Solidity depende de keccak-256 como su función hash principal para derivar identificadores deterministas a partir de datos arbitrarios, como calcular selectores de funciones o calcular ranuras de almacenamiento para mapeos, pero Cairo proporciona funciones hash separadas para distintos contextos.
Este artículo cubre tres funciones hash en Starknet/Cairo: Pedersen, Poseidon y Keccak-256. Explicaremos cómo y cuándo usar cada una de ellas en tus contratos inteligentes.
¿Por qué Cairo usa tres funciones hash?
Los sistemas de pruebas ZK como Starknet trabajan sobre campos finitos, donde cada operación se expresa como una restricción. Una restricción es una ecuación aritmética que codifica las reglas de computación que deben cumplirse para producir una prueba válida. Cuantas más restricciones requiera una operación, más costosa será de probar.
Keccak-256 es particularmente costoso en este sentido porque está basado en operaciones a nivel de bits como XOR, AND y rotaciones de bits. Esas operaciones no se mapean directamente a la aritmética de campos y deben ser emuladas utilizando muchas restricciones, lo que hace que Keccak-256 sea significativamente más costoso de probar que las operaciones que son nativamente compatibles con los campos.
Por lo tanto, Cairo proporciona tres funciones hash, cada una para un contexto diferente:
-
Hash Keccak-256
Esta función hash se incluye en Cairo para la compatibilidad con Ethereum, por ejemplo, para calcular selectores de funciones, replicar diseños de almacenamiento y verificar firmas de Ethereum.
Aunque no está optimizada para las pruebas STARK debido a que tiene demasiadas restricciones y, por lo tanto, es costosa para un uso frecuente, es necesaria para la interoperabilidad entre cadenas, y para derivar la dirección base de las variables de almacenamiento en Cairo.
-
Hash Pedersen
Una función hash basada en curva elíptica definida sobre el campo nativo de Starknet (
felt252). Fue la primera función hash utilizada en Starknet y todavía se usa para calcular direcciones de almacenamiento (por ejemplo, el tipoMapdepende de Pedersen para hacer el hash de las claves de almacenamiento). Como resultado, a menudo se requiere Pedersen para la compatibilidad con contratos existentes, compromisos de estado o árboles de Merkle que ya dependen de él.A diferencia de Keccak, que depende de operaciones a nivel de bits que requieren muchas restricciones en las pruebas STARK, Pedersen utiliza sumas de puntos y multiplicaciones escalares en una curva Stark, lo que lo hace más barato de probar dentro de Cairo. Pedersen produce salidas de
felt252. -
Hash Poseidon
Opera directamente sobre el campo primo utilizado por Starknet, evitando por completo la aritmética de curva elíptica. Esto resulta en muchas menos restricciones, haciéndolo más barato y rápido que Pedersen y Keccak, y es la opción recomendada para hashing en general, árboles de Merkle y compromisos dentro de Cairo. Produce salidas de
felt252.
Nota: Si necesitas interactuar con contratos heredados, usa “Pedersen”. Si tienes la libertad de elegir la mejor opción por eficiencia, usa “Poseidon”. Si necesitas compatibilidad con Ethereum, usa “Keccak”.
Cómo usar las funciones hash en Cairo
Ahora que entendemos qué son estas funciones hash y cuál es su propósito, veamos cómo usarlas en la práctica. Cairo proporciona estas funciones hash en su biblioteca central. Para funciones como Pedersen y Poseidon, el tipo de su preimagen (el valor de entrada a ser procesado por la función hash) debe implementar un trait llamado Hash.
El Trait Hash
Este trait marca un tipo como hashable. Está implementado para los tipos primitivos de Cairo (felt252, bool, u8, etc.) que pueden ser representados en su totalidad como valores felt252. Para tipos complejos como structs y enums, derivar Hash (#[derive(Hash)]) los hace hashables utilizando cualquier función hash soportada (Poseidon o Pedersen), siempre que cada campo o variante sea hashable en sí mismo.
Los tipos de colección, por otro lado, no derivan ni pueden derivar el trait Hash; por lo tanto, no son hashables. Los siguientes ejemplos ilustran qué tipos pueden y no pueden derivar Hash (veremos por qué después del bloque de código):
// ✅ All fields are hashable
// Primitive types can be hashed
#[derive(Hash)]
struct A {
f1: felt252,
f2: u256, // u256 is actually a struct { low: u128, high: u128 }
// but derives Hash by default since both fields are hashable
}
// ❌ Cannot derive Hash: STORAGE collections
// Vectors and Maps in storage cannot be hashed because they don't implement `Hash`.
struct B {
f1: Vec<felt252>,
f2: Map<felt252, u128>,
}
// ❌ Cannot derive Hash: MEMORY collections
// Arrays and Dictionaries in memory cannot be hashed because they don't implement `Hash`.
struct C {
f1: Array<felt252>,
f2: Felt252Dict<u128>,
}
El struct A puede derivar Hash porque ambos campos son hashables. Aunque felt252 es claramente un tipo primitivo, u256 es en realidad un struct { low: u128, high: u128 }. Sin embargo, debido a que u256 en sí mismo deriva Hash (ambos campos u128 son hashables), se comporta como un tipo primitivo para fines de hashing. Los otros structs no pueden derivar Hash porque:
Las colecciones en memoria como Array y Felt252Dict no implementan Hash por diseño, por lo que los structs que las contienen no pueden usar derive(Hash) ya que requiere que todos los campos sean hashables.
Tipos como Map y Vec son específicamente para almacenamiento, lo que significa que sus datos residen en el almacenamiento persistente del contrato en lugar de en la memoria de ejecución de Cairo. Dado que el trait Hash requiere valores en memoria, estos tipos no pueden implementarlo.
Para aplicar funciones hash a valores en Cairo, necesitas dos componentes: el trait Hash (que marca los tipos como hashables) y un estado del hasher (que realiza la operación de hashing real).
El Estado del Hasher
El estado del hasher procesa progresivamente los valores y luego los finaliza para producir un digest (la salida hash final). Este diseño hace posible aplicar hash a un número arbitrario de entradas.
Conceptualmente, piensa en aplicar un hash a una lista de valores de esta manera:
hashFunc(x1, x2, x3, …, xn)
En lugar de calcular esto en un solo paso, el hasher funciona de manera incremental:
-
Inicializar el estado del hasher
El estado comienza con un valor constante predefinido que está codificado de forma rígida en la especificación de la función hash.
-
Aplicar hash a la primera entrada
state₁ = h(state₀, x1) -
Aplicar hash a la siguiente entrada
state₂ = h(state₁, x2) -
Continuar aplicando hash a las entradas
Este proceso se repite para cada entrada hasta que todos los valores han sido procesados:
stateₙ = h(stateₙ₋₁, xn) -
Finalizar el estado
El estado final es el digest:
digest = finalize(stateₙ)
Cairo expone dos traits para trabajar con el estado del hasher:
-
HashStateTrait: Este trait está diseñado para aplicar hash a los elementos de campo nativos de Cairo (
felt252).Proporciona dos métodos principales:
.update: actualiza el estado del hash únicamente con un valor de tipofelt252..finalize: finaliza el estado y devuelve el digest del hash como unfelt252.

-
HashStateExTrait: Este trait “extiende” a HashStateTrait.
Proporciona un método:
.update_with: actualiza el estado del hash con un valor de “cualquier tipo” que implemente el traitHash.

El siguiente paso es ver cómo el trait Hash y el estado del hasher se unen en la práctica. Demostraremos cómo usarlos para aplicar hash a valores con Pedersen y Poseidon.
Pedersen y Poseidon
Tanto Pedersen como Poseidon exponen el mismo flujo de trabajo de hashing en Cairo:
- Inicializar un estado hash
- Actualizarlo con uno o más valores
- Finalizarlo para producir un digest de tipo
felt252
Esto hace que parezcan casi idénticos de usar, con una diferencia clave: Pedersen requiere un valor “base”.
Aquí hay un ejemplo de cómo aplicaremos hash a dos campos usando Poseidon:
PoseidonTrait::new()
.update(a)
.update(b)
.finalize()
Usando Pedersen:
PedersenTrait::new(<*base_value*>) // base
.update(a)
.update(b)
.finalize()
Desde la perspectiva de uso, la única diferencia visible entre los dos es el argumento extra pasado a PedersenTrait::new, llamado base.
Qué es realmente la “base” de Pedersen
La base de Pedersen es simplemente un valor inicial de tipo felt252.
Pedersen es una función hash de 2 entradas (siempre procesa dos valores felt252), lo que significa que no hay una operación nativa de “hash a un solo valor”. Para aplicar hash a un único valor, la base se suministra como la primera entrada y el valor real a aplicar el hash (la preimagen) como la segunda entrada.
Conceptualmente:
final_hash = pedersen(base, a)
Al aplicar hash a múltiples valores, la salida del primer hash se convierte en el siguiente estado y se encadena hacia adelante. Por ejemplo, aplicar hash a tres valores a, b y c con una base se ve así:
initial_state = pedersen(base, a)
state1 = pedersen(initial_state, b)
final_hash = pedersen(state1, c)
Nota cómo el estado previo se convierte en la primera entrada en la siguiente operación hash, esto es exactamente lo que lo convierte en una cadena.
La base también puede ser usada como separador de dominio. El uso de diferentes valores base coloca los hashes en dominios lógicos diferentes, incluso si se procesan los mismos valores en el mismo orden. Por ejemplo, imagina que tu contrato calcula el hash de un par (user, amount) tanto para un reclamo de airdrop como para una aprobación de transferencia. Sin separación de dominio, ambas operaciones producirían el mismo hash para las mismas entradas. Al usar un valor base diferente para cada operación, los dos hashes se colocan en dominios lógicos diferentes y siempre producirán salidas diferentes incluso cuando se les den entradas idénticas:
// Base 0: airdrop claim domain
let claim_hash = PedersenTrait::new(0)
.update(user)
.update(amount)
.finalize();
// Base 1: transfer approval domain
let approval_hash = PedersenTrait::new(1)
.update(user)
.update(amount)
.finalize();
// claim_hash != approval_hash, even though inputs are identical
Poseidon: La Base Ya Está Incorporada
Poseidon, por otro lado, no necesita un valor base explícito porque ya tiene un estado fijo interno. Cuando se llama a PoseidonTrait::new(), comienza desde ese estado predefinido.
Así que conceptualmente, aplicar hash a un único valor en Poseidon se ve así:
initial_state = PREDEFINED_STATE
hash = poseidon(initial_state, a)
Con dos entradas a y b:
initial_state = PREDEFINED_STATE
state1 = poseidon(initial_state, a)
hash = poseidon(state1, b)
Veamos algunos ejemplos de cómo usar Poseidon y Pedersen en un contrato.
Ejemplo 1: Aplicar Hash a Dos Elementos de Campo Con .update
El ejemplo de código a continuación demuestra cómo aplicar hash a dos valores felt252 utilizando Poseidon:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_poseidon(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_felts_poseidon(self: @ContractState, a: felt252, b: felt252) {
let digest = PoseidonTrait::new() // initialize a hash state
.update(a) // takes first felt252
.update(b) // takes second felt252
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
La misma idea para Pedersen; la única diferencia es que pasas una base al crear el estado. 0 es una elección común y se utilizará a lo largo de este artículo:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_pedersen(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_felts_pedersen(self: @ContractState, a: felt252, b: felt252) {
let digest = PedersenTrait::new(0) // 0 as the base for the running hash
.update(a)
.update(b)
.finalize();
println!("Digest: {:?}", digest);
}
}
}
Ejemplo 2: Aplicar Hash con .update_with
Hasta ahora, solo hemos aplicado hash a valores felt252 usando .update. Pero en la práctica, a menudo querremos procesar valores de otros tipos.
Para eso sirve .update_with. Proviene de HashStateExTrait y se usa para aplicar hash a cualquier tipo que implemente (o derive) el trait Hash.
Aplicar Hash a un ContractAddress usando Poseidon
En el código a continuación, aplicamos hash a dos valores ContractAddress, a y b. Dado que ContractAddress implementa el trait Hash, podemos pasarlos directamente al estado del hasher utilizando .update_with().
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_poseidon(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_addresses_poseidon(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PoseidonTrait::new() // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Aplicar Hash a un ContractAddress usando Pedersen
Este contrato a continuación procesa dos direcciones utilizando la función hash Pedersen:
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_pedersen(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_addresses_pedersen(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PedersenTrait::new(0) // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Aplicar Hash a un struct usando Poseidon
En el código a continuación, dado que MyStruct se usa como un parámetro en la interfaz, lo definimos fuera del módulo del contrato para que tanto la interfaz como la implementación del contrato puedan acceder a él.
Cualquier struct que aparezca en una #[starknet::interface] debe:
- Estar definido fuera del módulo del contrato
- Derivar
Serdepara que pueda ser serializado en una secuencia defelt252s, y deserializado de vuelta desde ellos - Derivar
Droppara que el valor pueda ser descartado de manera segura cuando salga del alcance (scope)
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_poseidon(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::poseidon::PoseidonTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_poseidon(self: @ContractState, my_struct: MyStruct) {
let digest = PoseidonTrait::new().update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
Aplicar Hash a un struct usando Pedersen
Esto funciona igual con Pedersen, simplemente reemplaza la importación con la función hash de Pedersen y el estado con PedersenTrait::new(0) y mantén el resto sin cambios:
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::pedersen::PedersenTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, my_struct: MyStruct) {
let digest = PedersenTrait::new(0) // *** REPLACEMENT HERE *** //
.update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
Si un struct solo se usa internamente dentro del contrato y no se expone a través de la interfaz, no necesita derivar Serde.
A continuación hay un ejemplo de un struct hashable definido y utilizado dentro de un contrato:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(
self: @TContractState,
value1: u256,
value2: felt252
);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{HashStateExTrait, HashStateTrait};
use core::pedersen::PedersenTrait;
// *** DEFINE STRUCT INSIDE THE CONTRACT *** //
#[derive(Hash, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, value1: u256, value2: felt252) {
// *** INITIALIZE THE STRUCT *** //
let my_struct = MyStruct { a: value1, b: value2 };
let digest = PedersenTrait::new(0).update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
Ejemplo 3: Aplicar Hash a Arrays
No podemos aplicar hash directamente a un array como hicimos con otros tipos, porque un array en sí mismo no implementa el trait Hash. Para procesar un array debes iterar a través de cada elemento, actualizar el estado del hash sobre la marcha y luego llamar a .finalize() al final.
Aplicar Hash a un Array<felt252> usando Poseidon:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::poseidon::PoseidonTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_poseidon(self: @ContractState, values: Array<felt252>) {
let mut state = PoseidonTrait::new(); // The hash state
let mut i = 0;
let len = values.len();
// The loop
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// Finalize the state
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
Cairo tiene un ayudante integrado para Poseidon que maneja el bucle internamente y gestiona las actualizaciones de estado automáticamente: poseidon_hash_span.
Usando el Ayudante Integrado de Poseidon para Aplicar Hash a un Array de felt252
La función poseidon_hash_span toma un Span<felt252> como entrada, itera a través de cada elemento para construir el estado del hash, luego lo finaliza y devuelve un único digest de felt252.
A continuación se muestra un ejemplo. A diferencia del hashing manual con Poseidon, donde necesitamos importar PoseidonTrait y HashStateTrait, poseidon_hash_span es una función independiente que maneja todo de forma interna. Solo necesitamos importarla y usarla:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_builtin_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `poseidon_hash_span`
use core::poseidon::poseidon_hash_span;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_builtin_poseidon(self: @ContractState, values: Array<felt252>) {
// Convert Array<felt252> to Span<felt252>
let span = values.span();
// USE `poseidon_hash_span`
let digest = poseidon_hash_span(span);
println!("Digest: {:?}", digest);
}
}
}
Dado que la función poseidon_hash_span toma un Span<felt252> como entrada, primero convertimos nuestro array a span usando .span(), y luego lo pasamos a la función integrada, que devuelve un único digest de felt252.
Si pasamos el mismo array a ambas funciones hash_array_manual_poseidon y hash_array_builtin_poseidon, producirán hashes Poseidon idénticos, porque poseidon_hash_span simplemente ejecuta el bucle manual internamente.
Aplicar Hash a un Array<felt252> usando Pedersen:
Los pasos para aplicar hash a un array de felts con Pedersen son similares a los de Poseidon: iteras manualmente a través del array y procesas cada elemento de forma secuencial. Sin embargo, hay una convención en Starknet al aplicar hash a arrays con Pedersen: la longitud del array debe incluirse como el elemento final. Este patrón se sigue de manera consistente en todo el ecosistema de Starknet, incluyendo la implementación del protocolo y bibliotecas estándar como starknet.js.
La función hash_array_manual_pedersen a continuación muestra este patrón en acción. Después de procesar todos los elementos del array, aplicamos un hash a la longitud del array como el elemento final antes de finalizar el estado del hash:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_pedersen(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::pedersen::PedersenTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_pedersen(self: @ContractState, values: Array<felt252>) {
let mut state = PedersenTrait::new(0);
let mut i = 0;
let len = values.len();
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// FOCUS HERE: Include the array length
state = state.update(len.into());
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
Puntos clave:
- Usa el bucle manual cuando se necesite lógica personalizada (p. ej., mezclar otros tipos de datos o actualizaciones condicionales).
- Usa
poseidon_hash_spanpara calcular el hash Poseidon de un array defelt252. Es más limpio y requiere menos código.- El patrón estándar para aplicar hash a arrays con Pedersen es incluir la longitud del array como el elemento final antes de finalizar el estado del hash.
Keccak256
El módulo core::keccak de Cairo proporciona cuatro funciones:
compute_keccak_byte_array: Aplica hash a unByteArray.keccak_u256s_be_inputs: Aplica hash a un array de valoresu256codificados en formato big-endian.keccak_u256s_le_inputs: Aplica hash a un array de valoresu256codificados en formato little-endian.cairo_keccak: Aplica hash a una secuencia de bytes con padding personalizado (el equivalente en Solidity akeccak256(abi.encodePacked(val))).
Todas estas devuelven un u256 que representa el mismo digest de 32 bytes producido por el keccak256 de Solidity. La diferencia está en cómo se representa el valor: Solidity devuelve el digest como bytes32 en formato big-endian, mientras que Cairo lo devuelve como un u256 little-endian.
Por ejemplo, supongamos que el hash keccak de un valor en Solidity produjo 0x1234...5678. El keccak de Cairo representaría ese mismo digest como un u256 little-endian, por lo que su orden de bytes estaría invertido: 0x7856...3412. Veremos cómo obtener resultados coincidentes entre el keccak de Cairo y Solidity en la última sección.
Funciones Keccak de Cairo Con Sus Equivalentes en Solidity
-
compute_keccak_byte_array→ Aplica hash a unByteArray.Contrato en Solidity:
contract Example { function hashHello() external pure returns (bytes32) { return keccak256(abi.encodePacked("Hello RareSkills")); } }Equivalente en Cairo:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash_hello(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::compute_keccak_byte_array; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash_hello(self: @ContractState) { // Perform the hash let digest = compute_keccak_byte_array(@"Hello RareSkills"); println!("Digest: {:?}", digest); } } } -
keccak_u256s_be_inputs→ Aplica hash a un array de valoresu256en orden big-endian, coincidiendo con la codificación predeterminada de Solidity.Contrato en Solidity:
contract Example { function hash() external pure returns (bytes32) { return keccak256(abi.encode(1,2)); } }Equivalente en Cairo:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_be_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_be_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
keccak_u256s_le_inputs→ Aplica hash a un array de valoresu256en orden little-endian. Solidity puede replicar esto convirtiendo manualmente las entradas a little-endian antes de aplicar el hash.Contrato en Solidity:
contract Example { function hash() external pure returns (bytes32) { // Convert 1_u256 and 2_u256 to little endian uint256 one_le = 0x0100000000000000000000000000000000000000000000000000000000000000; uint256 two_le = 0x0200000000000000000000000000000000000000000000000000000000000000; return keccak256(abi.encode(one_le,two_le)); } }Equivalente en Cairo:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_le_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_le_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
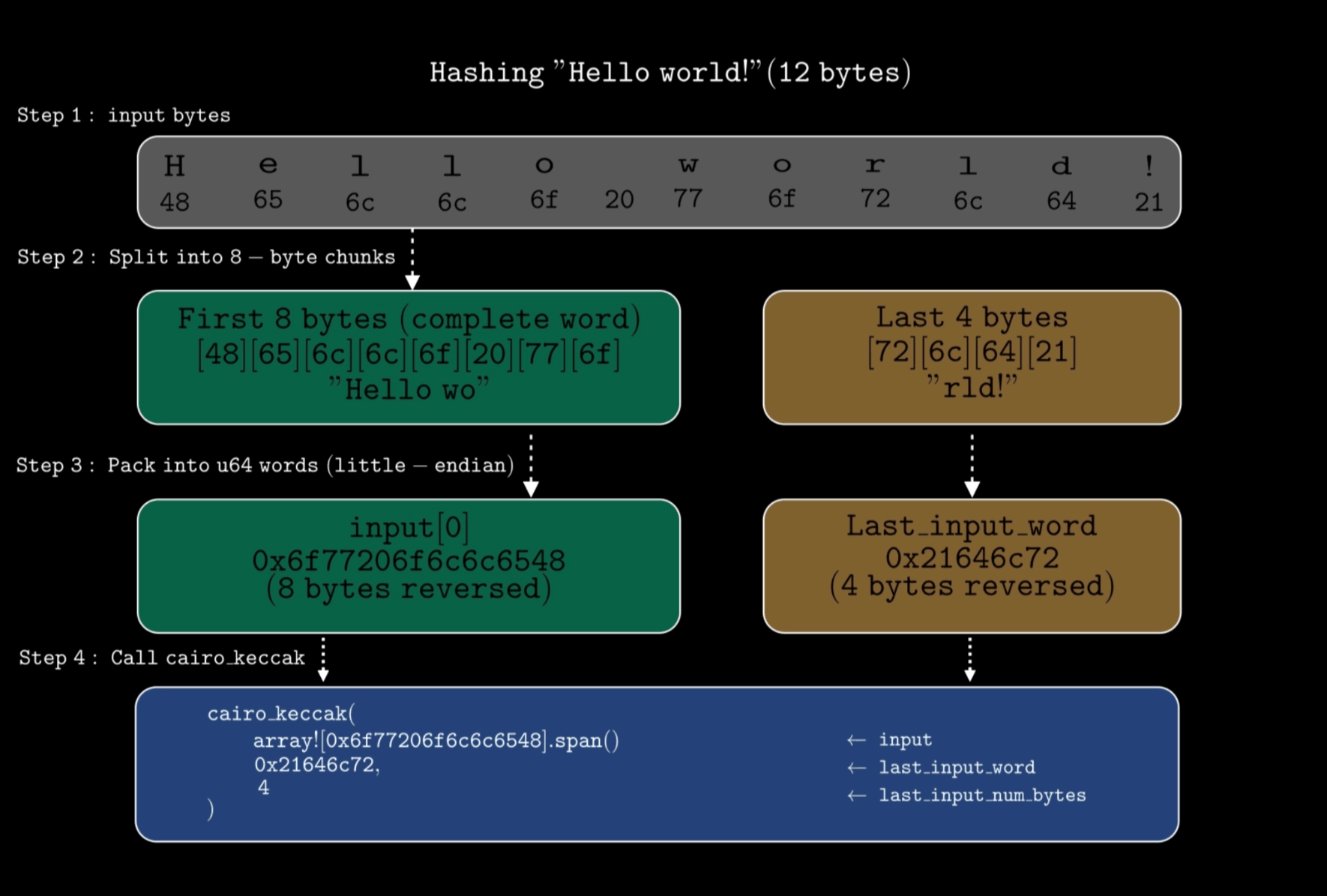
cairo_keccak→ toma tres argumentos:input- array de palabras completas de 64 bits en formato little-endianlast_input_word- bytes restantes deinputque no llenan una palabra completa de 8 bytes. Por ejemplo, si estás aplicando hash a 12 bytes en total, los primeros 8 bytes van eninputcomo una palabra completa, y los últimos 4 bytes van enlast_input_word. Si tu entrada es exactamente divisible por 8 (por ejemplo, 8, 16 o 32 bytes), entonceslast_input_wordes0.last_input_num_bytes- número de bytes enlast_input_word. Debe ser un entero entre0y7, inclusive.
El siguiente diagrama muestra cómo estos parámetros funcionan en conjunto:
Ejemplo 1 – Aplicar hash a datos que son múltiplos de u64 u 8 bytes
Contrato en Solidity:
contract Example { function hash() external pure returns (bytes32) { uint64 one = 1; // 0x0000000000000001 return keccak256(abi.encodePacked(one)); } }Equivalente en Cairo:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::cairo_keccak; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { let mut input = array![0x0100000000000000]; // 1_u64 as little-endian let digest = cairo_keccak(ref input, 0, 0); // no extra bytes println!("Digest: {:?}", digest); } } }Los dos últimos argumentos de
cairo_keccak,last_input_wordylast_input_num_bytes, son 0 porque no tenemos bytes adicionales para procesar.Ejemplo 2 – Aplicar hash a datos que NO son múltiplos de u64 u 8 bytes
Supongamos que queremos aplicar hash a
0x48656c6c6f20776f726c6421que representa “Hello world!” (12 bytes). Dado que 12 no es divisible por 8, necesitaremos usar el parámetrolast_input_word.Contrato en Solidity:
contract Example { function hash() external pure returns (bytes32) { bytes12 input = 0x48656c6c6f20776f726c6421; return keccak256(abi.encodePacked(input)); } }Equivalente en Cairo:
fn hash(self: @ContractState) { // bytes to hash - 0x48656c6c6f20776f726c6421 (12 bytes) // first 8 bytes (48656c6c6f20776f), reversed to little-endian let mut input = array![0x6f77206f6c6c6548]; // Perform the hash // the remaining 4 bytes (726c6421) to little-endian - 0x21646c72 let digest = cairo_keccak(ref input, 0x21646c72, 4); println!("Digest: {:?}", digest); }Aquí:
0x6f77206f6c6c6548son los primeros 8 bytes invertidos.0x21646c72son los 4 bytes restantes invertidos.4indica el conteo de esos bytes restantes.
Estos ejemplos muestran cómo las funciones Keccak de Cairo se alinean con keccak256 de Solidity, pero sus salidas difieren en el orden de los bytes. Cairo devuelve un u256 little-endian, mientras que Solidity produce un bytes32 big-endian. Invierte el orden de los bytes del resultado de Cairo antes de compararlo con un hash de Solidity.
Convertir de Little-Endian a Big-Endian y viceversa
La siguiente animación muestra una conversión de bytes de little-endian a big-endian:
Para hacer lo mismo en Cairo, invertimos el orden de los bytes de un valor u256 invirtiendo cada mitad de 128 bits e intercambiando sus posiciones. Cairo proporciona una función integrada u128_byte_reverse desde el módulo core::integer de Cairo para invertir bytes.
El siguiente ejemplo de código muestra cómo convertir un valor u256 de una representación little-endian a big-endian (y viceversa) invirtiendo el orden de sus bytes:
fn u256_reverse_bytes(x: u256) -> u256 {
u256 {
// Take the high 128 bits, reverse their byte order, put in low position
low: core::integer::u128_byte_reverse(x.high),
// Take the low 128 bits, reverse their byte order, put in high position
high: core::integer::u128_byte_reverse(x.low),
}
}
Dado que un u256 en Cairo está compuesto por dos valores u128 (low y high), invertir el orden de bytes del entero de 256 bits requiere:
- Invertir el orden de los bytes dentro de cada mitad de 128 bits.
- Intercambiar las dos mitades.
La función core::integer::u128_byte_reverse realiza la inversión a nivel de bytes para cada u128. Al aplicarla a ambas mitades e intercambiar sus posiciones, invertimos el orden de bytes de todo el valor de 256 bits.
Debido a que la inversión de bytes es simétrica, esta misma función puede usarse para convertir:
- little-endian → big-endian
- big-endian → little-endian
Al aplicarla dos veces, se devuelve el valor original.