以确保函数选择器的实际四个字节被写入到从字节 0 到字节 3(包含)的位置。如果没有这种填充,选择器将不会从内存索引 0 开始。
bytes32 selector = bytes32(abi.encodeWithSignature("Unauthorized()")); // 0x82b42900
assembly {
mstore(0x00, 0x82b4290000000000000000000000000000000000000000000000000000000000)
}
2. 触发 revert
我们现在将使用下面的 revert 语句来触发自定义错误。记住 revert 的模板是 revert(startingMemorySlot, totalMemorySize)。
revert(0x00, 0x04)
0x00 是我们存储错误数据的内存位置,而 0x04(十六进制)是错误数据的大小,即只有 4 字节。整个 revert 代码现在应该如下所示:
pragma solidity 0.8.27;
contract RevertErrorExample {
function revertWithAssembly() public pure {
assembly {
mstore(
0x00,
0x82b4290000000000000000000000000000000000000000000000000000000000
)
revert(0x0, 0x04)
}
}
}
以下是我们将用来对比汇编实现与 Solidity 实现的代码:
// SPDX-License-Identifier: GPL-3.0
pragma solidity 0.8.27;
contract RevertErrorExample {
error Unauthorized();
// assembly version
function revertWithAssembly() public pure {
assembly {
mstore(
0x00,
0x82b4290000000000000000000000000000000000000000000000000000000000
)
revert(0x0, 0x04)
}
}
// solidity version
function revertWithoutAssembly() public pure {
revert Unauthorized();
}
}
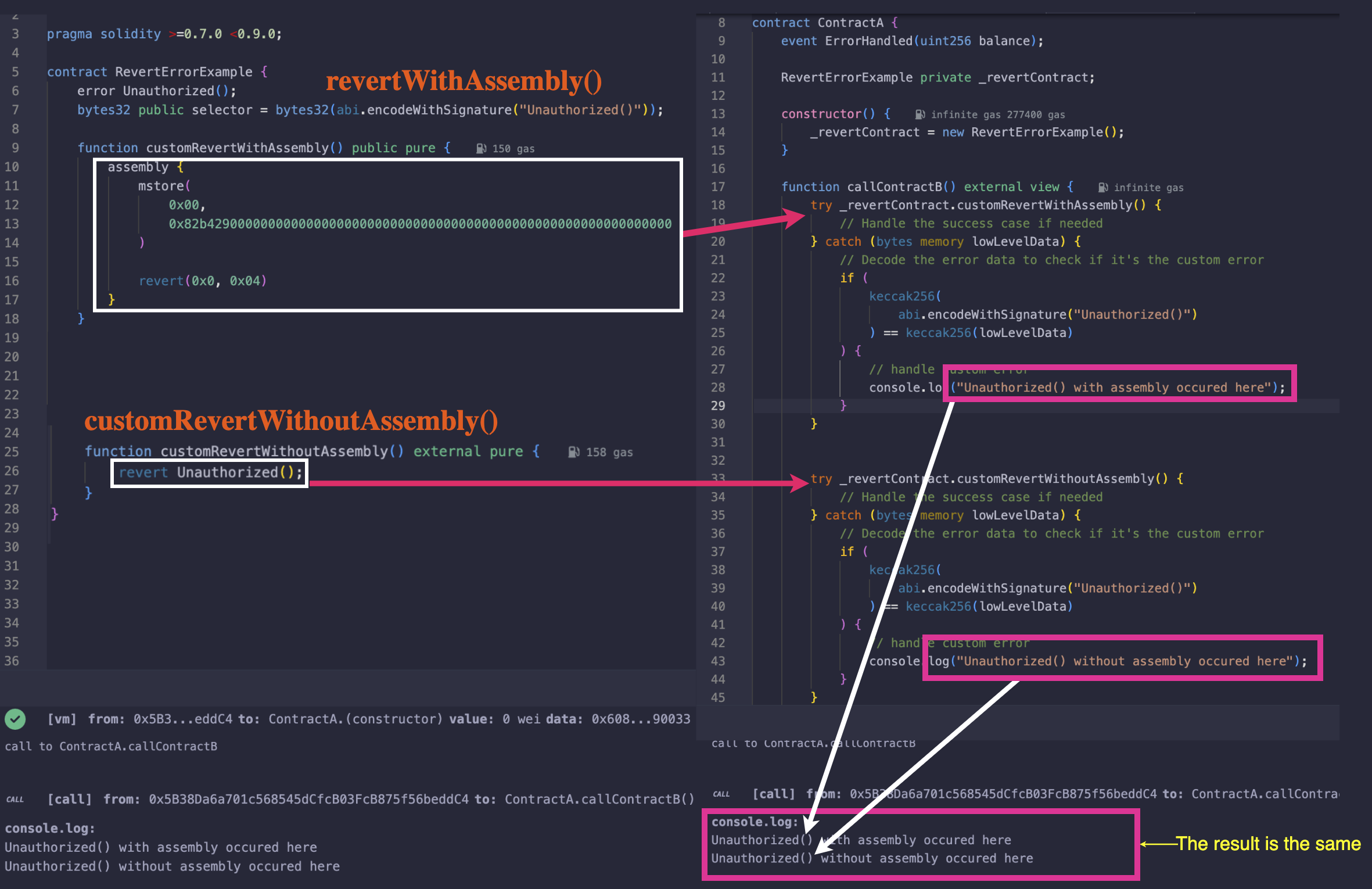
结果显示在下面的截图中。唯一的区别在于 Gas 成本。截图显示,通过 Assembly 而不是在 Solidity 中触发 revert,我们节省了 54 单位的 Gas。

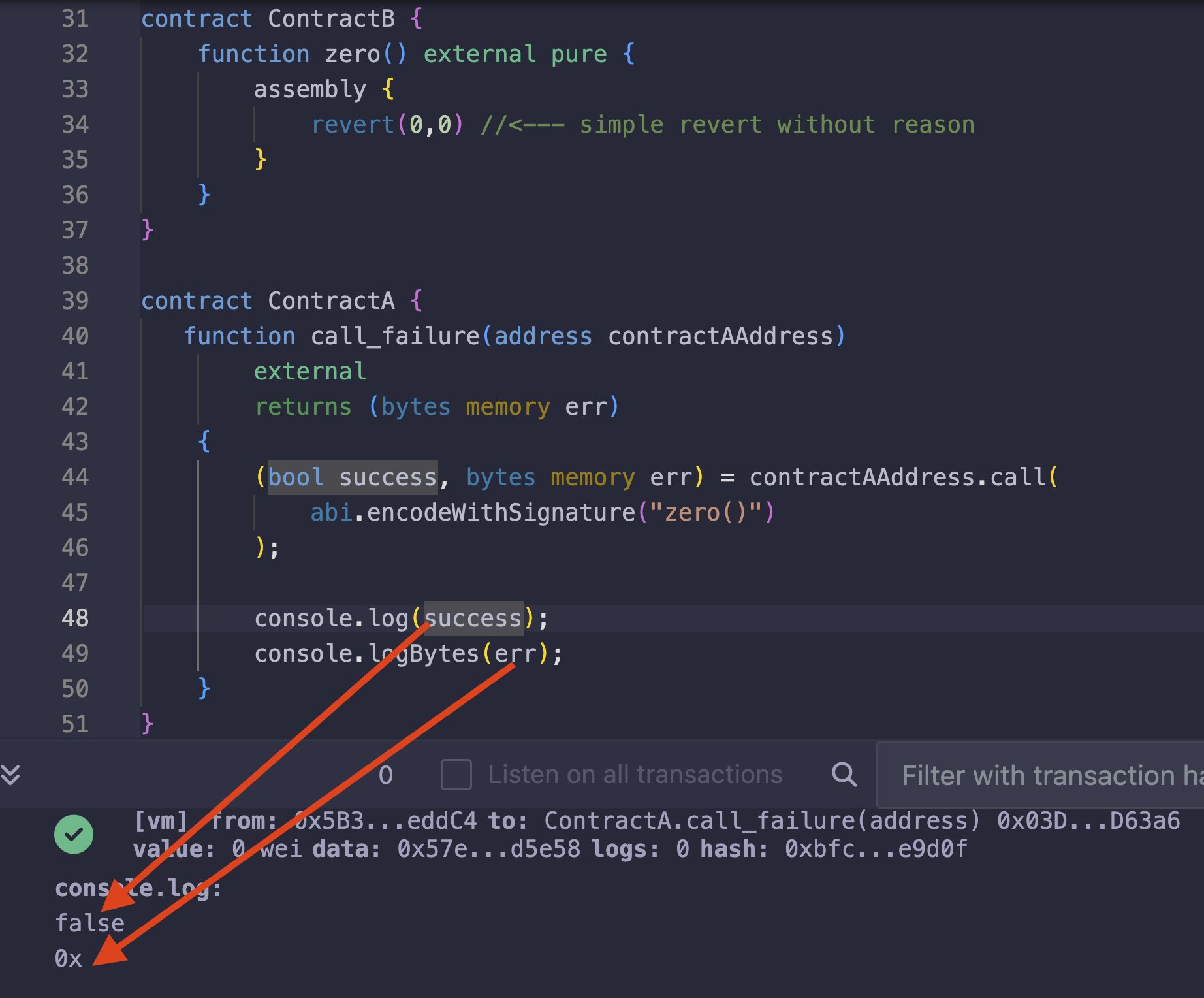
此外,在下面的代码中,callContractB 分别对 customRevertWithAssembly 和 customRevertWithoutAssembly 使用了 try/catch 来解析错误,这表明它们的行为是相同的。
当自定义错误没有参数时存储选择器并触发 revert 的替代方法
当自定义错误没有参数时,函数选择器是唯一需要返回的相关数据。在这种情况下,我们可以存储函数选择器,而无需手动添加额外的零,并直接从我们存储的特定内存区域执行 revert。
例如,不必像这样用零填充:
assembly{
mstore(
0x00,
0x82b4290000000000000000000000000000000000000000000000000000000000
)
}
我们可以这样写,而无需手动填充零:
assembly{
mstore(0x00,0x82b42900)
}
在内存中,零会被添加到函数选择器的左侧(从第 0 个字节到第 27 个字节),而实际的选择器将被存储在第 28 个字节到第 31 个字节之间。
换句话说,0x82b42900 会被扩展为 0000000000000000000000000000000000000000000000000000000082b42900,并存储在字节 0 到 31 中,如下所示:

由于函数选择器现在位于第 28 个字节(十六进制的 0x1c),你可以从这个位置(而不是 0x00)执行 revert,如下所示:
assembly {
mstore(0x00,0x82b42900)
revert(0x1c, 0x04)
}
2b. 汇编中带参数的自定义 revert
如果自定义错误包含参数,我们还需要对这些参数进行 ABI 编码,因为它们将作为 revert 返回数据的一部分。假设它有一个 address 类型的参数,我们会将该参数存储在内存中,并使 revert 的参数指向内存中的选择器和地址。
作为示例,让我们在汇编中复现自定义 revert Unauthorized(address)。
contract CustomError {
error Unauthorized(address caller);
function revertCustomError() {
revert Unauthorized(msg.sender);
}
}
在汇编中复现带有参数的自定义 revert 的步骤,与不带参数的步骤类似,唯一的区别是我们需要将参数(在这个例子中是 address)作为返回数据的一部分进行存储。我们将遵循以下步骤:
- 在内存中存储该自定义错误的函数选择器
- 在选择器之后将参数存储到内存中
- 触发 revert,将起始内存位置和总大小(选择器的 4 字节 + 参数大小)传递给
revert函数
1. 在内存中存储自定义错误的函数选择器
就像没有参数的自定义错误一样,我们需要首先按如下方式推导出函数选择器:
bytes4 selector = bytes4(abi.encodeWithSignature("Unauthorized(address)")
);
选择器将是 0x8e4a23d6。现在我们将像下面这样,使用 mstore 将该选择器从 0x00 内存位置开始存储:
assembly{
// Store the function selector at the memoryy location `0x00`
mstore(0x00, 0x8e4a23d600000000000000000000000000000000000000000000000000000000)
}
2. 在选择器之后将参数存储到内存中
在从第 0 个字节开始将函数选择器写入内存后,我们现在将从第 4 个字节开始存储 address,如下所示:
assembly{
//...
// Store the address
// *Note that `caller()` in assembly is the same as `msg.sender` in Solidity.*
mstore(0x04, caller())
}
caller() 函数将返回向上转换(upcast)为 32 字节的地址。因此,如果原始地址是 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4,caller() 将返回 0x00000000000000000000000005B38Da6a701c568545dCfcB03FcB875f56beddC4,这就是 mstore 将从字节 4 开始放置在内存中的 32 字节值。
3. 触发 revert
最后,我们现在可以触发 revert,将起始内存位置以及我们目前存储数据的总大小(选择器的 4 字节 + 地址的 32 字节,共占用 36 字节,十六进制为 0x24)作为参数传递,如下所示:
function customRevertWithAssembly() public pure {
assembly {
//...
// 4 bytes for selector + 32 bytes for the address
revert(0x00, 0x24)
}
}
这就是在汇编中带有参数的自定义 revert 的完整代码样子:
// SPDX-License-Identifier: GPL-3.0
pragma solidity 0.8.27;
contract A {
function customRevertWithAssembly() public view {
assembly {
// Store the function selector at the memory location `0x00`
mstore(0x00, 0x8e4a23d600000000000000000000000000000000000000000000000000000000)
// Store the address
// N*ote that `caller()` in assembly is the same as `msg.sender` in Solidity.*
mstore(0x04, caller())
// 4 bytes for selector + 32 bytes for the address
revert(0x00, 0x24)
}
}
}
这就是 Solidity 将 revert 数据存储在内存中的方式,而最终将返回该 revert 数据的结果。
3. 汇编中带原因的 revert
当触发带有原因字符串的 revert(例如 revert("reason"))时,发生 revert 的合约将返回 Error(string) 的 ABI 编码,以及字符串参数。这与 Solidity 中带有原因的 require 工作方式相同。
要在汇编中模拟带有原因字符串的 revert,我们需要在内存中对同一个函数和字符串参数进行 ABI 编码。
我们以 revert("Unauthorized") 为例:
contract A {
function revertWithAString() external pure {
revert("Unauthorized");
}
}
如果在上面的合约中触发 revert("Unauthorized"); 函数,结果将如下面的示例所示。
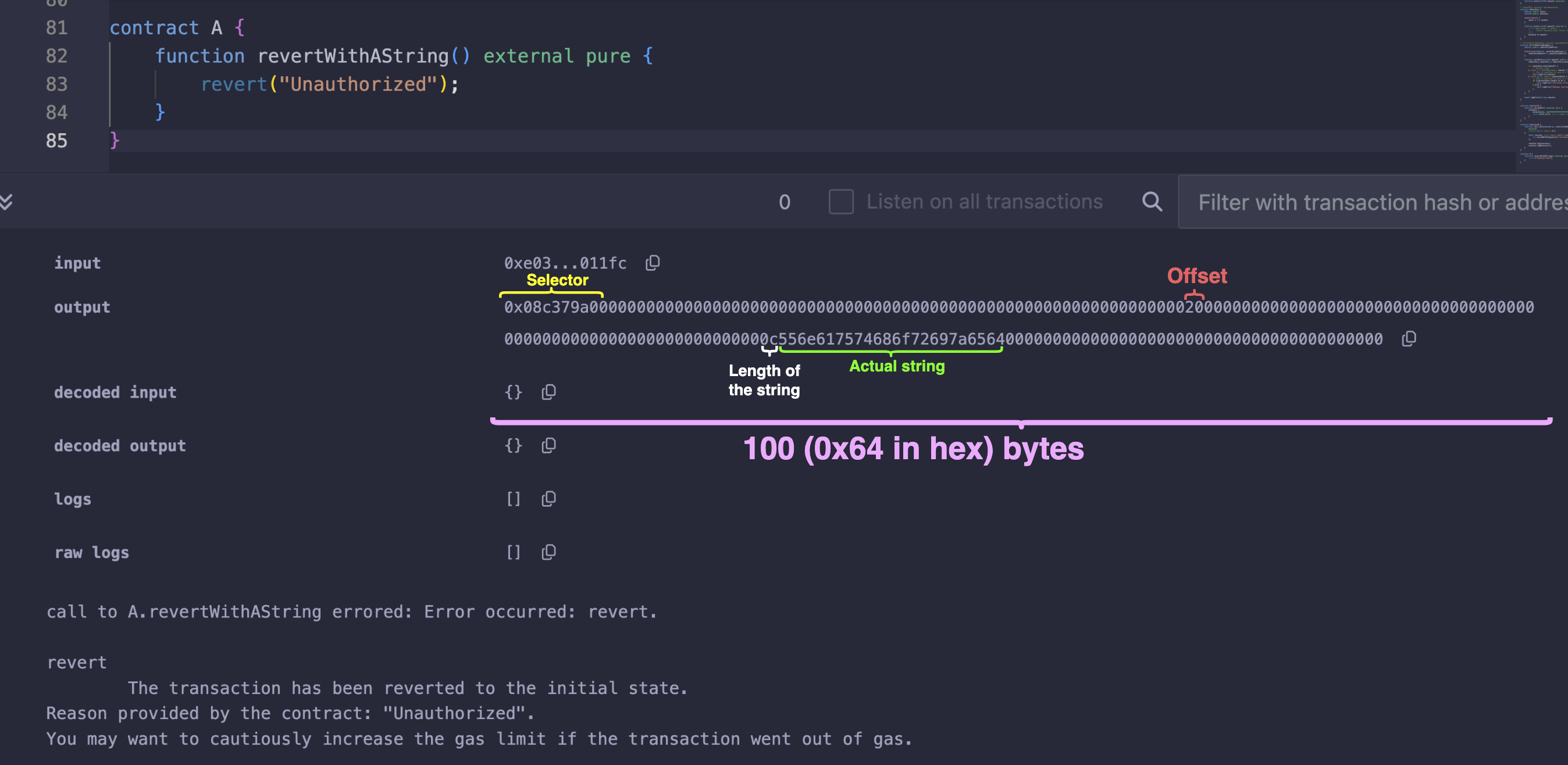
在本节中,我们将按照以下步骤,使用汇编来复现 Solidity 中带有字符串的 revert 行为:
- 在内存中存储
Error(string)的函数选择器 - 存储错误消息字符串的偏移量(offset)
- 存储错误消息字符串的长度
- 存储实际的错误消息
- 触发 revert
下面是汇编代码中对上述步骤的快速展示:
contract RevertErrorExample {
function revertWithAssembly() public pure {
assembly {
// store the selector
mstore(
0x00,
0x08c379a000000000000000000000000000000000000000000000000000000000
)
mstore(0x04, 0x20) // store the offset
mstore(0x24, 0xc) // store the length of the string
mstore(
0x44,
0x556E617574686F72697A65640000000000000000000000000000000000000000
) // store the actual data
revert(0x00, 0x64) // trigger a revert
}
}
}
我们逐行来检查这个汇编块。
1. 存储 Error(string) 的函数选择器
我们首先在起始内存位置(0x00)存储 函数选择器(function selector):
assembly {
mstore(0x00, 0x08c379a000000000000000000000000000000000000000000000000000000000) //Store the function selector
}
你可以通过 abi.encodeWithSignature("Error(string)") 导出函数选择器(keccak256("Error(string)") 的前 4 个字节),然后通过 bytes32 类型将其转换为 32 字节的字(word),如下所示:
bytes32 selector = bytes32(abi.encodeWithSignature("Error(string)"));
结果将是:
0x08c379a000000000000000000000000000000000000000000000000000000000
前 4 个字节(0x08c379a0)是选择器,后面用零填充以满足 32 字节的要求。
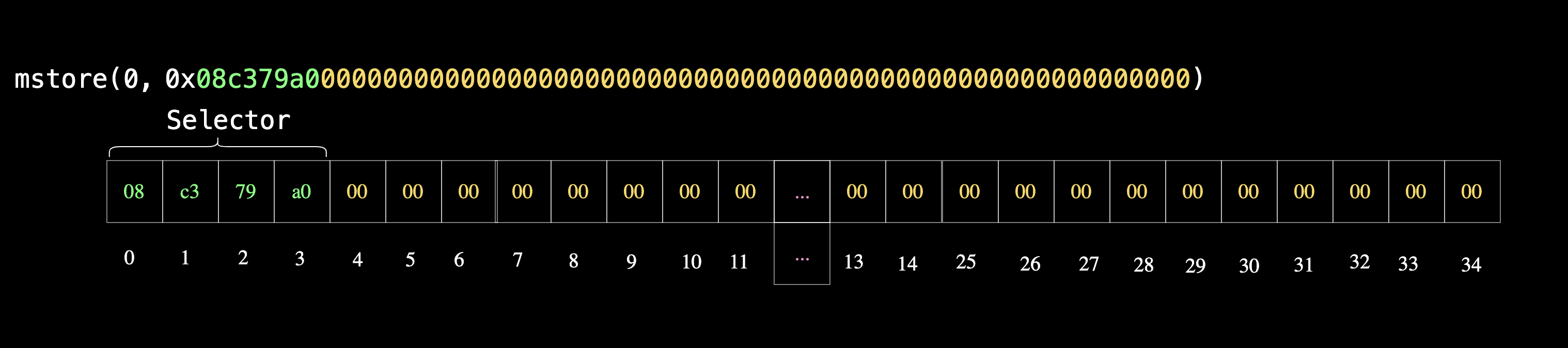
2. 存储错误消息字符串的偏移量
我们存储字符串错误的下一部分是偏移量。这里的偏移量为 32 字节(十六进制为 0x20)。
mstore(0x04, 0x20) // 4 is 0x04 in hex
还记得吗?我们提到过,如果两个内存位置发生重叠,就有可能覆盖内存,对吧?最初,函数选择器从第 0 个字节开始作为 32 字节的字进行存储。现在,我们要从第 4 个字节开始存储偏移量。
这意味着函数选择器中剩余的数据(在本例中为填充的零)将从第 4 个字节开始被替换,如下图所示:
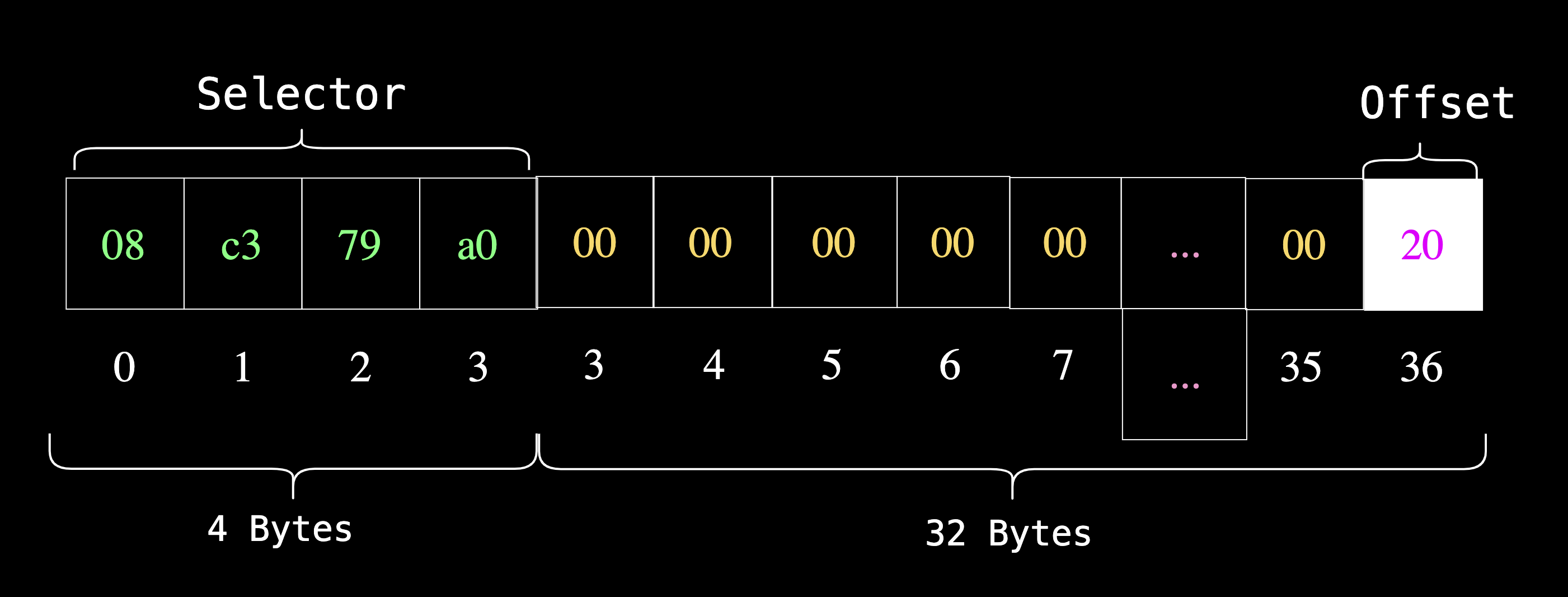
3. 存储错误消息字符串的长度
我们需要存储该字符串的第三部分是字符串数据的长度。回想一下,我们将函数选择器存储在 0x00 位置,它占用了 4 个字节。然后,下一个内存位置是存储在 0x04 的偏移量,它占用了 32 个字节。
这意味着 4 字节的选择器 + 32 字节的偏移量告诉我们,下一个内存插槽应该在 36 字节处,这就是我们要存储字符串长度的地方。
字符串 Unauthorized 的长度为 12(0xc)个字节。
mstore(0x24, 0xc) // 36 is 0x24 in hex
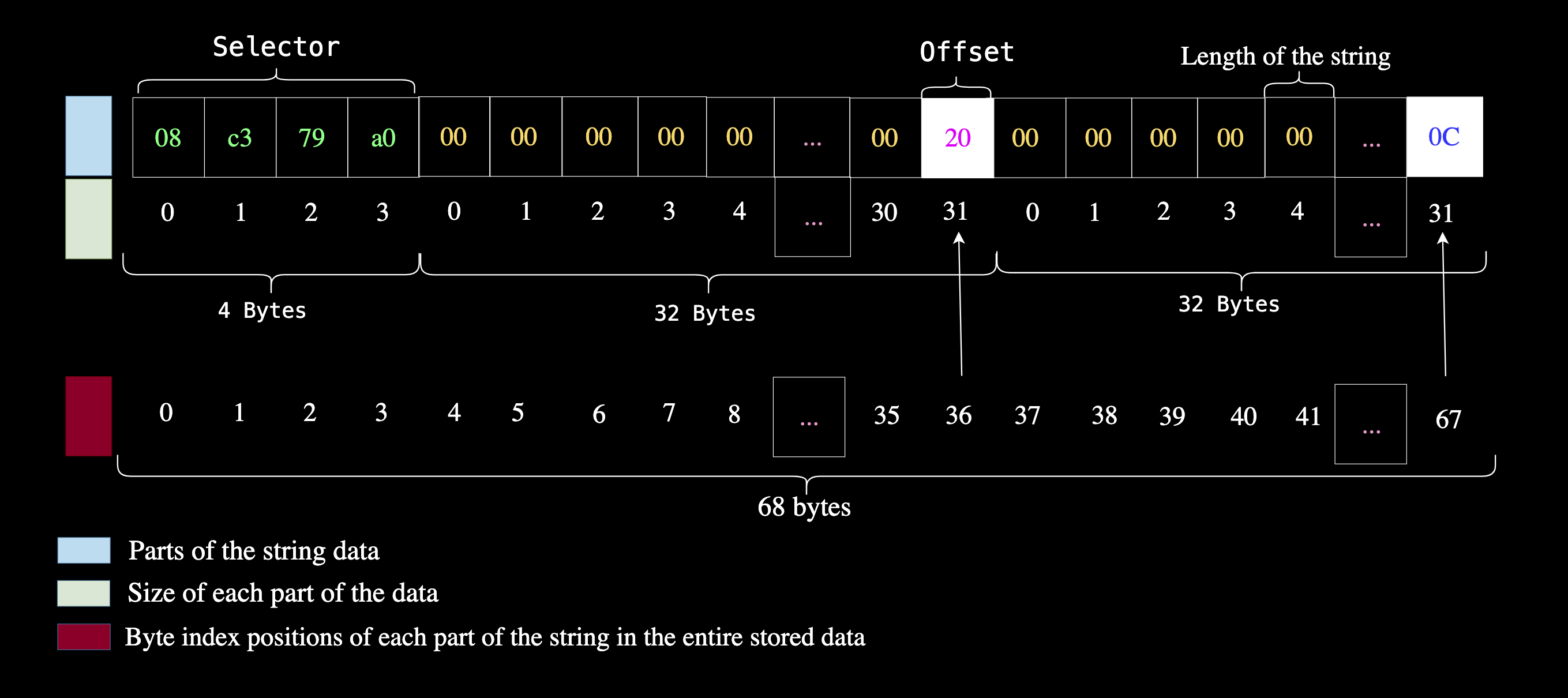
4. 存储实际的错误消息字符串
实际的字符串 Unauthorized 从开头的第 68(0x44)个字节开始存储,这对应于 4 字节选择器 + 32 字节偏移量 + 32 字节长度。到目前为止,我们已经写入了 100 字节的数据。
mstore(0x44, "Unauthorized") //68 is 0x44 in hex
// We can store Unathorized as hex as well. Unauthorized in hex is ⤵️
// 0x556E617574686F72697A65640000000000000000000000000000000000000000
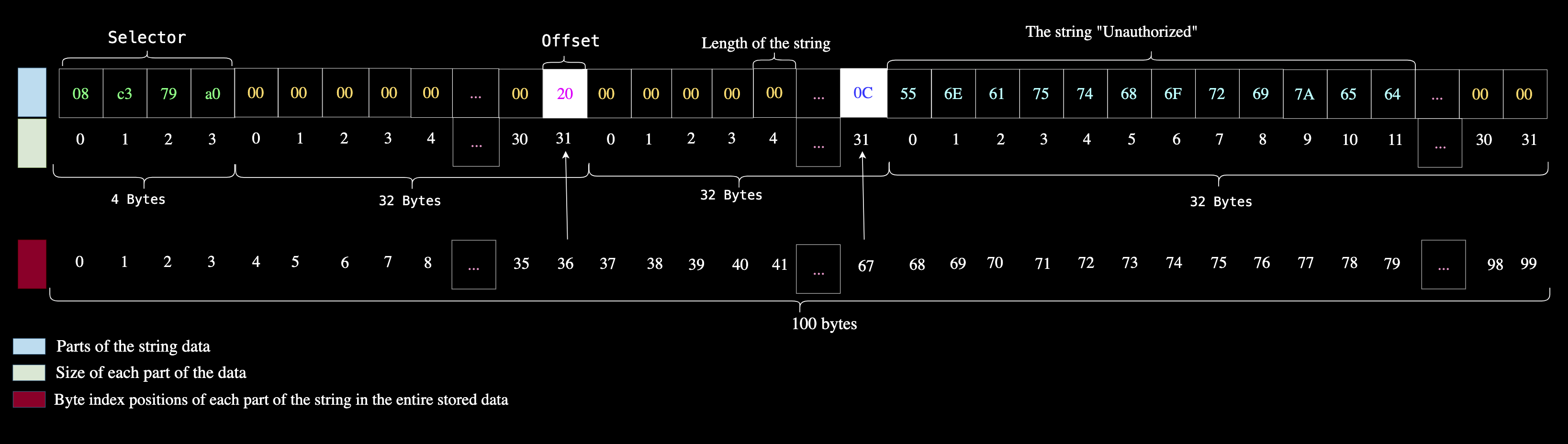
5. 触发 revert:
revert 操作使用起始内存位置和数据的总大小来触发 revert。
总大小将为 100(0x64)个字节:由 4 字节的选择器、32 字节的偏移量、32 字节的字符串长度以及 32 字节的字符串内容 “Unauthorized” 相加得到。
记住汇编中 revert 的模板:
revert(StartingMemorySlot, totalMemorySize)
我们将按如下方式触发 revert:
revert(0x00, 0x64) // 100 is 0x64 in hex
因此,触发时,revert 将返回刚好 100 字节的以下数据:
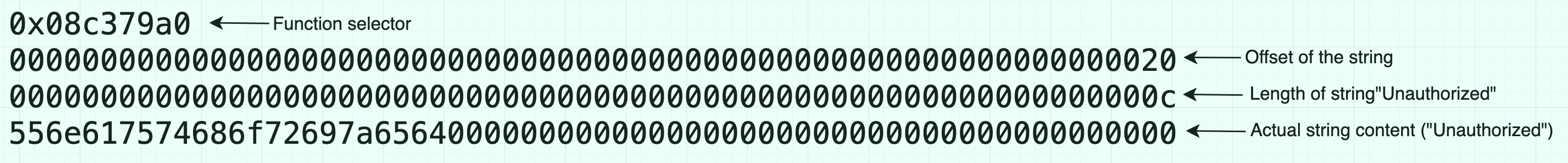
尽管字符串 Unauthorized 没有占满完整的 32 个字节,但由于长度参数为 0x0c,接收方会知道只需读取 12 个字节的数据。
如果我们将所有步骤放在一起,将得到以下代码:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.7.0 <0.9.0;
contract ContractA {
function revertWithAssembly() external pure {
assembly {
mstore(
0x00,
0x08c379a000000000000000000000000000000000000000000000000000000000
) // store the selector
mstore(0x04, 0x20) // store the offset
mstore(0x24, 0xc) // store the length of the string
mstore(
0x44,
0x556E617574686F72697A65640000000000000000000000000000000000000000
) // store the actual data
revert(0x00, 0x64) // trigger a revert
}
}
}
}
这是调用 revertWithAssembly() 函数时显示 revert 输出的截图。其结果与我们在 Solidity 中触发 revert("Unauthorized") 时看到的一样。
然而,两者的区别在于它们消耗的 Gas 量。在以下合约中运行这些 revert,可以查看它们在 Gas 成本上的差异。下面是我们用来测试 Gas 成本的代码:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.7.0 <0.9.0;
contract ContractA {
function revertWithAssembly() external pure {
assembly {
mstore(
0x00,
0x08c379a000000000000000000000000000000000000000000000000000000000
) // store the selector
mstore(0x04, 0x20) // store the offset
mstore(0x24, 0xc) // store the length of the string
mstore(
0x44,
0x556E617574686F72697A65640000000000000000000000000000000000000000
) // store the actual data
revert(0x00, 0x64) // trigger a revert
}
}
}
contract ContractB {
function revertWithoutAssembly() external pure {
revert("Unauthorized");
}
}
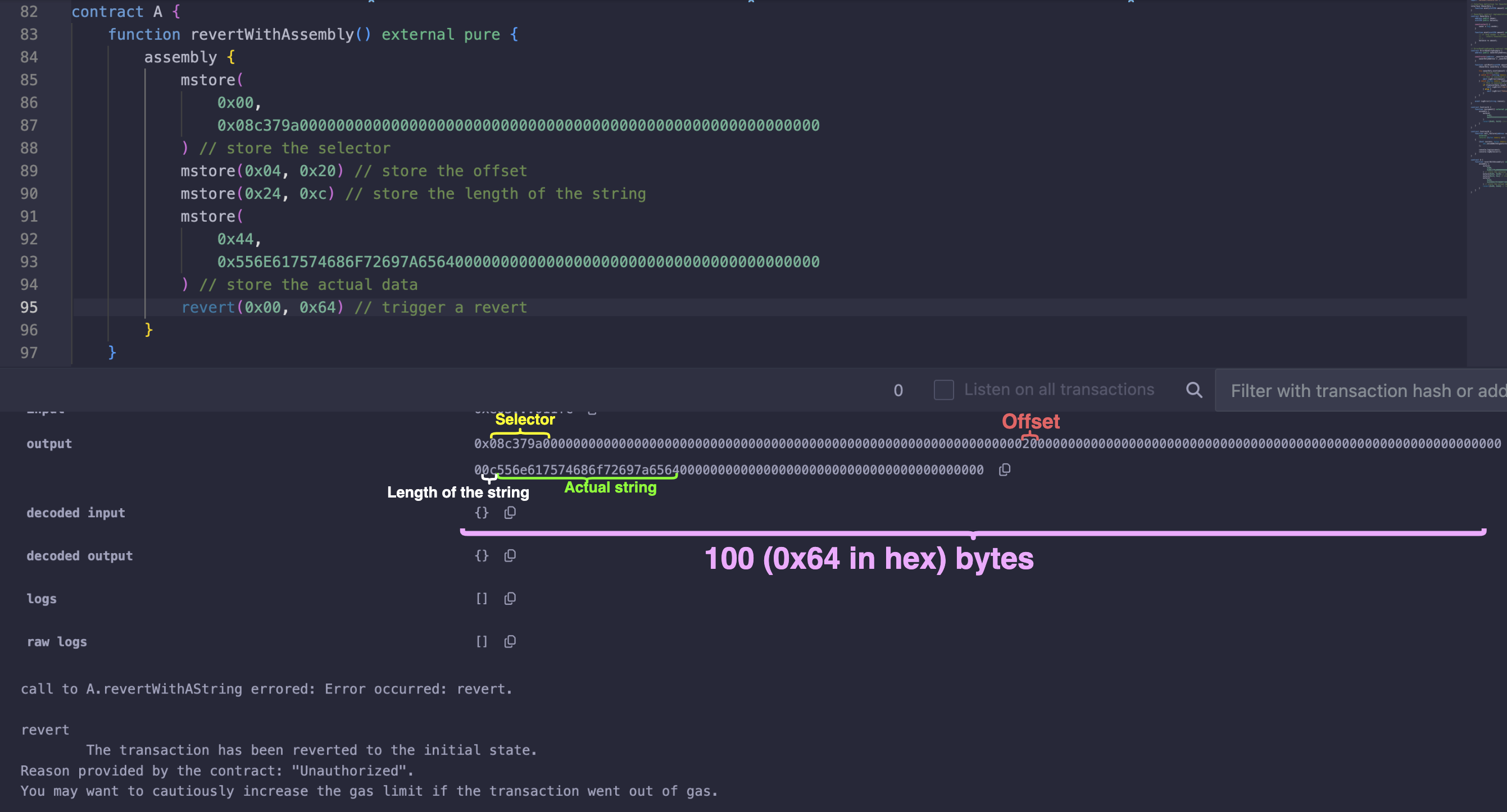
下图说明了 revertWithAssembly 函数和 revertWithoutAssembly 函数在 Gas 成本上的差异。
从上述测试中,我们节省了 273 Gas,因为不使用汇编的 revert 花费了 428 Gas,而使用汇编的 revert 花费了 155 Gas。差值为 273。
为了进一步验证该错误已正确构建,我们可以尝试在 try/catch 块中捕获错误,如下面的截图所示:
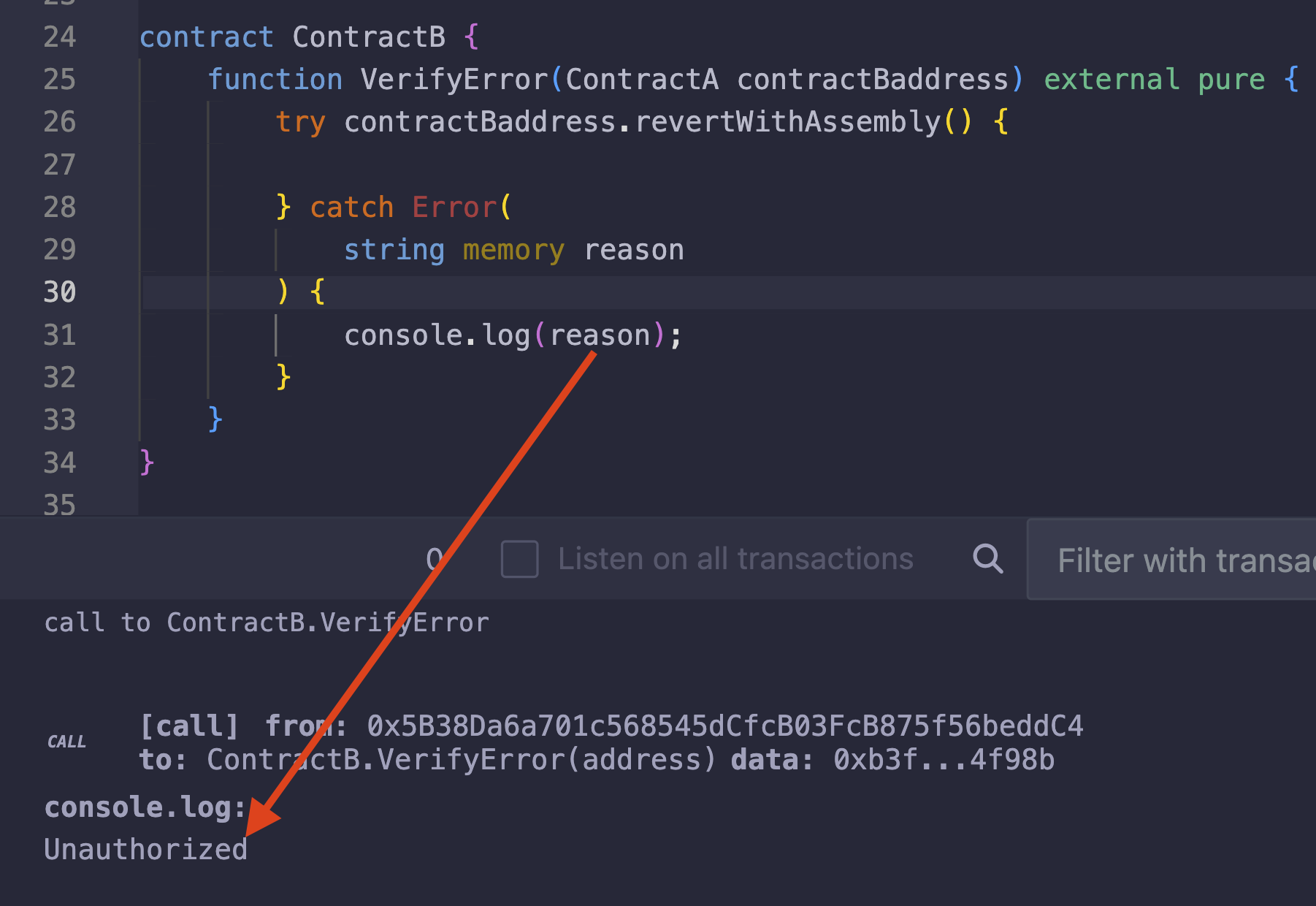
从上面的截图中,我们可以看到,错误如预期般在 Error 的 catch 块中被捕获,并且打印出的原因为 Unauthorized。
总结
在本指南中,我们通过使用内联汇编手动实现 Solidity revert,学习了 revert 的工作原理。
我们涵盖了以下内容:
mstore和mstore8的工作原理- 如何模拟以下类型的 revert:
- 不带原因的 revert
- 自定义错误 revert
- 带原因的 revert
我们还看到了如何通过使用汇编来进行 revert 以节省一些 Gas。我鼓励你自己去进行实验,因为这是全面理解一切工作原理的最佳方式。
编程愉快
本文由 Eze Sunday 与 RareSkills 合作编写。