Comprender cómo Rust se compila a SBF (Solana Bytecode Format) y cómo lo ejecutan los validadores es crucial para construir programas complejos en Solana. Este artículo explica el proceso de compilación de tres etapas, ayudándote a razonar sobre el tamaño del programa, depurar problemas de despliegue y optimizar el rendimiento.
El proceso de compilación de tres etapas para programas de Rust en Solana
Cuando ejecutas cargo build-sbf, tu programa en Rust pasa por tres etapas:
- Rust a LLVM IR: El compilador de Rust traduce tu código a la Representación Intermedia de LLVM (LLVM IR).
- LLVM IR a SBF Bytecode (ensamblador): LLVM compila la representación intermedia a bytecode SBF (el archivo
.soque desplegamos). - SBF a Native Code: Los validadores de Solana tienen un compilador Just-In-Time (JIT) incorporado que compila el bytecode SBF a código máquina nativo en tiempo de ejecución, logrando una velocidad de ejecución casi nativa.
La siguiente imagen resume este proceso.

El proceso de compilación de tres etapas para un programa de Rust en Solana
Ahora considera esta sencilla función de Rust que suma dos enteros u64:
pub fn add(a: u64, b: u64) -> u64 {
a + b
}
Esta función pasará por las tres etapas de compilación antes de ejecutarse en un validador de Solana. La usaremos como un ejemplo continuo para ilustrar cada etapa.
Etapa 1: Rust a LLVM IR
El compilador de Rust (rustc) utiliza LLVM como su backend. LLVM es una infraestructura de compilador que proporciona una representación intermedia (IR) común —un formato independiente de la plataforma para representar código— y aplica optimizaciones como inlining y eliminación de código muerto. rustc traduce el código fuente de Rust a LLVM IR.
Los lenguajes que utilizan LLVM compilan su código a LLVM IR. Luego, LLVM puede traducir ese IR a código máquina para diferentes objetivos como x86, ARM, WebAssembly, BPF y otros. Este diseño permite que un solo frontend del compilador soporte múltiples arquitecturas de hardware sin mantener un backend separado para cada una.
Para ver el LLVM IR real de tu código en Rust, configura la variable de entorno RUSTFLAGS de la siguiente manera:
RUSTFLAGS="-C debuginfo=0 --emit=llvm-ir" cargo build
Esto genera un LLVM IR en la carpeta target/debug/deps/ con un nombre como llvm-<hash>.ll.
Aquí está el LLVM IR generado para la función add en Rust mostrada anteriormente. Lo discutiremos después del bloque de código.
; llvm::add
; Function Attrs: uwtable
define i64 @_ZN4llvm3add17h48743c4abf0c9b05E(i64 %a, i64 %b) unnamed_addr #0 {
start:
%0 = call { i64, i1 } @llvm.uadd.with.overflow.i64(i64 %a, i64 %b)
%_3.0 = extractvalue { i64, i1 } %0, 0
%_3.1 = extractvalue { i64, i1 } %0, 1
br i1 %_3.1, label %panic, label %bb1
bb1: ; preds = %start
ret i64 %_3.0
panic: ; preds = %start
; call core::panicking::panic_const::panic_const_add_overflow
call void @_ZN4core9panicking11panic_const24panic_const_add_overflow17h0235fd41b8202631E(ptr align 8 @alloc_d358b5fc6deae9ccd21c0c027d9d651f) #3
unreachable
}
El bloque de código anterior está reducido para mostrar únicamente el LLVM IR de la función add.
El bloque de código anterior está reducido para mostrar únicamente el LLVM IR de la función add. Así es como esto se corresponde con nuestro código original en Rust:
- La función
@_ZN4llvm3add17h48743c4abf0c9b05Ees el nombre modificado por el compilador (compiler-mangled name) para nuestra funciónadd i64 %aei64 %bson los dos parámetros enteros de 64 bits@llvm.uadd.with.overflow.i64realiza la suma y comprueba si hay desbordamiento- Si ocurre un desbordamiento (
%_3.1es verdadero), la ejecución se desvía apanic; de lo contrario, devuelve el resultado (%_3.0)
LLVM IR utiliza una sintaxis similar a la del ensamblador: define declara una función, i64 especifica enteros de 64 bits, y %a/%b son registros virtuales (almacenamiento temporal para valores).
Etapa 2: LLVM IR a SBF Bytecode
LLVM tiene diferentes backends para distintos objetivos de hardware (x86-64, ARM64, eBPF, etc.). Solana utiliza el backend eBPF pero mantiene un fork de LLVM con modificaciones personalizadas para generar bytecode SBF.
El comando cargo build-sbf descarga las herramientas de plataforma de Solana (que incluyen este fork personalizado de LLVM), y luego utiliza este LLVM personalizado para compilar tu programa a bytecode SBF con una extensión de archivo .so:
cargo build-sbf
# Output: target/deploy/program_name.so
La extensión de archivo .so proviene de las bibliotecas compartidas de Linux (código compilado que varios programas pueden cargar y compartir en tiempo de ejecución). Sin embargo, en el caso de Solana, en lugar de código máquina nativo, este archivo contiene bytecode SBF. El runtime de Solana lee este bytecode como una secuencia de instrucciones de 64 bits (8 bytes), tal como se define en la especificación de codificación de instrucciones de eBPF.
Cuando un programa se ejecuta en una blockchain, se espera que produzca el mismo resultado en todos los validadores de la red. Si los validadores de Solana ejecutaran código máquina nativo (x86-64, ARM64), las diferencias en el hardware o en los sistemas operativos podrían dar lugar a resultados no deterministas, rompiendo el consenso.
SBF resuelve este problema. Es una versión restringida y determinista de eBPF que se ejecuta en una máquina virtual en un entorno aislado (sandbox). Las restricciones incluyen evitar bucles infinitos, verificar las instrucciones antes de la ejecución, bloquear el acceso no autorizado a la memoria y manejar los fallos del programa de forma segura. Cada validador ejecuta el mismo bytecode y obtiene el mismo resultado, sin importar en qué CPU se esté ejecutando.
Como sabemos, SBF se basa en eBPF, y eBPF utiliza una arquitectura basada en registros (que discutiremos más adelante en la serie) y soporta la compilación Just-In-Time. Solana modificó eBPF eliminando instrucciones específicas del kernel, añadiendo llamadas al sistema (syscalls) de la blockchain de Solana (sol_log_, sol_invoke_, sol_create_program_address) e implementando la medición de unidades de cómputo (compute units) para limitar el costo de ejecución.
Etapa 3: SBF a Native Code (Runtime)
Los validadores de Solana no interpretan el bytecode SBF instrucción por instrucción. Utilizan un compilador Just-In-Time (JIT) para traducir el bytecode a código máquina nativo. La compilación JIT ocurre en tiempo de ejecución: el bytecode se compila a instrucciones nativas (específicas para el hardware en el que se ejecuta) inmediatamente antes de su ejecución.
El fork de LLVM que mencionamos en la Etapa 2 compila tu programa en Rust a bytecode SBF. Ese bytecode es luego ejecutado por la máquina virtual sbpf de Solana.
Su compilador JIT traduce cada instrucción SBF en código máquina nativo; por ejemplo, un add64 de SBF (suma de enteros de 64 bits) se convierte en un add en x86-64 o ARM64, dependiendo de la CPU del validador.
Después de que el compilador JIT traduce el bytecode SBF a código máquina nativo, los validadores almacenan el código nativo compilado en la memoria. La próxima vez que se ejecute el mismo programa, la caché de programas del validador devuelve la versión ya compilada en lugar de volver a realizar la compilación JIT.
Debido a este proceso de compilación JIT, el bytecode SBF se ejecuta a velocidad nativa independientemente del hardware del validador. El mismo bytecode produce resultados idénticos en todos los validadores, incluso en diferentes arquitecturas de CPU.
Visualización del SBF Bytecode
Al construir un programa en Solana, puedes usar la bandera --dump para generar el bytecode desensamblado para su inspección.
Supongamos que tenemos este sencillo programa nativo en Rust:
// lib.rs
use solana_program::{
account_info::AccountInfo,
entrypoint,
entrypoint::ProgramResult,
pubkey::Pubkey,
};
entrypoint!(process_instruction);
pub fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
Ok(())
}
Antes de que podamos construir y volcar el bytecode, necesitamos instalar rustfilt, una herramienta que convierte los nombres de las funciones generados por el compilador en nombres legibles. Instálalo con:
cargo install rustfilt
Luego construye y vuelca el bytecode:
cargo build-sbf --dump
Esto genera un archivo .txt en target/deploy/minimal_sbpf-dump.txt. El archivo contiene metadatos del programa (información de la estructura del archivo, diseño de memoria, nombres de funciones) y el bytecode desensamblado. Lo que nos importa es la función entrypoint desensamblada que definimos en nuestro programa en Rust (al menos, alguna parte de ella). Esto nos ayudará a visualizar el formato de instrucción de SBF.
Puedes buscar <entrypoint> en el archivo para encontrarlo y se ve así:
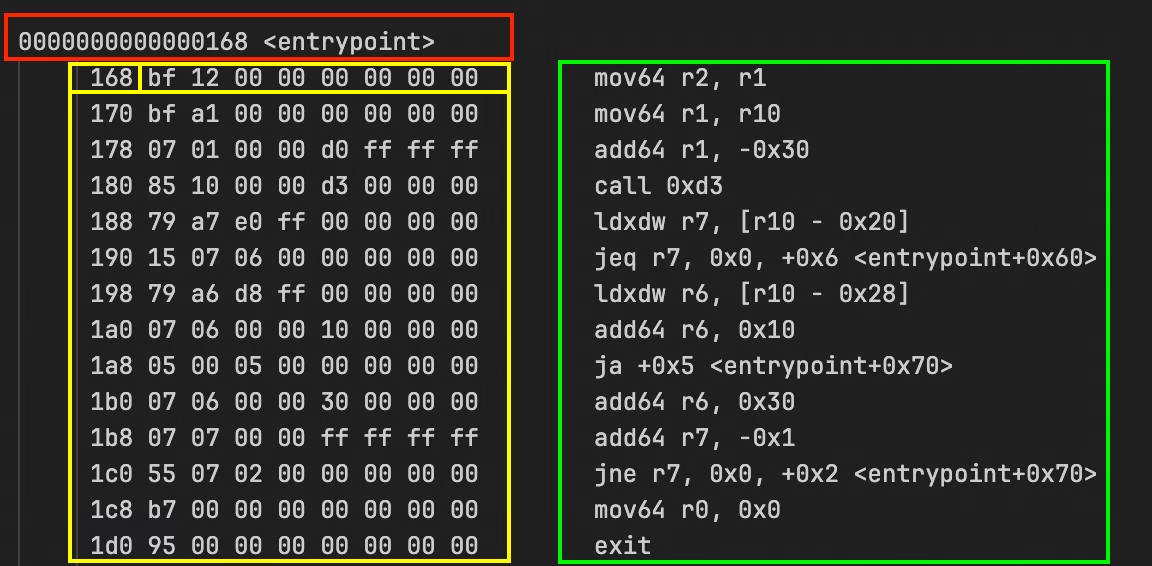
La primera línea en rojo: 0000000000000168 <entrypoint> marca el inicio de la función entrypoint.
El recuadro amarillo es la dirección de la instrucción (en memoria) y el bytecode en crudo. 168 bf 12 00 00 00 00 00 00 significa que la instrucción en la dirección 0x168 tiene el bytecode bf 12 00 00 00 00 00 00. Cada instrucción tiene 8 bytes, por lo que la siguiente está en 0x170, luego en 0x178, y así sucesivamente.
El recuadro verde es la instrucción decodificada. mov64 r2, r1 es lo que significa el bytecode en forma legible: “mueve el valor de 64 bits del registro uno al registro dos”.
Cada instrucción sBPF sigue este formato del conjunto de instrucciones de eBPF:

A partir del diagrama:
opcoderepresenta la instrucción a ejecutardest registerrepresenta el registro de destino (hacia donde va el resultado)src registerrepresenta el registro de origen (de dónde proviene la entrada)offsetrepresenta la dirección de memoria para las operaciones de carga/almacenamientoimmediaterepresenta un valor constante integrado en la instrucción
Tomando la primera instrucción de la captura de pantalla del volcado anterior (resaltada en amarillo) como ejemplo: bf 12 00 00 00 00 00 00 (formato hexadecimal):

Puedes encontrar la lista completa de opcodes en el módulo ebpf de sbpf.
Este artículo es parte de una serie de tutoriales sobre el desarrollo en Solana