Solidity 依赖 keccak-256 作为其主要哈希函数,从任意数据中派生确定性标识符,例如计算函数选择器或计算映射的存储槽(storage slots),但 Cairo 为不同的上下文提供了不同的哈希函数。
本文涵盖了 Starknet/Cairo 中的三种哈希函数:Pedersen、Poseidon 和 Keccak-256。我们将解释在智能合约中如何以及何时使用它们。
为什么 Cairo 使用三种哈希函数?
像 Starknet 这样的 ZK 证明系统在有限域上工作,其中每个操作都表示为一个约束(constraint)。约束是一个算术方程,它编码了必须满足以生成有效证明的计算规则。一个操作需要的约束越多,证明它的成本就越高。
在这方面,Keccak-256 特别昂贵,因为它是建立在异或(XOR)、与(AND)和位旋转等位操作(bitwise operations)之上的。这些操作不能直接映射到有限域算术,必须使用许多约束来模拟,这使得证明 Keccak-256 的成本比原生对有限域友好的操作要高得多。
因此,Cairo 提供了三种哈希函数,每种用于不同的上下文:
-
Keccak-256 哈希
Cairo 包含此哈希函数是为了与 Ethereum 兼容,例如,计算函数选择器、复制存储布局以及验证 Ethereum 签名。
虽然由于约束过多而未针对 STARK 证明进行优化,频繁使用成本高昂,但它是跨链互操作性以及在 Cairo 中派生存储变量基地址所必需的。
-
Pedersen 哈希
这是一种基于椭圆曲线的哈希函数,定义在 Starknet 的原生域(
felt252)上。它是 Starknet 上使用的第一个哈希函数,现在仍用于计算存储地址(例如,Map类型依赖 Pedersen 对存储键进行哈希)。因此,为了与已经依赖它的现有合约、状态承诺(state commitments)或默克尔树(Merkle trees)兼容,通常需要使用 Pedersen。Keccak 依赖位操作,在 STARK 证明中需要许多约束;而与 Keccak 不同,Pedersen 在 Stark 曲线(Stark-curve)上使用点加法和标量乘法,这使得它在 Cairo 中的证明成本更低。Pedersen 产生
felt252的输出。 -
Poseidon 哈希
它直接在 Starknet 使用的素数域上运行,完全避免了椭圆曲线算术。这导致约束数量大幅减少,使其比 Pedersen 和 Keccak 都更便宜、更快,是 Cairo 中常规哈希、默克尔树和承诺(commitments)的推荐选择。它产生
felt252的输出。
注意:如果你需要与旧版(legacy)合约交互,请使用“Pedersen”。如果你可以自由选择最有效率的选项,请使用“Poseidon”。如果你需要 Ethereum 兼容性,请使用“Keccak”。
如何在 Cairo 中使用哈希函数
现在我们了解了这些哈希函数是什么以及它们的目的是什么,让我们看看在实践中如何使用它们。Cairo 在其核心库中提供了这些哈希函数。对于 Pedersen 和 Poseidon 等函数,它们的预像(preimage,即要进行哈希的输入值)类型必须实现一个名为 Hash 的 trait。
Hash Trait
该 trait 将类型标记为可哈希。它已为 Cairo 的基本类型(felt252、bool、u8 等)实现了,这些类型都可以表示为 felt252 值。对于结构体(structs)和枚举(enums)等复杂类型,派生 Hash(#[derive(Hash)])使它们可以使用任何支持的哈希函数(Poseidon 或 Pedersen)进行哈希,前提是每个字段或变体(variant)本身都是可哈希的。
另一方面,集合类型(Collection types)没有也不能派生 Hash trait;因此是不可哈希的。以下示例说明了哪些类型可以以及哪些类型不能派生 Hash(我们将在代码块之后了解原因):
// ✅ All fields are hashable
// Primitive types can be hashed
#[derive(Hash)]
struct A {
f1: felt252,
f2: u256, // u256 is actually a struct { low: u128, high: u128 }
// but derives Hash by default since both fields are hashable
}
// ❌ Cannot derive Hash: STORAGE collections
// Vectors and Maps in storage cannot be hashed because they don't implement `Hash`.
struct B {
f1: Vec<felt252>,
f2: Map<felt252, u128>,
}
// ❌ Cannot derive Hash: MEMORY collections
// Arrays and Dictionaries in memory cannot be hashed because they don't implement `Hash`.
struct C {
f1: Array<felt252>,
f2: Felt252Dict<u128>,
}
结构体 A 可以派生 Hash,因为两个字段都是可哈希的。虽然 felt252 显然是一个基本类型,但 u256 实际上是一个结构体 { low: u128, high: u128 }。然而,由于 u256 本身派生了 Hash(两个 u128 字段都是可哈希的),在哈希操作中它表现得就像基本类型。其他的结构体不能派生 Hash 是因为:
像 Array 和 Felt252Dict 这样的内存集合在设计上不实现 Hash,所以包含它们的结构体不能使用 derive(Hash),因为该操作要求所有字段都可哈希。
像 Map 和 Vec 这样的类型专门用于存储,这意味着它们的数据存在于合约的持久化存储中,而不是 Cairo 的执行内存中。由于 Hash trait 需要内存中的值,因此这些类型无法实现它。
在 Cairo 中要对值进行哈希,你需要两个组件:Hash trait(将类型标记为可哈希)和一个哈希器状态(hasher state,执行实际的哈希操作)。
哈希器状态(The Hasher State)
哈希器状态逐步对值进行哈希,然后将其完成(finalize)以产生一个摘要(digest,最终的哈希输出)。这种设计使得能够对任意数量的输入进行哈希。
从概念上讲,将对一组值进行哈希想象成这样:
hashFunc(x1, x2, x3, …, xn)
哈希器不是单步计算完成,而是增量工作的:
-
初始化哈希器状态
状态从一个预定义的常量值开始,该值被硬编码到哈希函数的规范中。
-
哈希第一个输入
state₁ = h(state₀, x1) -
哈希下一个输入
state₂ = h(state₁, x2) -
继续哈希输入
这个过程对每个输入重复进行,直到所有值都被哈希:
stateₙ = h(stateₙ₋₁, xn) -
完成(Finalize)状态
最终的状态就是摘要:
digest = finalize(stateₙ)
Cairo 暴露了两个 trait 用于操作哈希器状态:
-
HashStateTrait: 此 trait 专为哈希 Cairo 原生域元素(
felt252)而设计。它提供两个核心方法:
.update:仅使用felt252类型的值更新哈希状态。.finalize:完成该状态并返回作为felt252的哈希摘要。

-
HashStateExTrait: 此 trait “扩展(extends)”了 HashStateTrait。
它提供一个方法:
.update_with:使用实现了Hashtrait 的“任何类型”的值来更新哈希状态。

下一步是看看 Hash trait 和哈希器状态在实践中是如何结合在一起的。我们将演示如何使用它们通过 Pedersen 和 Poseidon 对值进行哈希。
Pedersen 与 Poseidon
在 Cairo 中,Pedersen 和 Poseidon 都暴露了相同的哈希工作流:
- 初始化(Initialize) 哈希状态
- 更新(Update) 包含一个或多个值的状态
- 完成(Finalize) 以产生一个
felt252摘要
这使得它们在使用上看起来几乎完全相同,但有一个关键的区别:Pedersen 需要一个“基准(base)”值。
以下是我们如何使用 Poseidon 对两个字段进行哈希的示例:
PoseidonTrait::new()
.update(a)
.update(b)
.finalize()
使用 Pedersen:
PedersenTrait::new(<*base_value*>) // base
.update(a)
.update(b)
.finalize()
从用法的角度来看,两者之间唯一可见的区别是传递给 PedersenTrait::new 的额外参数,称为 base(基准)。
Pedersen “base” 究竟是什么
Pedersen base 仅仅是一个 felt252 类型的初始值。
Pedersen 是一个带有 2 个输入的哈希函数(它总是对两个 felt252 值进行哈希),这意味着没有原生的“哈希一个值”操作。要对单个值进行哈希,将 base 作为第一个输入,并将要哈希的实际值(预像)作为第二个输入。
概念上:
final_hash = pedersen(base, a)
当对多个值进行哈希时,第一个哈希输出成为下一个状态,并向前形成链条。例如,对带有 base 的三个值 a、b 和 c 进行哈希的过程如下:
initial_state = pedersen(base, a)
state1 = pedersen(initial_state, b)
final_hash = pedersen(state1, c)
注意前一个状态是如何成为下一个哈希操作的第一个输入的,这正是使其形成链条的原因。
base 还可以用作域分隔符(domain separator)。 使用不同的 base 值将哈希置于不同的逻辑域中,即使以相同的顺序对相同的值进行哈希也是如此。例如,假设你的合约为了一次空投申领(airdrop claim)和一次转账授权(transfer approval)都需要哈希一个 (user, amount) 组合。如果没有域分隔,这两个操作针对相同的输入将会产生相同的哈希。通过对每个操作使用不同的 base 值,这两个哈希会被放置在不同的逻辑域中,并且即使给定完全相同的输入,也总是会产生不同的输出:
// Base 0: airdrop claim domain
let claim_hash = PedersenTrait::new(0)
.update(user)
.update(amount)
.finalize();
// Base 1: transfer approval domain
let approval_hash = PedersenTrait::new(1)
.update(user)
.update(amount)
.finalize();
// claim_hash != approval_hash, even though inputs are identical
Poseidon:Base 已经内置
另一方面,Poseidon 不需要显式的 base 值,因为它内部已经有一个固定的状态。当调用 PoseidonTrait::new() 时,它从该预定义的初始状态开始。
因此,在概念上,在 Poseidon 中哈希单个值看起来像这样:
initial_state = PREDEFINED_STATE
hash = poseidon(initial_state, a)
对于两个输入 a 和 b:
initial_state = PREDEFINED_STATE
state1 = poseidon(initial_state, a)
hash = poseidon(state1, b)
让我们看一些如何在合约中使用 Poseidon 和 Pedersen 的示例。
示例 1:使用 .update 对两个域元素进行哈希
下面的代码示例展示了如何使用 Poseidon 对两个 felt252 值进行哈希:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_poseidon(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_felts_poseidon(self: @ContractState, a: felt252, b: felt252) {
let digest = PoseidonTrait::new() // initialize a hash state
.update(a) // takes first felt252
.update(b) // takes second felt252
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Pedersen 的思路也相同;唯一的区别是你在创建状态时需要传递一个 base。0 是一个常见的选择,并且将在本文中全程使用:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_pedersen(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_felts_pedersen(self: @ContractState, a: felt252, b: felt252) {
let digest = PedersenTrait::new(0) // 0 as the base for the running hash
.update(a)
.update(b)
.finalize();
println!("Digest: {:?}", digest);
}
}
}
示例 2:使用 .update_with 进行哈希
到目前为止,我们只使用 .update 对 felt252 值进行了哈希。但在实践中,我们经常需要对其他类型的值进行哈希。
这就是 .update_with 的用途。它来自 HashStateExTrait,用于对实现了(或派生了)Hash trait 的任何类型进行哈希。
使用 Poseidon 对 ContractAddress 进行哈希
在下面的代码中,我们对两个 ContractAddress 值 a 和 b 进行哈希。由于 ContractAddress 实现了 Hash trait,我们可以使用 .update_with() 直接将它们传递给哈希器状态。
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_poseidon(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_addresses_poseidon(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PoseidonTrait::new() // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
使用 Pedersen 对 ContractAddress 进行哈希
下面的合约使用 Pedersen 哈希函数对两个地址进行哈希:
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_pedersen(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_addresses_pedersen(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PedersenTrait::new(0) // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
使用 Poseidon 对 struct 进行哈希
在下面的代码中,因为 MyStruct 被用作接口中的一个参数,所以我们在合约模块外部定义它,以便接口和合约实现都能访问它。任何出现在 #[starknet::interface] 中的结构体必须:
- 在合约模块外部定义
- 派生
Serde,以便它可以被序列化为一个felt252序列,也可以从中反序列化回来 - 派生
Drop,以便该值在超出作用域时可以被安全地丢弃
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_poseidon(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::poseidon::PoseidonTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_poseidon(self: @ContractState, my_struct: MyStruct) {
let digest = PoseidonTrait::new().update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
使用 Pedersen 对 struct 进行哈希
这对于 Pedersen 原理相同,只需将导入替换为 Pedersen 哈希函数,将状态替换为 PedersenTrait::new(0),并保持其余部分不变即可:
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::pedersen::PedersenTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, my_struct: MyStruct) {
let digest = PedersenTrait::new(0) // *** REPLACEMENT HERE *** //
.update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
如果一个结构体仅在合约内部使用,而未通过接口公开,则它不需要派生 Serde。
以下是在合约内部定义和使用可哈希结构体的示例:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(
self: @TContractState,
value1: u256,
value2: felt252
);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{HashStateExTrait, HashStateTrait};
use core::pedersen::PedersenTrait;
// *** DEFINE STRUCT INSIDE THE CONTRACT *** //
#[derive(Hash, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, value1: u256, value2: felt252) {
// *** INITIALIZE THE STRUCT *** //
let my_struct = MyStruct { a: value1, b: value2 };
let digest = PedersenTrait::new(0).update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
示例 3:对数组(Arrays)进行哈希
我们不能像处理其他类型那样直接对数组进行哈希,因为数组本身不实现 Hash trait。要对数组进行哈希,你必须遍历每个元素,逐步更新哈希状态,然后在最后调用 .finalize()。
使用 Poseidon 对 Array<felt252> 进行哈希:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::poseidon::PoseidonTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_poseidon(self: @ContractState, values: Array<felt252>) {
let mut state = PoseidonTrait::new(); // The hash state
let mut i = 0;
let len = values.len();
// The loop
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// Finalize the state
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
Cairo 有一个内置的 Poseidon 辅助函数,它在底层处理循环并自动管理状态更新:poseidon_hash_span。
使用内置的 Poseidon 辅助函数对 felt252 数组进行哈希
poseidon_hash_span 函数接受一个 Span<felt252> 作为输入,遍历每个元素以构建哈希状态,然后进行 finalizes 并返回单个 felt252 摘要。
下面是一个示例。与需要导入 PoseidonTrait 和 HashStateTrait 的手动 Poseidon 哈希不同,poseidon_hash_span 是一个独立函数,在内部处理了所有事情。我们只需要导入并使用它:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_builtin_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `poseidon_hash_span`
use core::poseidon::poseidon_hash_span;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_builtin_poseidon(self: @ContractState, values: Array<felt252>) {
// Convert Array<felt252> to Span<felt252>
let span = values.span();
// USE `poseidon_hash_span`
let digest = poseidon_hash_span(span);
println!("Digest: {:?}", digest);
}
}
}
由于 poseidon_hash_span 函数接受一个 Span<felt252> 作为输入,我们首先使用 .span() 将数组转换为 span,然后将其传递给内置函数,该函数返回一个 felt252 摘要。
如果我们向 hash_array_manual_poseidon 和 hash_array_builtin_poseidon 函数传递相同的数组,它们将产生完全相同的 Poseidon 哈希,因为 poseidon_hash_span 仅仅是在底层执行了手动循环。
使用 Pedersen 对 Array<felt252> 进行哈希:
使用 Pedersen 对 felt 数组进行哈希的步骤类似于 Poseidon:你手动遍历数组并按顺序哈希每个元素。然而,在 Starknet 中有一个关于使用 Pedersen 哈希数组的惯例,即必须将数组长度作为最后一个元素包含进去。这种模式在整个 Starknet 生态系统中被一致遵循,包括协议实现以及 starknet.js 等标准库。
下面的 hash_array_manual_pedersen 函数展示了该模式的实际应用。在哈希所有数组元素之后,我们会在完成(finalize)哈希状态之前,将数组长度作为最终元素进行哈希:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_pedersen(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::pedersen::PedersenTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_pedersen(self: @ContractState, values: Array<felt252>) {
let mut state = PedersenTrait::new(0);
let mut i = 0;
let len = values.len();
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// FOCUS HERE: Include the array length
state = state.update(len.into());
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
核心要点:
- 需要自定义逻辑(例如,混合其他数据类型或条件更新)时,使用手动循环。
- 使用
poseidon_hash_span计算felt252数组的 Poseidon 哈希。它更简洁,需要的代码更少。- 使用 Pedersen 对数组进行哈希的标准模式是在完成(finalize)哈希状态之前包含数组长度作为最后一个元素。
Keccak256
Cairo 的 core::keccak 模块提供四个函数:
compute_keccak_byte_array:哈希一个ByteArray。keccak_u256s_be_inputs:哈希一个以大端(big-endian)格式编码的u256数组。keccak_u256s_le_inputs:哈希一个以小端(little-endian)格式编码的u256数组。cairo_keccak:使用自定义填充(padding)哈希字节序列(等效于 Solidity 的keccak256(abi.encodePacked(val)))。
所有这些都返回一个 u256,代表与 Solidity 的 keccak256 生成的相同的 32 字节摘要。区别在于值的表示方式:Solidity 以大端格式将摘要作为 bytes32 返回,而 Cairo 将其作为小端 u256 返回。
例如,假设 Solidity 对某个值的 keccak 哈希产生了 0x1234...5678。Cairo 的 keccak 会将相同的摘要表示为小端的 u256,因此其字节顺序将被颠倒:0x7856...3412。我们将在最后一节探讨如何使 Cairo 和 Solidity 的 keccak 结果相匹配。
Cairo 的 Keccak 函数及其对应的 Solidity 等效函数
-
compute_keccak_byte_array→ 哈希一个ByteArray。Solidity 合约:
contract Example { function hashHello() external pure returns (bytes32) { return keccak256(abi.encodePacked("Hello RareSkills")); } }Cairo 等效代码:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash_hello(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::compute_keccak_byte_array; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash_hello(self: @ContractState) { // Perform the hash let digest = compute_keccak_byte_array(@"Hello RareSkills"); println!("Digest: {:?}", digest); } } } -
keccak_u256s_be_inputs→ 以大端顺序对u256数组进行哈希,这与 Solidity 的默认编码匹配。Solidity 合约:
contract Example { function hash() external pure returns (bytes32) { return keccak256(abi.encode(1,2)); } }Cairo 等效代码:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_be_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_be_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
keccak_u256s_le_inputs→ 以小端顺序哈希一个u256数组。Solidity 可以通过在哈希前将输入手动转换为小端来复现此操作。Solidity 合约:
contract Example { function hash() external pure returns (bytes32) { // Convert 1_u256 and 2_u256 to little endian uint256 one_le = 0x0100000000000000000000000000000000000000000000000000000000000000; uint256 two_le = 0x0200000000000000000000000000000000000000000000000000000000000000; return keccak256(abi.encode(one_le,two_le)); } }Cairo 等效代码:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_le_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_le_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
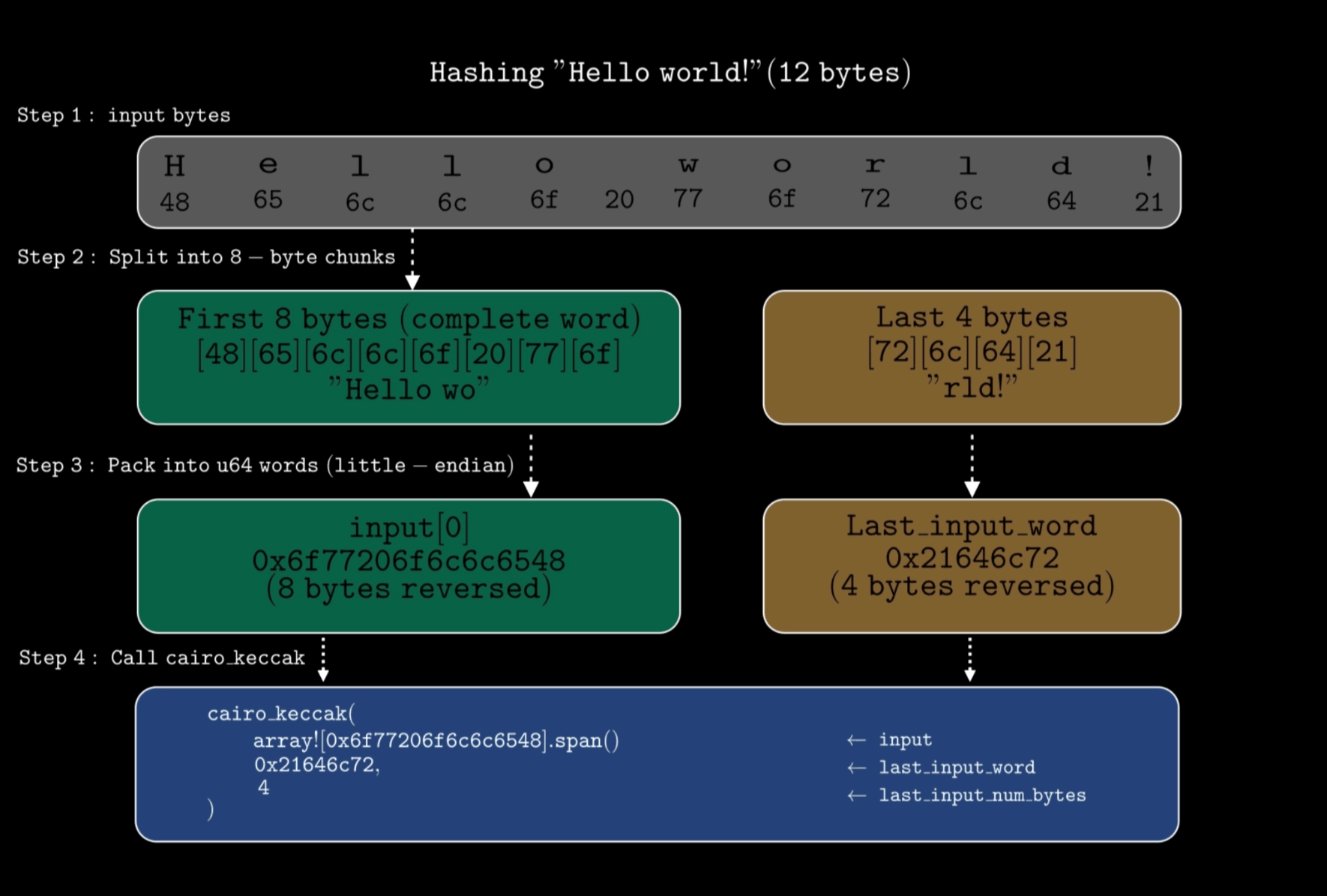
cairo_keccak→ 它接收三个参数:input- 包含以小端格式表示的完整 64 位字(words)的数组last_input_word- 来自input的未填满完整 8 字节字的剩余字节。例如,如果你总共要哈希 12 个字节,前 8 个字节作为一个完整字存入input,最后 4 个字节存入last_input_word。如果你的输入恰好能被 8 整除(例如 8、16 或 32 个字节),那么last_input_word为0。last_input_num_bytes- 在last_input_word中的字节数。必须是0到7之间(含)的整数。
下图显示了这些参数是如何协同工作的:
示例 1 – 对作为 u64 或 8 字节倍数的数据进行哈希
Solidity 合约:
contract Example { function hash() external pure returns (bytes32) { uint64 one = 1; // 0x0000000000000001 return keccak256(abi.encodePacked(one)); } }Cairo 等效代码:
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::cairo_keccak; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { let mut input = array![0x0100000000000000]; // 1_u64 as little-endian let digest = cairo_keccak(ref input, 0, 0); // no extra bytes println!("Digest: {:?}", digest); } } }最后两个
cairo_keccak参数last_input_word和last_input_num_bytes均为 0,因为我们没有额外的字节需要哈希。示例 2 – 对不是 u64 或 8 字节倍数的数据进行哈希
假设我们要哈希代表 “Hello world!”(12 个字节)的
0x48656c6c6f20776f726c6421。因为 12 不能被 8 整除,我们需要使用last_input_word参数。Solidity 合约:
contract Example { function hash() external pure returns (bytes32) { bytes12 input = 0x48656c6c6f20776f726c6421; return keccak256(abi.encodePacked(input)); } }Cairo 等效代码:
fn hash(self: @ContractState) { // bytes to hash - 0x48656c6c6f20776f726c6421 (12 bytes) // first 8 bytes (48656c6c6f20776f), reversed to little-endian let mut input = array![0x6f77206f6c6c6548]; // Perform the hash // the remaining 4 bytes (726c6421) to little-endian - 0x21646c72 let digest = cairo_keccak(ref input, 0x21646c72, 4); println!("Digest: {:?}", digest); }此处:
0x6f77206f6c6c6548是反转的前 8 个字节。0x21646c72是反转的剩余 4 个字节。4表示这些剩余字节的数量。
这些示例说明了 Cairo 的 Keccak 函数是如何与 Solidity 的 keccak256 保持一致的,但它们的输出在字节顺序上有所不同。Cairo 返回一个小端 u256,而 Solidity 产生一个大端 bytes32。在将 Cairo 的结果与 Solidity 哈希进行比较之前,请反转 Cairo 结果的字节顺序。
小端与大端之间的相互转换
以下动画显示了字节从小端到大端的转换过程:
要在 Cairo 中执行相同操作,我们通过反转每个 128 位半部分的字节顺序并交换它们的位置,来反转 u256 值的字节顺序。Cairo 的 core::integer 模块提供了一个内置函数 u128_byte_reverse 来反转字节。
以下代码示例展示了如何通过反转其字节顺序将 u256 值从小端表示转换为大端表示(反之亦然):
fn u256_reverse_bytes(x: u256) -> u256 {
u256 {
// Take the high 128 bits, reverse their byte order, put in low position
low: core::integer::u128_byte_reverse(x.high),
// Take the low 128 bits, reverse their byte order, put in high position
high: core::integer::u128_byte_reverse(x.low),
}
}
由于 Cairo 中的 u256 由两个 u128 值(low 和 high)组成,反转 256 位整数的字节顺序需要:
- 反转每个 128 位半部分内的字节顺序。
- 交换这两个半部分。
core::integer::u128_byte_reverse 函数为每个 u128 执行字节级反转。通过将其应用于两个半部分并交换它们的位置,我们能够反转整个 256 位值的字节顺序。
因为字节反转是对称的,所以同一函数可用于转换:
- 小端 → 大端
- 大端 → 小端
应用两次即可返回原始值。