在上一篇教程中,我们学习了如何读取传递给程序的账户。我们看到,调用 account.try_borrow_data() 会返回一个指向账户数据字段的原始字节切片引用,例如 [0x01, 0x00, 0x00, 0x00]。
Solana 将所有账户数据存储为字节。为了处理像 Rust 结构体这样的高级数据结构,我们使用序列化将结构体转换为字节以便在链上存储,并在读取时使用反序列化将这些字节转换回结构体。Solana 使用 Borsh 作为其标准的序列化格式。
本文将解释 Borsh 序列化是如何工作的,以及如何解读这些原始字节。
在本教程中,我们将展示以下内容:
- 什么是序列化,以及 Borsh 序列化在 Solana 中是如何工作的
- 如何读取和解读序列化后的账户数据
- 当你尝试读取一个没有数据的账户时,它是什么样子的
什么是序列化和反序列化?
序列化是将数据结构(如 Rust 结构体或字符串)转换为可以存储或传输的字节序列的过程。反序列化则是相反的过程——将这些字节转换回原始的数据结构。
例如,如果你有一个计数器值为 42 的结构体(以 u64 存储),序列化会将其转换为 8 个字节:[0x2A, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00]。第一个字节 0x2A 以小端序(little-endian)保存该值的最低有效字节,其余 7 个字节为零,因为 u64 在内存中占用 8 个字节。随后,当你需要读取该数据时,反序列化会将这些字节转换回你的结构体。
什么是 Borsh 序列化?
Borsh(Binary Object Representation Serializer for Hashing)是一种序列化格式,它定义了将 Rust 结构体转换为字节以及反向转换的规则。Solana 使用 Borsh 作为其标准的序列化格式,因为它是:
- 确定性的(Deterministic):相同的数据总是产生相同的字节(相同的字节也总是还原出相同的数据)
- 紧凑的(Compact):它高效地存储数据,字段之间没有任何额外的元数据或填充(固定大小的类型使用其标准字节大小,可变长度的类型仅使用它们所需的字节外加一个 4 字节的长度前缀)
borsh Rust crate 实现了 Solana 程序使用的序列化格式。
Solana 程序使用 Borsh 来序列化指令数据和链上账户数据。对于账户,Borsh 将 Rust 结构体及其字段(字符串、整数、布尔值、向量等)转换为存储在账户数据字段中的原始字节。
Borsh 序列化是如何工作的
在原生的 Rust 程序中,我们定义结构体来表示我们想要存储的账户数据(类似于你如何在 Anchor 中定义账户结构体)。然后 Borsh 将这些结构体序列化为字节,并填充到账户的 data 字段中。序列化时,结构体字段会按照声明的顺序连续地排列在账户的数据字段中。
基本流程如下图所示:

该图显示:
- 序列化:你的 Rust 结构体(例如
CounterData { count: 42 })使用 Borsh 转换为原始字节 - 存储:这些字节被存储在链上账户的数据字段中
- 反序列化:当读取该账户时,Borsh 将这些字节转换回你的结构体
Borsh 序列化后的 Solana 账户数据是什么样子的?
在 Anchor 中,序列化被抽象化了,但在原生的 Rust 程序中,我们需要为结构体添加 #[derive(BorshSerialize, BorshDeserialize)] 属性。这会告诉 Borsh 库在编译时自动生成序列化和反序列化代码。
例如,这里有一个 CounterData 结构体,它将计数器值存储为 u64:
#[derive(BorshSerialize, BorshDeserialize)]
pub struct CounterData {
pub count: u64,
}
如果 count 值为 42,BorshSerialize 属性将把这个结构体序列化为:

具体过程如下:
- Borsh 获取我们的计数器值(42)并将其转换为十六进制:十进制的 42 = 十六进制的
0x2A - 由于 count 被定义为
u64,Borsh 使用小端序格式的 8 个字节来表示它 - 在
0x2A之后的剩余 7 个字节是零,因为u64占用 8 个字节
Borsh 如何序列化可变长度数据
在查看更复杂的示例之前,让我们先了解 Borsh 是如何处理没有固定长度的数据类型的,比如字符串和向量。
不同于 u64、bool 和 u8 这些无论值是多少都使用相同字节数的固定数据类型,诸如 String 和 Vec<T> 这类可变长度数据类型的大小取决于它们的内容。
对于可变长度类型,Borsh 使用长度前缀(length prefixing):它首先写入数据的大小,然后再写入实际数据。这会告诉 Borsh 在反序列化时要读取多少个字节(如果没有它,Borsh 就无法知道一个字段在哪里结束以及另一个字段从哪里开始)。
它的工作原理如下:
- 首先,Borsh 将数据的长度序列化为小端序格式的
u32(4 字节) - 然后,它序列化实际的数据字节
例如,如果我们有一个字符串 “hi”:
- 首先,Borsh 将长度序列化为小端序的
u32:[0x02, 0x00, 0x00, 0x00](2 字节)。由于长度以u32存储,理论上字符串的最大大小为2^32 - 1个字节 - 最后,Borsh 序列化 “hi” 实际的 UTF-8 字节:
[0x68, 0x69]
这给我们带来了最终结果:
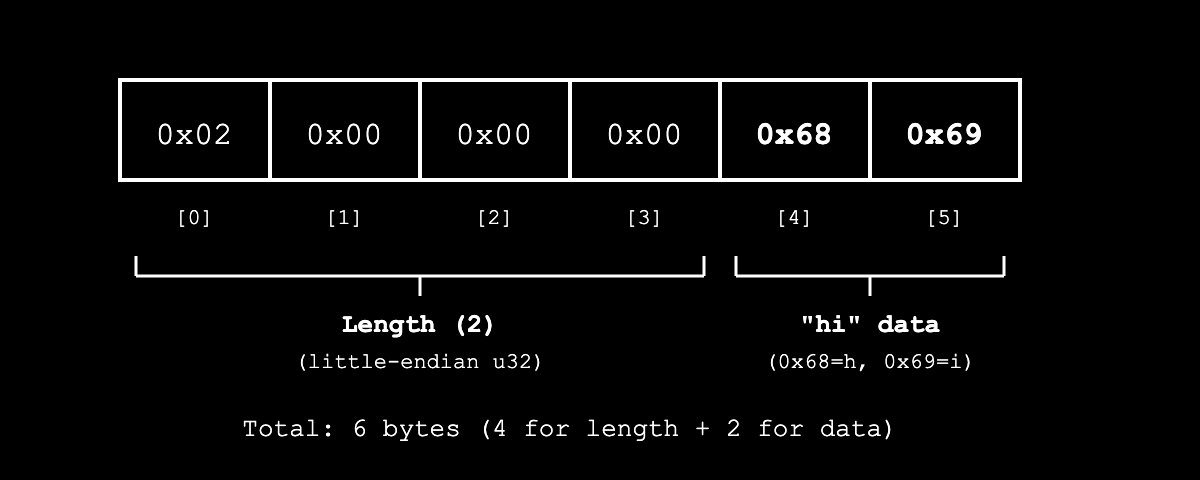
这个长度前缀帮助 Borsh 准确地知道在反序列化期间,需要为一个可变长度类型读取多少个字节。
Borsh 如何序列化具有多个字段的 Solana 账户结构体?
假设我们有一个具有多个字段的 UserData 结构体,用于表示存储账户的用户信息:
#[derive(BorshSerialize, BorshDeserialize)]
struct UserData {
active: bool, // 1 byte: 0x01 for true, 0x00 for false
age: u8, // 1 byte
name: String, // 4 bytes (length) + UTF-8 bytes
scores: Vec<u8>, // 4 bytes (length) + individual u8 values
}
let user = UserData {
active: true,
age: 25,
name: "hi".to_string(),
scores: vec![95, 87, 92],
};
Borsh 严格按照结构体中定义字段的顺序对字段进行序列化,而不管它们是固定大小还是可变长度(动态大小)的。固定大小和可变长度字段的位置不会影响 Borsh 处理它们的方式——每个字段都按照其类型的规则进行序列化(固定大小类型使用其标准字节大小,可变长度类型使用长度前缀),并且所有字段都按照声明顺序依次排列。具体过程如下:
- 首先,Borsh 将
active字段(true)序列化为 1 字节:0x01。 - 然后将
age(25)序列化为 1 字节:0x19。 - 接下来,它序列化
name字段(“hi”)。由于字符串是动态大小的,Borsh 采用长度前缀的方法:- 它首先将长度写为小端序的
u32:[0x02, 0x00, 0x00, 0x00](2 字节) - 然后写入 “hi” 的实际 UTF-8 字节(
[0x68, 0x69])
- 它首先将长度写为小端序的
- 最后,它使用同样的长度前缀方法序列化
scores向量[95, 87, 92]:- 它将向量长度写为小端序的
u32(3 项 =[0x03, 0x00, 0x00, 0x00]) - 然后写入每个
u8值:[0x5F, 0x57, 0x5C]。
- 它将向量长度写为小端序的
所有这些字节都按照字段声明的顺序拼接在一起,从而得到我们的最终结果:

这展示了 Borsh 如何处理具有多个字段(包括 String 和 Vec)的账户。
如何读回序列化后的账户数据?
为了从 Solana 账户中取回我们的数据,我们需要对其进行反序列化。Borsh 库提供了一个 try_from_slice 函数,该函数通过按照当初序列化时的顺序读取字节并重建原始结构体来处理反序列化。
因此,对于传递给原生程序的 Solana 账户,其流程为:
- 从账户中读取原始字节
- 调用 Borsh crate 中的
try_from_slice,将这些字节反序列化为原始结构体
下面的代码展示了其在实际中的应用。下方的 read_user_account 函数是一个概念性的表示,演示了如何使用 try_from_slice 进行反序列化。account 参数代表一个包含上文“Borsh 如何序列化具有多个字段的 Solana 账户结构体?”部分中的 UserData 结构体(包含 active、age、name 和 scores 字段)的常规 Solana 账户。
use borsh::BorshDeserialize;
use solana_program::account_info::AccountInfo;
pub fn read_user_account(account: &AccountInfo) -> ProgramResult {
// First, we get the raw bytes from the account
let data = account.try_borrow_data()?;
// The raw bytes in the account's data field:
// [0x01, 0x19, 0x02, 0x00, 0x00, 0x00, 0x68, 0x69, 0x03, 0x00, 0x00, 0x00, 0x5F, 0x57, 0x5C]
// Then we use Borsh to deserialize these bytes back into our struct
let _user = UserData::try_from_slice(&data)?;
// We get back our original data:
// UserData { active: true, age: 25, name: "hi", scores: [95, 87, 92] }
Ok(())
}
Borsh 对其他常见类型的序列化规则
对于 Solana 账户中使用的其他常见字段类型,如布尔值、数字(u32、i32、u64)和 Pubkey,Borsh 遵循以下规则:
| 类型 | 大小 | 格式 | 示例 |
|---|---|---|---|
bool |
1 字节 | true 为 0x01,false 为 0x00 |
true → [0x01] |
u8 |
1 字节 | 原始值 | 42 → [0x2A] |
u16 |
2 字节 | 小端序 | 42 → [0x2A, 0x00] |
u32 |
4 字节 | 小端序 | 42 → [0x2A, 0x00, 0x00, 0x00] |
u64 |
8 字节 | 小端序 | 42 → [0x2A, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00] |
u128 |
16 字节 | 小端序 | 类似的 16 字节模式 |
i8、i16、i32、i64、i128 |
与无符号类型相同 | 小端序,二进制补码 | -1 作为 i8 → [0xFF],正值的序列化与无符号类型相同 |
Pubkey |
32 字节 | 原始字节 | 公钥的 32 个字节 |
我们前面看到的拼接原则在这里同样适用。当你的结构体包含这些类型时,Borsh 会按顺序遍历每个字段并将所有字节拼接在一起,没有任何填充或额外的元数据(这使得序列化后的数据尽可能小)。
在不反序列化的情况下读取原始字节
如果你了解内存布局,则可以在不进行反序列化的情况下从账户数据中手动读取特定字段。在生产代码中不建议这样做(它很容易出错),但这有助于理解 Borsh 的工作原理。
假设我们有前面提到的 CounterData 账户,它只有 count: 42 字段,序列化为 [0x2A, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00]。我们可以通过提取前 8 个字节并将其转换为 u64,来手动读取 count 值:
pub fn read_count_manually(account: &AccountInfo) -> ProgramResult {
let data = account.try_borrow_data()?;
// count is a u64, so it occupies the first 8 bytes
if data.len() >= 8 {
let count_bytes = &data[0..8];
let count = u64::from_le_bytes(count_bytes.try_into().unwrap());
msg!("Count value: {}", count); // This will print: Count value: 42
}
Ok(())
}
注意:由于 count 是 CounterData 中唯一的字段,尝试读取超过其 8 字节长度的数据会导致 panic,因为结构体中没有其他数据。
运行上面的代码将记录 count 值为 42。

这之所以有效,是因为我们知道结构体的布局。count 字段占据前 8 个字节(字节位置 0-7),所以我们可以直接读取它们并将其转换回 u64。在真实的程序中,我们会改用 CounterData::try_from_slice(&data)?,它会自动从原始字节中反序列化整个结构体。
访问账户元数据(Lamports、Owner 等)
到目前为止,我们一直在讨论账户的 data 字段,但正如我们在之前的教程中学到的,Solana 账户还有其他重要的字段,如 lamports、owner、pubkey 等。
account.try_borrow_data()? 只向我们提供 data 字段(我们的 Borsh 序列化结构体所在的地方),但传递给 process_instruction 函数的 AccountInfo 结构体让我们能够访问 Solana 自动维护的所有其他账户元数据。
我们在下面的代码中展示了如何访问这些字段:
pub fn process_instruction(
_program_id: &Pubkey,
accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
// Get the account's lamports (balance)
let lamports = account.lamports();
msg!("Account lamports: {}", lamports);
// Get the account's owner (program that controls it)
let owner = account.owner;
msg!("Account owner: {}", owner);
// Get the account's public key
let pubkey = account.key;
msg!("Account pubkey: {}", pubkey);
// Check if the account is a signer
let is_signer = account.is_signer;
msg!("Is signer: {}", is_signer);
// Check if the account is writable
let is_writable = account.is_writable;
msg!("Is writable: {}", is_writable);
Ok(())
}
当我们运行上面的代码时,我们会得到类似这样的输出:
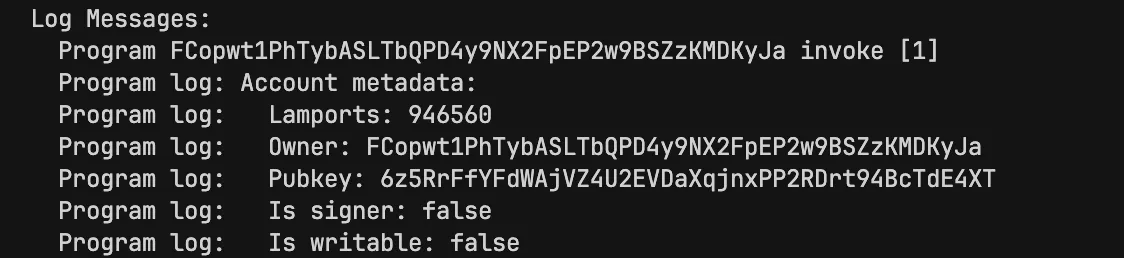
AccountInfo 是在程序中代表 Solana 账户的结构体类型。它包含账户的所有元数据(lamports、owner 等),并提供了访问 data 字段的方法。当我们调用 account.try_borrow_data()? 时,我们仅仅是在访问存储了 Borsh 序列化结构体的 data 字段。
总结
在本教程中,我们介绍了 Borsh 序列化在 Solana 中是如何工作的:
- 序列化将 Rust 结构体转换为字节以进行存储,而反序列化则将字节转换回结构体
- Borsh 是 Solana 的标准序列化格式——它是确定性且紧凑的
#[derive(BorshSerialize, BorshDeserialize)]属性可为你的结构体启用 Borsh 序列化- Borsh 对 Solana 账户的 data 字段进行序列化,而不是其他元数据字段
- 固定长度类型(如
u64、bool)使用一致的字节数 - 可变长度类型(如
String、Vec<T>)使用长度前缀:4 字节长度 + 实际数据 - 结构体字段按照它们声明的顺序依次序列化,没有任何填充
AccountInfo提供了对所有账户元数据的访问,而account.try_borrow_data()?仅向我们提供了序列化后的data字段
在下一篇教程中,我们将把这些知识付诸实践,在原生 Rust Solana 程序中创建存储账户并读取它们的数据。
本文是 Solana 开发 系列教程的一部分。