了解 Rust 如何编译成 SBF(Solana Bytecode Format)以及验证者如何执行它,对于构建复杂的 Solana 程序至关重要。本文解释了三阶段编译过程,帮助你推理程序大小、调试部署问题并优化性能。
Solana Rust 程序的三阶段编译过程
当你运行 cargo build-sbf 时,你的 Rust 程序会经历三个阶段:
- Rust 到 LLVM IR:Rust 编译器将你的代码转换为 LLVM 中间表示(LLVM IR)
- LLVM IR 到 SBF Bytecode(汇编):LLVM 将中间表示编译为 SBF 字节码(即我们部署的
.so文件) - SBF 到 Native Code:Solana 验证者内置了 即时(JIT)编译器,在运行时将 SBF 字节码编译为原生机器码,从而实现接近原生的执行速度
下图总结了这一过程。

Solana Rust 程序的三阶段编译过程
现在考虑这个将两个 u64 整数相加的简单 Rust 函数:
pub fn add(a: u64, b: u64) -> u64 {
a + b
}
这个函数在 Solana 验证者上执行之前将经历所有三个编译阶段。我们将以此作为贯穿全文的示例来说明每个阶段。
阶段 1:Rust 到 LLVM IR
Rust 编译器(rustc)使用 LLVM 作为其后端。LLVM 是一个编译器基础设施,提供了一种通用的中间表示(IR)——一种用于表示代码的跨平台格式——并应用内联和死代码消除等优化。rustc 将 Rust 源代码转换为 LLVM IR。
使用 LLVM 的语言会将其代码编译为 LLVM IR。然后,LLVM 可以将该 IR 转换为适用于 x86、ARM、WebAssembly、BPF 等不同目标平台的机器码。这种设计允许单一的编译器前端支持多种硬件架构,而无需为每种架构维护单独的后端。
要查看 Rust 代码实际生成的 LLVM IR,请按如下方式设置环境变量 RUSTFLAGS:
RUSTFLAGS="-C debuginfo=0 --emit=llvm-ir" cargo build
这会在 target/debug/deps/ 文件夹中生成一个名为 llvm-<hash>.ll 的 LLVM IR 文件。
以下是为上面展示的 Rust add 函数生成的 LLVM IR。我们将在代码块之后对其进行讨论。
; llvm::add
; Function Attrs: uwtable
define i64 @_ZN4llvm3add17h48743c4abf0c9b05E(i64 %a, i64 %b) unnamed_addr #0 {
start:
%0 = call { i64, i1 } @llvm.uadd.with.overflow.i64(i64 %a, i64 %b)
%_3.0 = extractvalue { i64, i1 } %0, 0
%_3.1 = extractvalue { i64, i1 } %0, 1
br i1 %_3.1, label %panic, label %bb1
bb1: ; preds = %start
ret i64 %_3.0
panic: ; preds = %start
; call core::panicking::panic_const::panic_const_add_overflow
call void @_ZN4core9panicking11panic_const24panic_const_add_overflow17h0235fd41b8202631E(ptr align 8 @alloc_d358b5fc6deae9ccd21c0c027d9d651f) #3
unreachable
}
上面的代码块已被精简,仅显示 add 函数的 LLVM IR。
上面的代码块已被精简,仅显示 add 函数的 LLVM IR。以下是它与我们原始 Rust 代码的映射关系:
- 函数
@_ZN4llvm3add17h48743c4abf0c9b05E是编译器为我们的add函数生成的修饰名称(mangled name) i64 %a和i64 %b是两个 64 位整数参数@llvm.uadd.with.overflow.i64执行加法操作并检查是否溢出- 如果发生溢出(
%_3.1为 true),执行将分支到panic;否则将返回结果(%_3.0)
LLVM IR 使用类似汇编的语法:define 声明一个函数,i64 指定 64 位整数,而 %a/%b 是 虚拟寄存器(用于临时存储值)。
阶段 2:LLVM IR 到 SBF Bytecode
LLVM 针对不同的硬件目标(x86-64、ARM64、eBPF 等)具有不同的后端。Solana 使用 eBPF 后端,但维护了一个经过自定义修改以生成 SBF 字节码的 LLVM 分支。
cargo build-sbf 命令会下载 Solana 的平台工具(其中包含这个自定义的 LLVM 分支),然后使用这个自定义的 LLVM 将你的程序编译为具有 .so 文件扩展名的 SBF 字节码:
cargo build-sbf
# Output: target/deploy/program_name.so
.so 文件扩展名来源于 Linux 共享库(多个程序可以在运行时加载和共享的编译代码)。然而,在 Solana 中,该文件不包含原生机器码,而是包含 SBF 字节码。Solana 运行时按照 eBPF 指令编码 规范中的定义,将此字节码读取为一系列 64 位(8 字节)指令。
当程序在区块链上执行时,它应当在网络中的所有验证者上产生相同的输出。如果 Solana 验证者运行原生机器码(x86-64、ARM64),硬件或操作系统的差异可能会导致非确定性结果,从而破坏共识。
SBF 解决了这个问题。它是一个受限的、确定性的 eBPF 版本,运行在沙盒虚拟机中。 这些限制包括防止无限循环、在执行前验证指令、阻止未经授权的内存访问以及优雅地处理程序崩溃。每个验证者都执行相同的字节码并获得相同的结果,无论它运行在什么 CPU 上。
众所周知,SBF 基于 eBPF,而 eBPF 使用基于寄存器的架构(我们将在本系列的后续部分进行讨论),并支持即时编译(JIT)。Solana 对 eBPF 进行了修改,删除了内核专用的指令,添加了 Solana 区块链的系统调用(sol_log_、sol_invoke_、sol_create_program_address),并实现了计算单元计量以限制执行成本。
阶段 3:SBF 到 Native Code(运行时)
Solana 验证者并不逐条指令地解释 SBF 字节码。他们使用即时(JIT)编译器将字节码转换为原生机器码。JIT 编译发生在运行时——在执行之前,字节码会被立即编译为原生指令(特定于其运行的硬件)。
我们在阶段 2 中提到的 LLVM 分支将你的 Rust 程序编译为 SBF 字节码。随后,该字节码由 Solana 的 sbpf 虚拟机执行。
其 JIT 编译器 将每条 SBF 指令翻译为原生机器码;例如,SBF 的 add64(64 位整数加法)在 x86-64 或 ARM64 上会变成 add,具体取决于验证者的 CPU。
在 JIT 编译器将 SBF 字节码转换为原生机器码后,验证者会将编译后的原生代码存储在内存中。下次执行同一个程序时,验证者的 程序缓存 将返回已编译的版本,而不是重新进行 JIT 编译。
得益于这种 JIT 编译过程,无论验证者的硬件配置如何,SBF 字节码都以原生的速度运行。同样的字节码在所有验证者上(即使跨越不同的 CPU 架构)都能产生完全一致的结果。
查看 SBF 字节码
在构建 Solana 程序时,你可以使用 --dump 标志输出反汇编的字节码以便检查。
假设我们有这个简单的原生 Rust 程序:
// lib.rs
use solana_program::{
account_info::AccountInfo,
entrypoint,
entrypoint::ProgramResult,
pubkey::Pubkey,
};
entrypoint!(process_instruction);
pub fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
Ok(())
}
在我们构建和转储字节码之前,我们需要安装 rustfilt,这是一个将编译器生成的函数名转换为可读名称的工具。安装命令如下:
cargo install rustfilt
然后构建并转储字节码:
cargo build-sbf --dump
这会在 target/deploy/minimal_sbpf-dump.txt 中生成一个 .txt 文件。该文件包含程序元数据(文件结构信息、内存布局、函数名称)和反汇编字节码。我们关心的是在 Rust 程序中定义的反汇编 entrypoint 函数(至少是其中一部分)。这将有助于我们将 SBF 指令格式可视化。
你可以在文件中搜索 <entrypoint> 找到它,它看起来像这样:
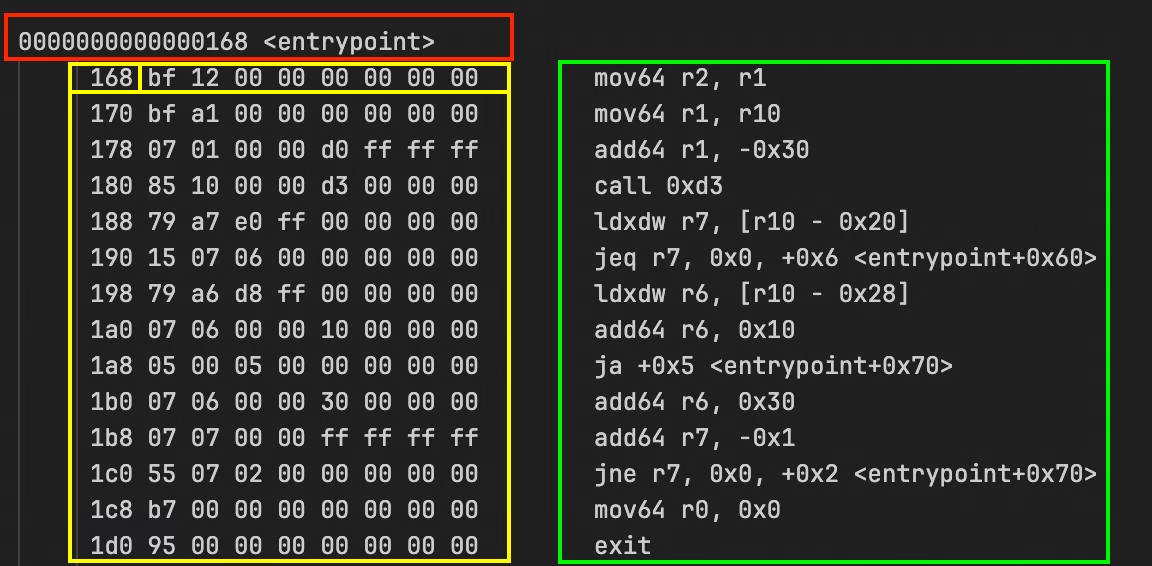
红色的第一行:0000000000000168 <entrypoint> 标志着 entrypoint 函数的开始。
黄色框代表指令地址(在内存中)和原始字节码。168 bf 12 00 00 00 00 00 00 表示地址 0x168 处的指令拥有字节码 bf 12 00 00 00 00 00 00。每条指令长 8 个字节,因此下一条指令位于 0x170,接着是 0x178,依此类推。
绿色框代表解码后的指令。mov64 r2, r1 是字节码的可读形式含义:“将寄存器 1 中的 64 位值移动到寄存器 2 中”。
每条 sBPF 指令都遵循 eBPF 指令集 中的这种格式:

如图所示:
opcode代表要执行的指令dest register代表目标寄存器(存放结果的位置)src register代表源寄存器(输入的来源)offset代表用于加载/存储操作的内存地址immediate代表硬编码在指令中的常量值
以之前转储截图中的第一条指令(黄色高亮部分)为例:bf 12 00 00 00 00 00 00(十六进制格式):

你可以在 sbpf ebpf 模块 中找到完整的操作码列表。
本文是关于 Solana 开发 系列教程的一部分