El despacho de funciones en Solana es el proceso de enrutar las instrucciones entrantes hacia la función manejadora adecuada basándose en identificadores específicos codificados en los datos de la instrucción.
En nuestros tutoriales anteriores sobre native Rust en Solana, colocamos toda la lógica del programa dentro de la función process_instruction. Esto funciona para programas simples con una sola instrucción. Sin embargo, cuando un programa soporta múltiples instrucciones, el punto de entrada (entrypoint) se llena de lógica de análisis (parsing), comprobaciones de condiciones y código de manejo. Un enfoque más limpio es mover la lógica a funciones separadas y enrutar cada instrucción al manejador correcto.
A diferencia de Ethereum, donde la EVM enruta las llamadas a la función correcta utilizando selectores integrados, los programas de Solana deben enrutar las instrucciones por sí mismos. Anchor resuelve esto generando discriminadores de 8 bytes y anteponiéndolos a los datos de la instrucción. El programa lee este valor y realiza el despacho al manejador correcto. Explicamos esto en detalle en la siguiente sección.
En este tutorial, demostraremos cómo manejar el despacho de funciones en programas native Rust de Solana.
Cómo Anchor maneja el despacho de funciones
Cuando escribes funciones en Anchor de esta manera:
#[program]
pub mod my_program {
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
// Initialize logic
Ok(())
}
pub fn update_counter(ctx: Context<UpdateCounter>, new_value: u64) -> Result<()> {
// Update logic
Ok(())
}
pub fn close_account(ctx: Context<CloseAccount>) -> Result<()> {
// Close logic
Ok(())
}
}
Anchor genera el código necesario para enrutar las instrucciones a la función apropiada basándose en los datos de la instrucción. Internamente, realiza tres pasos principales:
-
Paso 1 — Anchor antepone un discriminador de 8 bytes a cada instrucción. Este discriminador se crea tomando los primeros 8 bytes del hash SHA-256 de “global:” más el nombre de la función (
sha256("global:" + function_name)). Este identificador único ayuda a enrutar cada instrucción hacia la función manejadora correcta; esto es similar a Ethereum, donde el selector de la función son los primeros 4 bytes del hash Keccak-256 de la firma de la función.let mutdiscriminator = [0u8; 8]; let preimage = format!("global:{}", ix_name); // ix_name = function name let hash = sha2::Sha256::digest(preimage.as_bytes()); discriminator.copy_from_slice(&hash[..8]); -
Paso 2 — Anchor genera un despachador en tiempo de compilación. Divide los datos de la instrucción en la marca de los 8 bytes y utiliza el discriminador para enrutar hacia el manejador adecuado con una declaración match de Rust, justo dentro del procesador de instrucciones.
// Conceptual representation of what Anchor generates pub fn process_instruction( program_id: &Pubkey, accounts: &[AccountInfo], instruction_data: &[u8], ) -> ProgramResult { // Split off the 8-byte discriminator let (discriminator, remaining_data) = instruction_data.split_at(8); // Match against known instruction discriminators match discriminator { // Each instruction's discriminator is computed at compile time INITIALIZE_DISCRIMINATOR => initialize(program_id, accounts, remaining_data), UPDATE_COUNTER_DISCRIMINATOR => update_counter(program_id, accounts, remaining_data), _ => return Err(ProgramError::InvalidInstructionData), } } -
Paso 3 — Anchor deserializa los parámetros de la instrucción. Para las instrucciones con parámetros, Anchor deserializa los datos restantes de la instrucción en los tipos esperados de Rust. Esto significa que tus funciones reciben los parámetros que esperan, en lugar de bytes en crudo (raw bytes).
Con estos tres pasos implementados, nosotros escribimos funciones en Rust y Anchor maneja el enrutamiento de instrucciones y todo el análisis de los datos de la instrucción por nosotros. Pero debido a que estamos usando native Rust, tenemos que hacer estos pasos nosotros mismos.
Implementando el despacho de funciones en programas Native Rust
Construiremos un programa nativo de Solana en Rust con tres funciones: la función process_instruction y dos manejadores de instrucciones. En process_instruction, examinaremos el primer byte de los datos de la instrucción y usaremos una declaración match para realizar el despacho al manejador apropiado. La primera función simplemente registrará (log) un mensaje para demostrar que el mecanismo de enrutamiento identifica y llama correctamente al manejador previsto. La segunda función iterará a través de las cuentas y analizará los bytes de los datos de la instrucción.
Una vez que cubramos cómo funciona el enrutamiento, todos los demás conceptos que hemos tratado en nuestros tutoriales anteriores sobre native Rust en Solana se pueden aplicar, es decir, la creación de cuentas, la serialización con Borsh y la invocación entre programas. Todos funcionan de la misma manera dentro de tus funciones manejadoras.
Podemos implementar el despacho de funciones de múltiples maneras. Aunque no hay una única convención forzada (los programas son libres de elegir su propio enfoque), el enfoque de byte simple y los enums serializados con Borsh son los más comunes en programas native Rust, mientras que Anchor utiliza su enfoque de hashing. A continuación, se presentan los enfoques principales:
- Enfoque de byte simple: Asignamos una constante única para representar cada función en nuestro programa, p. ej.,
const INITIALIZE: u8 = 0yconst UPDATE: u8 = 1. Cuando un cliente llama a nuestro programa, coloca uno de estos valores al inicio de los datos de la instrucción (posición del byte 0). Nuestro programa lee entonces el primer byte y lo compara con sus constantes definidas para determinar a qué función pretendía llamar el cliente, y enruta la ejecución en consecuencia. - Enum serializado con Borsh: Este enfoque utiliza Borsh para la serialización. Definimos un enum en Rust con variantes para cada instrucción, derivamos los traits de serialización de Borsh y permitimos que el cliente envíe el enum serializado. Del lado del programa, deserializamos los datos de la instrucción de vuelta a nuestro enum y aplicamos match a las variantes.
- Hashing al estilo Anchor: Este enfoque refleja cómo funciona Anchor internamente. Podemos crear identificadores únicos tomando los primeros 8 bytes del hash SHA-256 de “global:” más el nombre de cada instrucción. El cliente calcula este hash de la misma manera y lo antepone a los datos de la instrucción, y nuestro programa lo compara mediante match con estas constantes hash precalculadas.
Utilizaremos el enfoque de byte simple para nuestro ejemplo.
Nuestro programa tendrá tres funciones principales:
process_instruction: El procesador de instrucciones que recibe todas las instrucciones y las enruta al manejador adecuado basándose en los datos de la instrucción.say_hello: Una función manejadora simple que registra mensajes de saludo en los logs.inspect_accounts: Esta función recibirá un mensaje de texto del cliente que construiremos, y registrará el mensaje junto con el ID del programa y la información de la cuenta proporcionada por ese cliente.
Configuración del proyecto
Primero configuremos la estructura de nuestro proyecto para demostrar el despacho de funciones:
mkdir solana-dispatch-example
cd solana-dispatch-example
cargo init --lib
Ahora actualiza tu Cargo.toml para incluir las dependencias necesarias:
[package]
name = "solana-dispatch-example"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.2.0"
Abre src/lib.rs y reemplaza su contenido con el código a continuación. Este programa:
- Define constantes para cada tipo de instrucción (
SAY_HELLO= 0 yINSPECT_ACCOUNTS= 1) - Implementa
process_instructiony lo pasa a la macroentrypoint! - Lee el primer byte de los datos de la instrucción para determinar a qué función llamar
- Aplica match sobre el tipo de instrucción y enruta la ejecución a la función manejadora correcta
use solana_program::{
account_info::AccountInfo,
entrypoint,
entrypoint::ProgramResult,
msg,
pubkey::Pubkey,
};
// Define instruction type constants
pub const SAY_HELLO: u8 = 0;
pub const INSPECT_ACCOUNTS: u8 = 1;
entrypoint!(process_instruction);
pub fn process_instruction(
program_id: &Pubkey,
accounts: &[AccountInfo],
instruction_data: &[u8],
) -> ProgramResult {
// Read first byte to determine which function to call
match instruction_data[0] {
SAY_HELLO => say_hello(),
INSPECT_ACCOUNTS => inspect_accounts(program_id, accounts, &instruction_data[1..]),
_ => {
msg!("Unknown instruction: {}", instruction_data[0]);
}
}
Ok(())
}
La declaración match es donde ocurre el despacho real. Comparamos el primer byte de los datos de la instrucción con nuestras constantes definidas (SAY_HELLO y INSPECT_ACCOUNTS). Dado que nuestras constantes son valores de un solo byte, solo necesitamos verificar instruction_data[0]. Para la función INSPECT_ACCOUNTS, pasamos los bytes restantes (&instruction_data[1..]) a la función manejadora.
Ahora añade la función say_hello. Simplemente registramos algunos mensajes:
fn say_hello() {
msg!("Hello from our first function!");
}
Finalmente, añadamos la función inspect_accounts. Esta función recibirá un mensaje de texto del cliente (enviado como datos de la instrucción), lo deserializará y lo registrará en el log junto con el ID del programa y la información de la cuenta pasada:
fn inspect_accounts(program_id: &Pubkey, accounts: &[AccountInfo], data: &[u8]) {
msg!("Hello from our second function!");
msg!("Program ID: {}", program_id);
msg!("Number of accounts: {}", accounts.len());
msg!("Instruction data length: {}", data.len());
// Show account details
for (i, account) in accounts.iter().enumerate() {
msg!("Account {}: {}", i, account.key);
msg!(" Lamports: {}", account.lamports());
msg!(" Owner: {}", account.owner);
}
}
Nota que la función inspect_accounts utiliza los mismos parámetros que la función process_instruction. Esto no es un requisito, pero es un patrón común.
Ahora compilamos y desplegamos el programa:
# Build the program
cargo build-sbf
# Start a local validator (in a separate terminal)
solana-test-validator
# Monitor logs (in another terminal)
solana logs
# Deploy the program
solana program deploy target/deploy/solana_dispatch_example.so
Deberías obtener una salida similar a esta:

Copia el ID de tu programa de la salida, lo necesitarás para el cliente.
Probando nuestro programa
Hemos compilado y desplegado nuestro programa con éxito. Ahora, vamos a crear un cliente en TypeScript para probar el despacho de funciones. Este cliente llamará a ambas funciones en nuestro programa.
Primero, configura el entorno del cliente en el directorio de nuestro proyecto:
mkdir client && cd client
npm init -y
npm install @solana/web3.js typescript ts-node @types/node
Actualiza client/package.json para añadir un script de prueba de modo que podamos ejecutar nuestro cliente con npm run test:
{
"scripts": {
"test": "ts-node client.ts"
}
}
Crea un archivo client/tsconfig.json con la siguiente configuración del compilador de TypeScript, la cual permite que nuestro código TypeScript del cliente se compile y se ejecute con ts-node.
{
"compilerOptions": {
"target": "ES2020",
"module": "commonjs",
"moduleResolution": "node",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"types": ["node"]
},
"include": ["*.ts"]
}
Finalmente, crea un archivo client/client.ts para el código de nuestro cliente y añade el código a continuación. En este código nosotros:
- Definimos las mismas constantes de instrucción que coinciden con las funciones de nuestro programa (
SAY_HELLO= 0,INSPECT_ACCOUNTS= 1) - Configuramos la conexión con el test validator local de Solana
- Creamos y fondeamos una cuenta pagadora (utilizada como firmante de la transacción para pagar las tarifas de transacción)
- Llamamos a la función
say_hello(envía solo el byte discriminador 0, sin pasar cuentas) - Llamamos a la función
inspect_accounts(envía el discriminador + el mensaje de texto de saludo, pasa al pagador y al ID del programa como cuentas para inspección)
import {
Connection,
Keypair,
LAMPORTS_PER_SOL,
PublicKey,
Transaction,
TransactionInstruction,
sendAndConfirmTransaction,
} from '@solana/web3.js';
// Constants that match our program
const SAY_HELLO = 0;
const INSPECT_ACCOUNTS = 1;
// Replace with your actual program ID after deployment
const PROGRAM_ID = new PublicKey('YOUR_PROGRAM_ID_HERE');
const connection = new Connection('http://localhost:8899', 'confirmed');
async function testFunctionDispatching() {
console.log('Testing Function Dispatching');
// Create a funded payer account
const payer = Keypair.generate();
console.log('Funding payer account...');
await connection.requestAirdrop(payer.publicKey, LAMPORTS_PER_SOL);
// Wait for airdrop confirmation
await new Promise((resolve) => setTimeout(resolve, 2000));
console.log(`Payer: ${payer.publicKey.toString()}`);
// Test the say_hello function
console.log('1. Testing say_hello function:');
const sayHelloIx = new TransactionInstruction({
keys: [],
programId: PROGRAM_ID,
data: Buffer.from([SAY_HELLO]),
});
await sendAndConfirmTransaction(
connection,
new Transaction().add(sayHelloIx),
[payer]
);
console.log('First function called successfully');
// Test the inspect_accounts function
console.log('2. Testing inspect_accounts function:');
// Create message to send to the program
const message = "Hello from TypeScript client!";
const messageBytes = Buffer.from(message, 'utf-8');
const instructionData = Buffer.concat([
Buffer.from([INSPECT_ACCOUNTS]), // Discriminator byte
messageBytes // Message payload
]);
const inspectAccountsIx = new TransactionInstruction({
keys: [
{ pubkey: payer.publicKey, isSigner: false, isWritable: false },
{ pubkey: PROGRAM_ID, isSigner: false, isWritable: false },
],
programId: PROGRAM_ID,
data: instructionData,
});
await sendAndConfirmTransaction(
connection,
new Transaction().add(inspectAccountsIx),
[payer]
);
console.log('Second function called successfully');
console.log('Check the logs to see detailed function output!');
}
testFunctionDispatching().catch(console.error);
Asegúrate de que el test validator y los logs sigan ejecutándose antes de que ejecutemos la prueba.
Ahora ejecuta la prueba:
cd client
npm run test
¡Se ejecuta exitosamente!
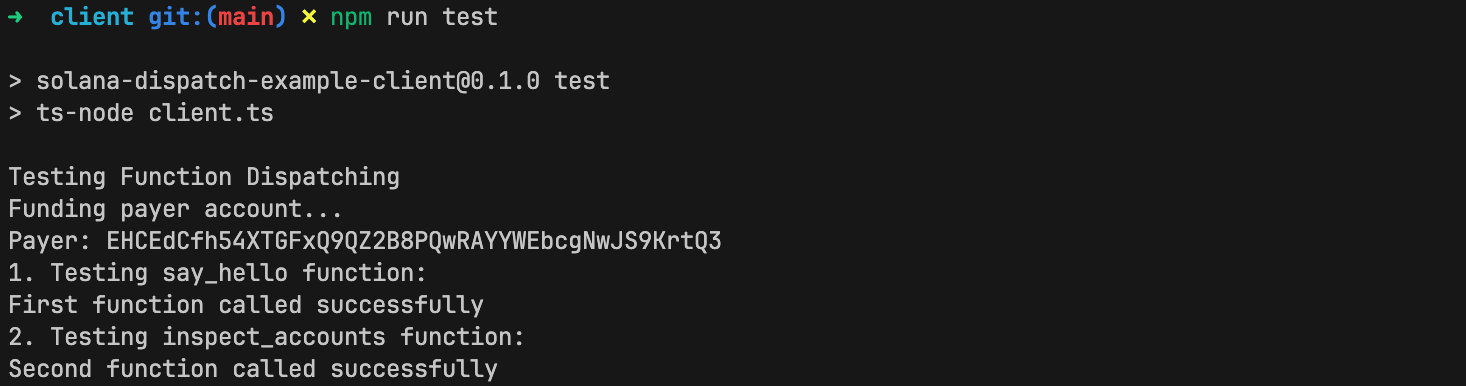
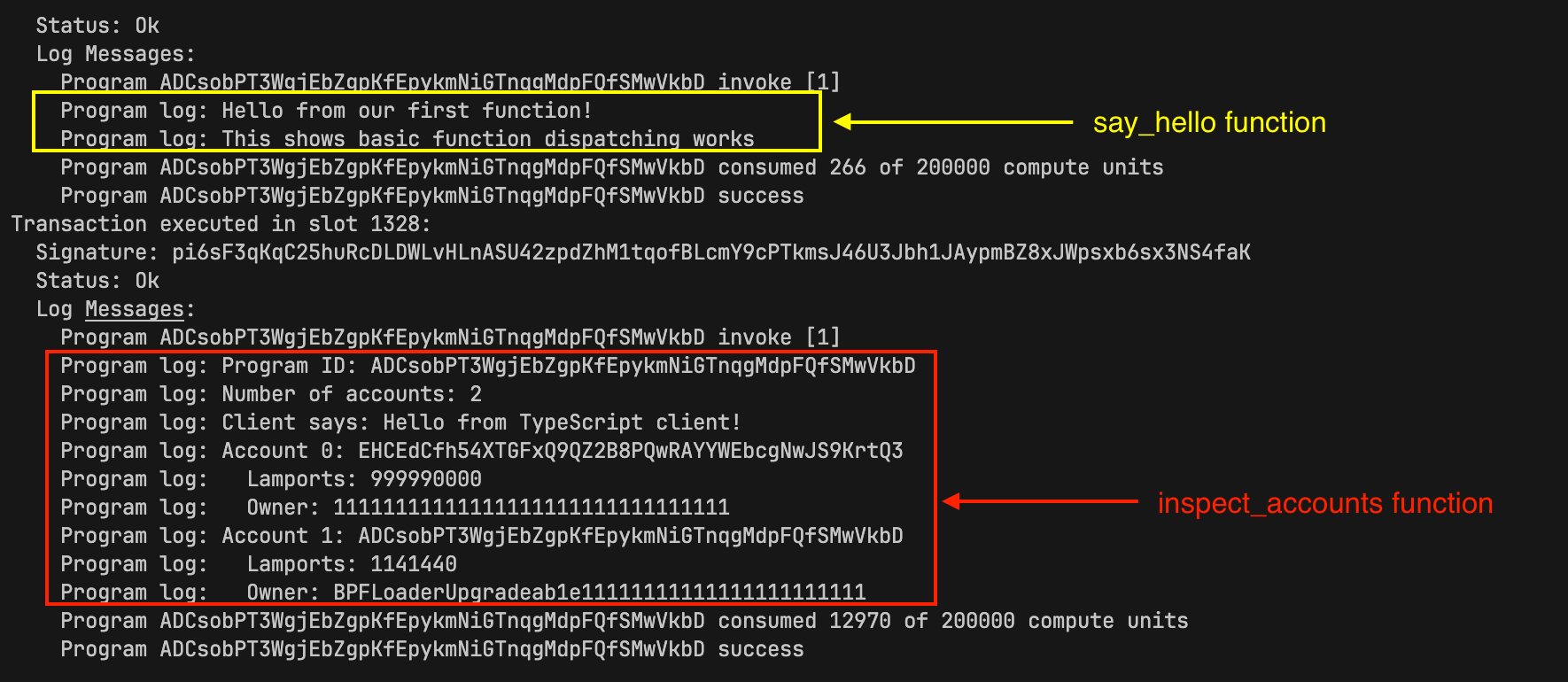
Observando los logs, podemos ver que ambas funciones de nuestro programa se ejecutaron.
Este artículo es parte de una serie de tutoriales sobre desarrollo en Solana.