在本教程中,我们将使用 Circom 实现 MD5 哈希,既用于计算哈希值,也用于在 Circom 中约束其计算的正确性。
尽管 MD5 哈希函数在密码学上并不安全(因为已经发现了碰撞),但其机制与密码学安全的哈希函数是相似的。
重要的是,MD5 哈希函数可以很快学会。以下这个 14 分钟的视频解释了 MD5 哈希的工作原理。我们建议您先观看该视频:
https://www.youtube.com/watch?v=5MiMK45gkTY
为了在不泄露 MD5 哈希原像的情况下创建我们知道原像的证明,我们需要证明我们正确执行了哈希的每一个步骤并产生了特定的结果。本教程将展示如何为每个状态转换设计约束。
具体来说,MD5 哈希包含以下子例程:
- 按位 AND、OR、NOT 和 XOR 操作
LeftRotate- 32 位数字相加并在 处溢出
Func函数,它使用按位运算符将寄存器B、C和D组合在一起- 开始时的填充步骤,在输入后添加一个 1 位,并放入输入的长度(以位为单位)
此外,MD5 的输出通常以大端序形式写成 128 位数字。假设我们有一个 128 位的值 0x1234567890ABCDEF1122334455667788
在大端序中,它将写为:
0x12 0x34 0x56 0x78 0x90 0xAB 0xCD 0xEF 0x11 0x22 0x33 0x44 0x55 0x66 0x77 0x88
在小端序中,它将是:
0x88 0x77 0x66 0x55 0x44 0x33 0x22 0x11 0xEF 0xCD 0xAB 0x90 0x78 0x56 0x34 0x12
我们需要一个单独的例程来将字节的顺序从小端序反转为大端序。大多数哈希实现输出的都是大端序,因此为了轻松地将我们的结果与已有的库进行比较,我们希望我们的实现也以大端序格式输出。稍后我们将为此创建一个 ToBytes 组件。
尽管存在大量的数组索引操作,但我们使用的索引是基于哈希的迭代次数确定性生成的,因此在哈希约束的任何地方都不需要 Quin 选择器 —— 我们可以对数组索引进行硬编码。
在 Python 中构建 MD5 原型
在构建像哈希函数这样复杂的东西时,先用如 Python 这种更熟悉且更易于调试的语言构建一个参考实现,然后再将 Python 代码转换为 Circom 是一个好主意。
这是 MD5 的 Python 实现(为了简单起见,它仅支持 448 位输入)。这段代码在很大程度上受到了 Utkarsh87 的另一个实现的启发。我们尽量使这些函数的行为具有“组件般”的特点,这样转换成 Circom 就会更加直接。
一些实现说明:
- 模 加法是通过先将数字相加,然后调用
Overflow32()函数来完成的。 - 我们接受的输入是字节数组,而不是位数组。
- 字节
0x80的二进制表示为10000000。这允许我们在输入末尾填充单个位。 - 输出采用大端序格式。
s = [7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21]
K = [0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391]
iter_to_index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12, 5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2, 0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9]
def Overflow32(x):
return x & 0xFFFFFFFF
def leftRotate(x, amount):
#x &= 0xFFFFFFFF
xo = Overflow32(x)
return Overflow32((xo << amount | xo >> (32 -amount)))
def func(B, C, D, i):
out = None
# note that i will be 1..64 inclusive
if i <= 16:
out = (B & C) | (~B & D)
elif i > 16 and i <= 32:
out = (D & B) | (~D & C)
elif i > 32 and i <= 48:
out = B ^ C ^ D
elif i > 48 and i <= 64:
out = C ^ (B | ~D)
else:
assert False, "1) What"
return out
# concatenates four bytes to become 32 bits
def To32BitWord(byte1, byte2, byte3, byte4):
return byte1 + byte2 * 2**8 + byte3 * 2**16 + byte4 * 2**24
# length is the byte where the data stops
# so if we have zero bytes, we write 0x80
# to byte 0
def md5(bytes, length):
data = bytearray(64)
msg = bytearray(bytes, 'ascii')
# 56 bytes, 64 is the max
assert length < 56, "too long"
if length < 56:
data[length] = 0x80
data[56] = (length * 8).to_bytes(1, byteorder='little')[0]
for i in range(57,64):
data[i] = 0x00
for i in range(0, length):
data[i] = msg[i]
# data is a len 64 array of bytes. However, it will be much easier to work
# on if we turn it into a len 16 array of 32 bit words
data_32 = [0] * 16
for i in range(0, 16):
data_32[i] = To32BitWord(data[4*i], data[4*i + 1], data[4*i + 2], data[4*i + 3])
# algo runs for 64 iterations with 4 registers, each using 32 bits
# we allocate 65, because the 0th will be the default starting value
buffer = [[0]*4 for _ in range(65)]
buffer[0][0] = 0x67452301
buffer[0][1] = 0xefcdab89
buffer[0][2] = 0x98badcfe
buffer[0][3] = 0x10325476
A = 0
B = 1
C = 2
D = 3
for i in range(1, 65):
F = func(buffer[i - 1][B], buffer[i - 1][C], buffer[i - 1][D], i)
G = iter_to_index[i - 1]
to_rotate = buffer[i-1][A] + F + K[i - 1] + data_32[iter_to_index[i - 1]]
rotated = leftRotate(to_rotate, s[i - 1])
new_B = Overflow32(buffer[i-1][B] + rotated)
buffer[i][A] = buffer[i - 1][D]
buffer[i][B] = new_B
buffer[i][C] = buffer[i - 1][B]
buffer[i][D] = buffer[i - 1][C]
final = [0,0,0,0]
for i, b in enumerate(buffer[64]):
final[i] = Overflow32((b + buffer[0][i]))
digest = final[0] + final[1] * 2**32 + final[2] * 2**64 + final[3] * 2**96
raw = digest.to_bytes(16, byteorder='little')
return int.from_bytes(raw, byteorder='big')
print(hex(md5("RareSkills", 10)))
必备组件
Overflow32
Overflow32 模拟了在虚拟机中发生在 处的 32 位溢出:
template Overflow32() {
signal input in;
signal output out;
component n2b = Num2Bits(252);
component b2n = Bits2Num(32);
n2b.in <== in;
for (var i = 0; i < 32; i++) {
n2b.out[i] ==> b2n.in[i];
}
b2n.out ==> out;
}
LeftRotate
LeftRotate 将位进行旋转,就像它们在一个环形缓冲区中一样:
template LeftRotate(s) {
signal input in;
signal output out;
component n2b = Num2Bits(32);
component b2n = Bits2Num(32);
n2b.in <== in;
for (var i = 0; i < 32; i++) {
b2n.in[(i + s) % 32] <== n2b.out[i];
}
out <== b2n.out;
}
按位 AND、OR、XOR 和 NOT
以下模板是在我们关于 32 位模拟的教程中构建的:
template BitwiseAnd32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Ands[32];
for (var i = 0; i < 32; i++) {
Ands[i] = AND();
Ands[i].a <== n2ba.out[i];
Ands[i].b <== n2bb.out[i];
Ands[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseOr32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Ors[32];
for (var i = 0; i < 32; i++) {
Ors[i] = OR();
Ors[i].a <== n2ba.out[i];
Ors[i].b <== n2bb.out[i];
Ors[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseXor32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Xors[32];
for (var i = 0; i < 32; i++) {
Xors[i] = XOR();
Xors[i].a <== n2ba.out[i];
Xors[i].b <== n2bb.out[i];
Xors[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseNot32() {
signal input in;
signal output out;
// range check
component n2ba = Num2Bits(32);
n2ba.in <== in;
component b2n = Bits2Num(32);
component Nots[32];
for (var i = 0; i < 32; i++) {
Nots[i] = NOT();
Nots[i].in <== n2ba.out[i];
Nots[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
Func
Func 接收寄存器 B、C 和 D,并将它们组合成单个输出 —— 而这种组合方式取决于我们当前所在的迭代轮次:
template Func(i) {
assert(i <= 64);
signal input b;
signal input c;
signal input d;
signal output out;
if (i <= 16) {
signal bAndc;
component a1 = BitwiseAnd32();
a1.in[0] <== b;
a1.in[1] <== c;
component a2 = BitwiseAnd32();
component n1 = BitwiseNot32();
n1.in <== b;
a2.in[0] <== n1.out;
a2.in[1] <== d;
component o1 = BitwiseOr32();
o1.in[0] <== a1.out;
o1.in[1] <== a2.out;
out <== o1.out;
}
else if (i > 16 && i <= 32) {
component a1 = BitwiseAnd32();
a1.in[0] <== d;
a1.in[1] <== b;
component n1 = BitwiseNot32();
n1.in <== d;
component a2 = BitwiseAnd32();
a2.in[0] <== n1.out;
a2.in[1] <== c;
component o1 = BitwiseOr32();
o1.in[0] <== a1.out;
o1.in[1] <== a2.out;
out <== o1.out;
}
else if (i > 32 && i <= 48) {
component x1 = BitwiseXor32();
component x2 = BitwiseXor32();
x1.in[0] <== b;
x1.in[1] <== c;
x2.in[0] <== x1.out;
x2.in[1] <== d;
out <== x2.out;
}
// i must be <= 64 by the assert
// statement above
else {
component o1 = BitwiseOr32();
component n1 = BitwiseNot32();
n1.in <== d;
o1.in[0] <== n1.out;
o1.in[1] <== b;
component x1 = BitwiseXor32();
x1.in[0] <== o1.out;
x1.in[1] <==c;
out <== x1.out;
}
输入填充
为了简化,我们的哈希函数接受字节数组作为输入,而不是位数组。此外,我们将输入长度限制为 56 个字节,这样就可以在哈希使用的 64 个字节(512 位)输入的第 56 个字节索引处对插入长度进行硬编码。
由于输入最大为 56 个字节,我们必须用于表示长度的数字不会超过 448 位,这最多只需要 2 个字节来存储。
// n is the number of bytes
template Padding(n) {
// 56 bytes = 448 bits
assert(n < 56);
signal input in[n];
// 64 bytes = 512 bits
signal output out[64];
for (var i = 0; i < n; i++) {
out[i] <== in[i];
}
// add 128 = 0x80 to pad the 1 bit (0x80 = 10000000b)
out[n] <== 128;
// pad the rest with zeros
for (var i = n + 1; i < 56; i++) {
out[i] <== 0;
}
var lenBits = n * 8;
if (lenBits < 256) {
out[56] <== lenBits;
}
else {
var lowOrderBytes = lenBits % 256;
var highOrderBytes = lenBits \ 256;
out[56] <== lowOrderBytes;
out[57] <== highOrderBytes;
}
}
Num2Bytes
为了改变字节序,我们需要将信号 in 转换为字节数组 out:
// n is the number of bytes
template ToBytes(n) {
signal input in;
signal output out[n];
component n2b = Num2Bits(n * 8);
n2b.in <== in;
component b2ns[n];
for (var i = 0; i < n; i++) {
b2ns[i] = Bits2Num(8);
for (var j = 0; j < 8; j++) {
b2ns[i].in[j] <== n2b.out[8*i + j];
}
out[i] <== b2ns[i].out;
}
}
最终解决方案
下面的代码将所有组件组合在一起以执行 MD5 哈希。它还会将结果转换为大端序形式。读者可以在 zkrepl 中测试这段代码。
include "circomlib/bitify.circom";
include "circomlib/gates.circom";
template BitwiseAnd32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Ands[32];
for (var i = 0; i < 32; i++) {
Ands[i] = AND();
Ands[i].a <== n2ba.out[i];
Ands[i].b <== n2bb.out[i];
Ands[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseOr32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Ors[32];
for (var i = 0; i < 32; i++) {
Ors[i] = OR();
Ors[i].a <== n2ba.out[i];
Ors[i].b <== n2bb.out[i];
Ors[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseXor32() {
signal input in[2];
signal output out;
// range check
component n2ba = Num2Bits(32);
component n2bb = Num2Bits(32);
n2ba.in <== in[0];
n2bb.in <== in[1];
component b2n = Bits2Num(32);
component Xors[32];
for (var i = 0; i < 32; i++) {
Xors[i] = XOR();
Xors[i].a <== n2ba.out[i];
Xors[i].b <== n2bb.out[i];
Xors[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
template BitwiseNot32() {
signal input in;
signal output out;
// range check
component n2ba = Num2Bits(32);
n2ba.in <== in;
component b2n = Bits2Num(32);
component Nots[32];
for (var i = 0; i < 32; i++) {
Nots[i] = NOT();
Nots[i].in <== n2ba.out[i];
Nots[i].out ==> b2n.in[i];
}
b2n.out ==> out;
}
// n is the number of bytes
template ToBytes(n) {
signal input in;
signal output out[n];
component n2b = Num2Bits(n * 8);
n2b.in <== in;
component b2ns[n];
for (var i = 0; i < n; i++) {
b2ns[i] = Bits2Num(8);
for (var j = 0; j < 8; j++) {
b2ns[i].in[j] <== n2b.out[8*i + j];
}
out[i] <== b2ns[i].out;
}
}
// n is the number of bytes
template Padding(n) {
// 56 bytes = 448 bits
assert(n < 56);
signal input in[n];
// 64 bytes = 512 bits
signal output out[64];
for (var i = 0; i < n; i++) {
out[i] <== in[i];
}
// add 128 = 0x80 to pad the 1 bit (0x80 = 10000000b)
out[n] <== 128;
// pad the rest with zeros
for (var i = n + 1; i < 56; i++) {
out[i] <== 0;
}
var lenBits = n * 8;
if (lenBits < 256) {
out[56] <== lenBits;
}
else {
var lowOrderBytes = lenBits % 256;
var highOrderBytes = lenBits \ 256;
out[56] <== lowOrderBytes;
out[57] <== highOrderBytes;
}
}
template Overflow32() {
signal input in;
signal output out;
component n2b = Num2Bits(252);
component b2n = Bits2Num(32);
n2b.in <== in;
for (var i = 0; i < 32; i++) {
n2b.out[i] ==> b2n.in[i];
}
b2n.out ==> out;
}
template LeftRotate(s) {
signal input in;
signal output out;
component n2b = Num2Bits(32);
component b2n = Bits2Num(32);
n2b.in <== in;
for (var i = 0; i < 32; i++) {
b2n.in[(i + s) % 32] <== n2b.out[i];
}
out <== b2n.out;
}
template Func(i) {
assert(i <= 64);
signal input b;
signal input c;
signal input d;
signal output out;
if (i < 16) {
component a1 = BitwiseAnd32();
a1.in[0] <== b;
a1.in[1] <== c;
component a2 = BitwiseAnd32();
component n1 = BitwiseNot32();
n1.in <== b;
a2.in[0] <== n1.out;
a2.in[1] <== d;
component o1 = BitwiseOr32();
o1.in[0] <== a1.out;
o1.in[1] <== a2.out;
out <== o1.out;
}
else if (i >= 16 && i < 32) {
// (D & B) | (~D & C)
component a1 = BitwiseAnd32();
a1.in[0] <== d;
a1.in[1] <== b;
component n1 = BitwiseNot32();
n1.in <== d;
component a2 = BitwiseAnd32();
a2.in[0] <== n1.out;
a2.in[1] <== c;
component o1 = BitwiseOr32();
o1.in[0] <== a1.out;
o1.in[1] <== a2.out;
out <== o1.out;
}
else if (i >= 32 && i < 48) {
component x1 = BitwiseXor32();
component x2 = BitwiseXor32();
x1.in[0] <== b;
x1.in[1] <== c;
x2.in[0] <== x1.out;
x2.in[1] <== d;
out <== x2.out;
}
// i must be < 64 by the assert statement above
else {
component o1 = BitwiseOr32();
component n1 = BitwiseNot32();
n1.in <== d;
o1.in[0] <== n1.out;
o1.in[1] <== b;
component x1 = BitwiseXor32();
x1.in[0] <== o1.out;
x1.in[1] <==c;
out <== x1.out;
}
}
// n is the number of bytes
template MD5(n) {
var s[64] = [7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21];
var K[64] = [0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391];
var iter_to_index[64] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12,
5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2,
0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9];
signal input in[n];
signal inp[64];
component Pad = Padding(n);
for (var i = 0; i < n; i++) {
Pad.in[i] <== in[i];
}
for (var i = 0; i < 64; i++) {
Pad.out[i] ==> inp[i];
}
signal data32[16];
for (var i = 0; i < 16; i++) {
data32[i] <== inp[4 * i] + inp[4 * i + 1] * 2**8 + inp[4 * i + 2] * 2**16 + inp[4 * i + 3] * 2**24;
}
var A = 0;
var B = 1;
var C = 2;
var D = 3;
signal buffer[65][4];
buffer[0][A] <== 1732584193;
buffer[0][B] <== 4023233417;
buffer[0][C] <== 2562383102;
buffer[0][D] <== 271733878;
component Funcs[64];
signal toRotates[64];
component SelectInputWords[64];
component LeftRotates[64];
component Overflow32s[64];
component Overflow32s2[64];
for (var i = 0; i < 64; i++) {
Funcs[i] = Func(i);
Funcs[i].b <== buffer[i][B];
Funcs[i].c <== buffer[i][C];
Funcs[i].d <== buffer[i][D];
Overflow32s[i] = Overflow32();
Overflow32s[i].in <== buffer[i][A] + Funcs[i].out + K[i] + data32[iter_to_index[i]];
// rotated = rotate(to_rotate, s[i])
toRotates[i] <== Overflow32s[i].out;
LeftRotates[i] = LeftRotate(s[i]);
LeftRotates[i].in <== toRotates[i];
// new_B = rotated + B
Overflow32s2[i] = Overflow32();
Overflow32s2[i].in <== LeftRotates[i].out + buffer[i][B];
// store into the next state
buffer[i + 1][A] <== buffer[i][D];
buffer[i + 1][B] <== Overflow32s2[i].out;
buffer[i + 1][C] <== buffer[i][B];
buffer[i + 1][D] <== buffer[i][C];
}
component addA = Overflow32();
component addB = Overflow32();
component addC = Overflow32();
component addD = Overflow32();
// we hardcode initial state because we only
// process one 512 bit block
addA.in <== 1732584193 + buffer[64][A];
addB.in <== 4023233417 + buffer[64][B];
addC.in <== 2562383102 + buffer[64][C];
addD.in <== 271733878 + buffer[64][D];
signal littleEndianMd5;
littleEndianMd5 <== addA.out + addB.out * 2**32 + addC.out * 2**64 + addD.out * 2**96;
// convert the answer to bytes and reverse
// the bytes order to make it big endian
component Tb = ToBytes(16);
Tb.in <== littleEndianMd5;
// sum the bytes in reverse
var acc;
for (var i = 0; i < 16; i++) {
acc += Tb.out[15 - i] * 2**(i * 8);
}
signal output out;
out <== acc;
}
component main = MD5(10);
// The result out =
// "RareSkills" in ascii to decimal
/* INPUT = {"in": [82, 97, 114, 101, 83, 107, 105, 108, 108, 115]} */
// The result is 246193259845151292174181299259247598493
// The MD5 hash of "RareSkills" is 0xb93718dd21d2f5081239d7a16cf69b9d when converted to decimal is 246193259845151292174181299259247598493
零知识友好型(ZK-friendly)哈希的动机
由上述代码生成的 R1CS 长度超过五万两千行,如下图高亮部分所示。要减小电路的规模还有很多优化空间,特别是每次使用域元素时,不要都将它们转换为 32 位数组。
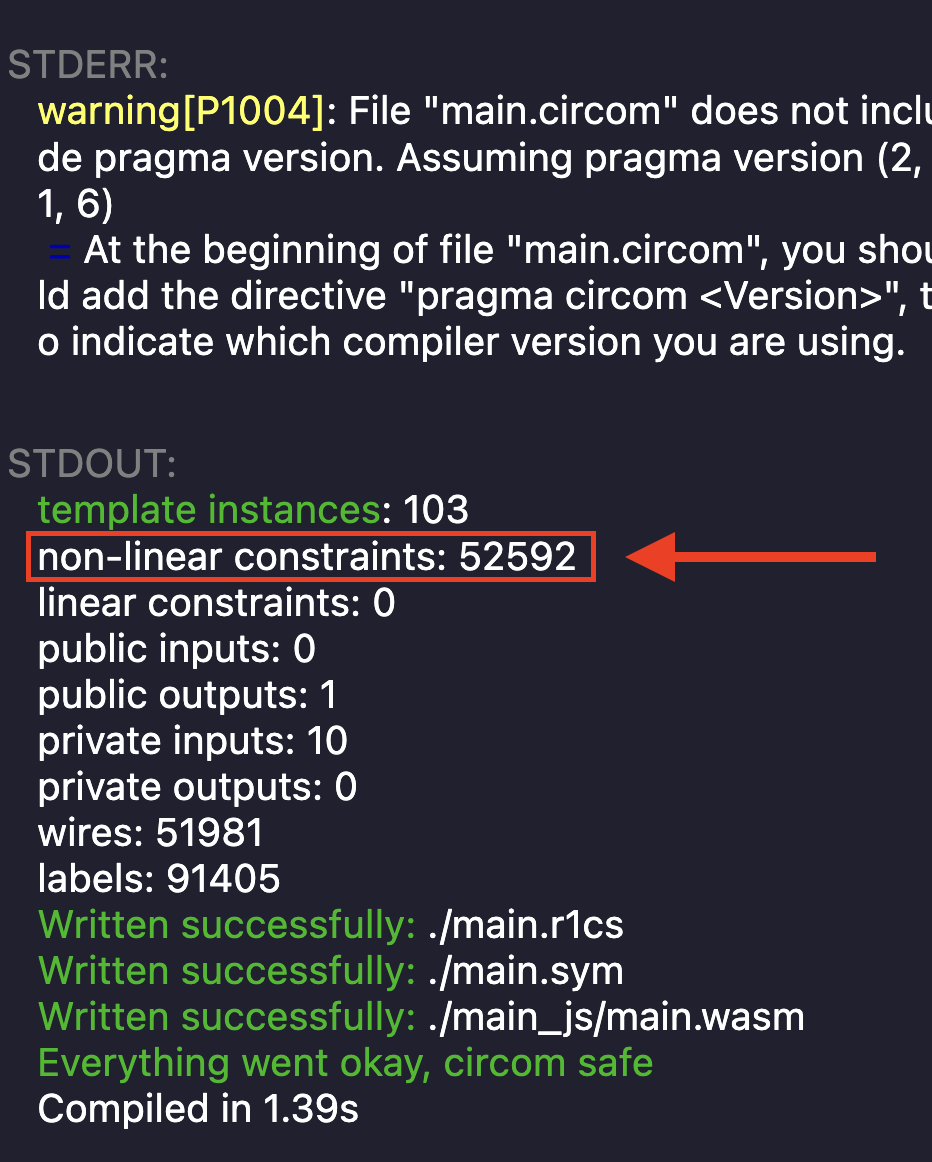
然而,在 MD5(及其他现代哈希算法)中,每个字都是 32 位的,因此与常规代码相比,它将需要 32 倍的信号来表示。
在接下来的章节中,我们将学习直接在原生有限域上(而不是在 32 位字上)进行操作的哈希算法,并避免像 XOR 这种需要将信号分解为位的高昂开销操作。