यह समझना कि Rust कैसे SBF (Solana Bytecode Format) में compile होता है और validators इसे कैसे execute करते हैं, जटिल Solana programs बनाने के लिए महत्वपूर्ण है। यह लेख तीन-चरण (three-stage) compilation प्रक्रिया की व्याख्या करता है, जो आपको program के आकार (size) को समझने, deployment समस्याओं को debug करने और प्रदर्शन (performance) को अनुकूलित (optimize) करने में मदद करता है।
Solana Rust Programs के लिए तीन-चरणीय Compilation प्रक्रिया
जब आप cargo build-sbf रन करते हैं, तो आपका Rust program तीन चरणों से होकर गुजरता है:
- Rust से LLVM IR: Rust compiler आपके कोड को LLVM Intermediate Representation (LLVM IR) में अनुवादित (translate) करता है।
- LLVM IR से SBF Bytecode (assembly): LLVM intermediate representation को SBF bytecode (वह
.soफ़ाइल जिसे हम deploy करते हैं) में compile करता है। - SBF से Native Code: Solana validators में एक अंतर्निहित (built-in) Just-In-Time (JIT) compiler होता है जो runtime पर SBF bytecode को native machine code में compile करता है, जिससे लगभग-native execution गति प्राप्त होती है।
नीचे दी गई छवि इस प्रक्रिया को संक्षेप में प्रस्तुत करती है।

एक Solana Rust program के लिए तीन-चरणीय compilation प्रक्रिया
अब इस सरल Rust function पर विचार करें जो दो u64 integers को जोड़ता है:
pub fn add(a: u64, b: u64) -> u64 {
a + b
}
यह function एक Solana validator पर execute होने से पहले सभी तीन compilation चरणों से गुज़रेगा। हम प्रत्येक चरण को स्पष्ट करने के लिए इसे एक निरंतर उदाहरण (running example) के रूप में उपयोग करेंगे।
चरण 1: Rust से LLVM IR
Rust compiler (rustc) LLVM को अपने backend के रूप में उपयोग करता है। LLVM एक compiler infrastructure है जो एक सामान्य intermediate representation (IR) प्रदान करता है—कोड का प्रतिनिधित्व करने के लिए एक platform-independent format—और inlining और dead code elimination जैसे optimizations लागू करता है। rustc Rust source code को LLVM IR में translate करता है।
जो भाषाएं LLVM का उपयोग करती हैं, वे अपने कोड को LLVM IR में compile करती हैं। फिर LLVM उस IR को x86, ARM, WebAssembly, BPF और अन्य जैसे विभिन्न targets के लिए machine code में translate कर सकता है। यह डिज़ाइन एक सिंगल compiler frontend को प्रत्येक के लिए अलग backend बनाए रखे बिना कई हार्डवेयर आर्किटेक्चर (hardware architectures) का समर्थन (support) करने की अनुमति देता है।
अपने Rust कोड के लिए वास्तविक LLVM IR देखने के लिए, environment variable RUSTFLAGS को इस प्रकार सेट करें:
RUSTFLAGS="-C debuginfo=0 --emit=llvm-ir" cargo build
यह target/debug/deps/ फ़ोल्डर में llvm-<hash>.ll जैसे नाम के साथ एक LLVM IR उत्पन्न करता है।
यहाँ ऊपर दिखाए गए Rust add function के लिए उत्पन्न (generated) LLVM IR दिया गया है। हम कोड ब्लॉक के बाद इस पर चर्चा करेंगे।
; llvm::add
; Function Attrs: uwtable
define i64 @_ZN4llvm3add17h48743c4abf0c9b05E(i64 %a, i64 %b) unnamed_addr #0 {
start:
%0 = call { i64, i1 } @llvm.uadd.with.overflow.i64(i64 %a, i64 %b)
%_3.0 = extractvalue { i64, i1 } %0, 0
%_3.1 = extractvalue { i64, i1 } %0, 1
br i1 %_3.1, label %panic, label %bb1
bb1: ; preds = %start
ret i64 %_3.0
panic: ; preds = %start
; call core::panicking::panic_const::panic_const_add_overflow
call void @_ZN4core9panicking11panic_const24panic_const_add_overflow17h0235fd41b8202631E(ptr align 8 @alloc_d358b5fc6deae9ccd21c0c027d9d651f) #3
unreachable
}
ऊपर दिए गए कोड ब्लॉक को छोटा (stripped down) किया गया है ताकि केवल add function के लिए LLVM IR दिखाया जा सके।
ऊपर दिए गए कोड ब्लॉक को छोटा (stripped down) किया गया है ताकि केवल add function के लिए LLVM IR दिखाया जा सके। यहाँ बताया गया है कि यह हमारे मूल Rust कोड से कैसे मैप होता है:
- Function
@_ZN4llvm3add17h48743c4abf0c9b05Eहमारेaddfunction के लिए compiler-mangled नाम है i64 %aऔरi64 %bदो 64-bit integer parameters हैं@llvm.uadd.with.overflow.i64जोड़ (addition) करता है और overflow की जांच करता है- यदि overflow होता है (
%_3.1true है), तो executionpanicपर चला जाता है; अन्यथा यह परिणाम (%_3.0) लौटाता है
LLVM IR assembly-जैसे सिंटैक्स (syntax) का उपयोग करता है: define एक function घोषित (declare) करता है, i64 64-bit integers निर्दिष्ट करता है, और %a/%b virtual registers (वैल्यू के लिए अस्थायी संग्रहण) हैं।
चरण 2: LLVM IR से SBF Bytecode
LLVM के पास विभिन्न हार्डवेयर targets (x86-64, ARM64, eBPF, आदि) के लिए अलग-अलग backends होते हैं। Solana eBPF backend का उपयोग करता है लेकिन SBF bytecode उत्पन्न करने के लिए कस्टम संशोधनों (custom modifications) के साथ LLVM का एक fork बनाए रखता है।
cargo build-sbf कमांड Solana के platform tools (जिसमें यह कस्टम LLVM fork शामिल है) को डाउनलोड करता है, फिर आपके program को .so फ़ाइल एक्सटेंशन के साथ SBF bytecode में compile करने के लिए इस कस्टम LLVM का उपयोग करता है:
cargo build-sbf
# Output: target/deploy/program_name.so
.so फ़ाइल एक्सटेंशन Linux shared libraries (compiled कोड जिसे runtime पर कई programs लोड और साझा कर सकते हैं) से आता है। हालाँकि, Solana के मामले में, native machine code के बजाय, इस फ़ाइल में SBF bytecode होता है। Solana runtime इस bytecode को 64-bit निर्देशों (8 बाइट्स) के अनुक्रम (sequence) के रूप में पढ़ता है, जैसा कि eBPF instruction encoding विशिष्टता (specification) में परिभाषित किया गया है।
जब कोई program किसी ब्लॉकचेन पर execute किया जाता है, तो उससे नेटवर्क के सभी validators पर समान आउटपुट उत्पन्न करने की उम्मीद की जाती है। यदि Solana validators native machine code (x86-64, ARM64) चलाते, तो हार्डवेयर या ऑपरेटिंग सिस्टम में अंतर nondeterministic परिणामों को जन्म दे सकता था, जिससे consensus (सहमति) टूट सकती थी।
SBF इस समस्या को हल करता है। यह eBPF का एक प्रतिबंधित (restricted), deterministic संस्करण है जो एक sandboxed virtual machine में चलता है। प्रतिबंधों में अनंत लूप (infinite loops) को रोकना, execution से पहले निर्देशों को सत्यापित करना (verifying instructions), अनधिकृत मेमोरी एक्सेस को रोकना और program क्रैश को सुचारू रूप से संभालना शामिल है। हर validator समान bytecode execute करता है और समान परिणाम प्राप्त करता है, चाहे वह किसी भी CPU पर चल रहा हो।
जैसा कि हम जानते हैं, SBF eBPF पर आधारित है, और eBPF एक register-आधारित आर्किटेक्चर (जिसकी चर्चा हम इस सीरीज़ में आगे करेंगे) का उपयोग करता है और Just-In-Time compilation का समर्थन करता है। Solana ने kernel-विशिष्ट (kernel-specific) निर्देशों को हटाकर, Solana ब्लॉकचेन syscalls (sol_log_, sol_invoke_, sol_create_program_address) को जोड़कर, और execution लागत (cost) को सीमित करने के लिए compute unit metering को लागू करके eBPF को संशोधित (modify) किया।
चरण 3: SBF से Native Code (Runtime)
Solana validators SBF bytecode को instruction दर instruction इंटरप्रेट (interpret) नहीं करते हैं। वे bytecode को native machine code में translate करने के लिए एक Just-In-Time (JIT) compiler का उपयोग करते हैं। JIT compilation runtime पर होता है—bytecode execution से ठीक पहले native निर्देशों (जिस हार्डवेयर पर यह चल रहा है, उसके लिए विशिष्ट) में compile हो जाता है।
जिस LLVM fork का हमने चरण 2 में उल्लेख किया था, वह आपके Rust program को SBF bytecode में compile करता है। फिर वह bytecode Solana की sbpf virtual machine द्वारा execute किया जाता है।
इसका JIT compiler प्रत्येक SBF निर्देश को native machine code में translate करता है; उदाहरण के लिए, एक SBF add64 (64-bit integer जोड़) validator के CPU के आधार पर x86-64 या ARM64 पर add बन जाता है।
JIT compiler द्वारा SBF bytecode को native machine code में translate करने के बाद, validators संकलित (compiled) native code को मेमोरी में स्टोर करते हैं। अगली बार जब वही program execute होता है, तो validator का program cache फिर से JIT-compile करने के बजाय पहले से संकलित संस्करण (already-compiled version) लौटाता है।
इस JIT compilation प्रक्रिया के कारण, SBF bytecode validator हार्डवेयर की परवाह किए बिना native गति से चलता है। एक ही bytecode सभी validators पर समान परिणाम उत्पन्न करता है, यहाँ तक कि विभिन्न CPU आर्किटेक्चर (architectures) पर भी।
SBF Bytecode को देखना
एक Solana program को बिल्ड करते समय, आप निरीक्षण (inspection) के लिए disassembled bytecode आउटपुट करने के लिए --dump फ़्लैग का उपयोग कर सकते हैं।
मान लें कि हमारे पास यह सरल native Rust program है:
// lib.rs
use solana_program::{
account_info::AccountInfo,
entrypoint,
entrypoint::ProgramResult,
pubkey::Pubkey,
};
entrypoint!(process_instruction);
pub fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
Ok(())
}
इससे पहले कि हम bytecode को बिल्ड और डंप कर सकें, हमें rustfilt स्थापित (install) करना होगा, जो compiler द्वारा उत्पन्न function नामों को पढ़ने योग्य नामों में परिवर्तित करने वाला एक टूल है। इसे इसके साथ स्थापित करें:
cargo install rustfilt
फिर bytecode को बिल्ड और डंप करें:
cargo build-sbf --dump
यह target/deploy/minimal_sbpf-dump.txt में एक .txt फ़ाइल उत्पन्न करता है। फ़ाइल में program मेटाडेटा (फ़ाइल संरचना की जानकारी, मेमोरी लेआउट, function नाम) और disassembled bytecode शामिल हैं। हमारे लिए जो मायने रखता है वह है disassembled entrypoint function जिसे हमने अपने Rust program में परिभाषित किया है (कम से कम, इसका कुछ हिस्सा)। यह हमें SBF instruction format की कल्पना करने में मदद करेगा।
आप इसे खोजने के लिए फ़ाइल में <entrypoint> खोज (search) सकते हैं और यह इस तरह दिखता है:
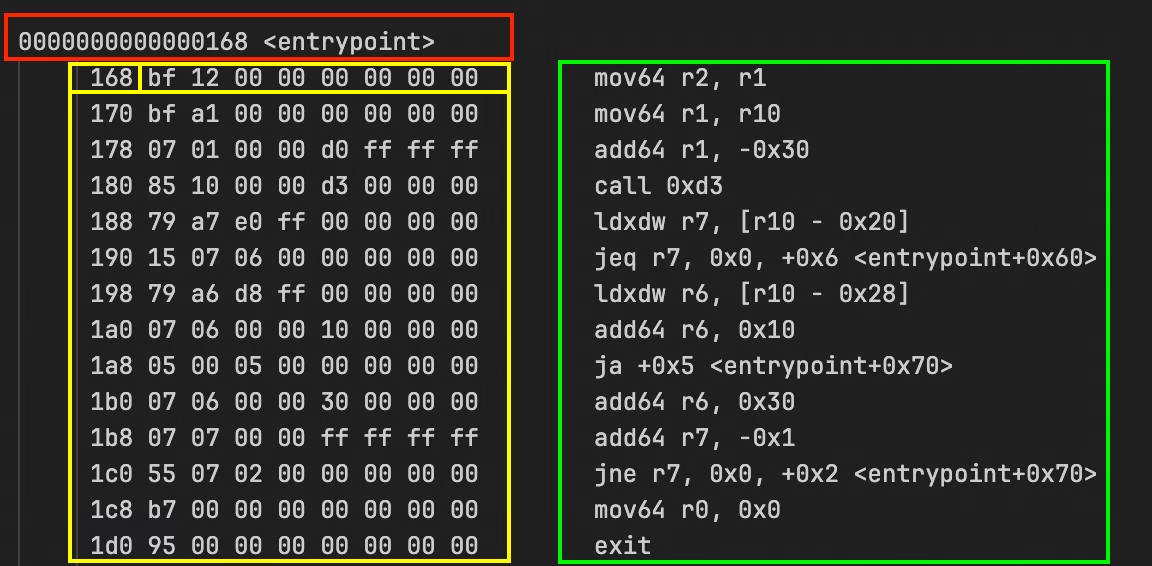
लाल रंग की पहली लाइन: 0000000000000168 <entrypoint> entrypoint function की शुरुआत को दर्शाती है।
पीला बॉक्स (yellow box) instruction एड्रेस (मेमोरी में) और raw bytecode है। 168 bf 12 00 00 00 00 00 00 का अर्थ है कि एड्रेस 0x168 पर मौजूद instruction का bytecode bf 12 00 00 00 00 00 00 है। प्रत्येक instruction 8 बाइट्स का होता है, इसलिए अगला 0x170 पर है, फिर 0x178 पर, और इसी तरह।
हरा बॉक्स (green box) डिकोड किया गया instruction है। mov64 r2, r1 का अर्थ है कि bytecode का पढ़ने योग्य रूप (readable form) क्या है: “रजिस्टर एक से 64-बिट मान (value) को रजिस्टर दो में ले जाएँ (move करें)”।
प्रत्येक sBPF instruction eBPF instruction set से इस प्रारूप (format) का पालन करता है:

आरेख (diagram) से:
opcodeexecute किए जाने वाले instruction का प्रतिनिधित्व करता हैdest registerगंतव्य (destination) रजिस्टर का प्रतिनिधित्व करता है (जहाँ परिणाम जाता है)src registerस्रोत (source) रजिस्टर का प्रतिनिधित्व करता है (जहाँ से इनपुट आता है)offsetलोड/स्टोर (load/store) संचालन (operations) के लिए मेमोरी एड्रेस का प्रतिनिधित्व करता हैimmediateनिर्देश में समाहित (baked into) एक निरंतर मान (constant value) का प्रतिनिधित्व करता है
पहले दिखाए गए डंप स्क्रीनशॉट (पीले रंग में हाईलाइट किया गया) से पहले निर्देश को एक उदाहरण के रूप में लेते हुए: bf 12 00 00 00 00 00 00 (हेक्स/hex प्रारूप):

आप संपूर्ण opcode सूची sbpf ebpf module में पा सकते हैं।
यह लेख Solana development पर एक ट्यूटोरियल सीरीज़ का हिस्सा है