Solidity मनमाने (arbitrary) डेटा से डिटरमिनिस्टिक आइडेंटिफायर्स प्राप्त करने के लिए अपने प्राथमिक hash function के रूप में keccak-256 पर निर्भर करता है, जैसे कि function selectors की गणना करना या mappings के लिए storage slots की गणना करना, लेकिन Cairo अलग-अलग संदर्भों (contexts) के लिए अलग-अलग hash functions प्रदान करता है।
यह लेख Starknet/Cairo में तीन hash functions को कवर करता है: Pedersen, Poseidon, और Keccak-256. हम समझाएंगे कि अपने smart contracts में उनमें से प्रत्येक का उपयोग कैसे और कब करना है।
Cairo तीन Hash Functions का उपयोग क्यों करता है?
Starknet जैसे ZK proof सिस्टम finite fields पर काम करते हैं, जहां हर ऑपरेशन को एक constraint (बाधा/शर्त) के रूप में व्यक्त किया जाता है। एक constraint एक अंकगणितीय (arithmetic) समीकरण है जो गणना नियमों को एन्कोड करता है जिन्हें एक वैध proof उत्पन्न करने के लिए पूरा किया जाना चाहिए। एक ऑपरेशन के लिए जितने अधिक constraints की आवश्यकता होती है, उसे साबित (prove) करना उतना ही महंगा होता है।
इस संबंध में Keccak-256 विशेष रूप से महंगा है क्योंकि यह XOR, AND, और bit rotations जैसे bitwise ऑपरेशन्स पर बना है। ये ऑपरेशन्स सीधे field arithmetic पर मैप नहीं होते हैं और इन्हें कई constraints का उपयोग करके एम्यूलेट (emulate) किया जाना चाहिए, जिससे Keccak-256 को साबित करना उन ऑपरेशन्स की तुलना में काफी अधिक महंगा हो जाता है जो मूल रूप से field-friendly हैं।
इसलिए Cairo तीन hash functions प्रदान करता है, प्रत्येक अलग संदर्भ के लिए:
-
Keccak-256 Hash
इस hash function को Ethereum के साथ कम्पैटिबिलिटी (अनुकूलता) के लिए Cairo में शामिल किया गया है, उदाहरण के लिए, function selectors की गणना करना, storage layouts को रेप्लिकेट करना, और Ethereum signatures को वेरीफाई करना।
हालांकि यह बहुत अधिक constraints के कारण STARK proofs के लिए अनुकूलित (optimized) नहीं है और इसलिए बार-बार उपयोग करने के लिए महंगा है, इसकी आवश्यकता cross-chain इंटरऑपरेबिलिटी (interoperability) के लिए, और Cairo में storage variables के बेस एड्रेस (base address) को प्राप्त करने के लिए होती है।
-
Pedersen Hash
Starknet के नेटिव फील्ड (
felt252) पर परिभाषित एक elliptic-curve आधारित hash function. यह Starknet पर उपयोग किया जाने वाला पहला hash function था और अभी भी storage addresses की गणना के लिए उपयोग किया जाता है (उदाहरण के लिए,Mapप्रकार storage keys को हैश करने के लिए Pedersen पर निर्भर करता है)। परिणामस्वरूप, Pedersen अक्सर मौजूदा contracts, state commitments, या Merkle trees के साथ अनुकूलता के लिए आवश्यक होता है जो पहले से ही इस पर निर्भर हैं।Keccak के विपरीत, जो bitwise ऑपरेशन्स पर निर्भर करता है और जिन्हें STARK proofs में कई constraints की आवश्यकता होती है, Pedersen Stark-curve पर point additions और scalar multiplications का उपयोग करता है जो इसे Cairo के अंदर साबित करने के लिए सस्ता बनाता है। Pedersen
felt252आउटपुट उत्पन्न करता है। -
Poseidon Hash
यह सीधे Starknet द्वारा उपयोग किए जाने वाले prime field पर काम करता है, जो पूरी तरह से elliptic-curve अंकगणित से बचता है। इसके परिणामस्वरूप बहुत कम constraints होते हैं, जिससे यह Pedersen और Keccak दोनों की तुलना में सस्ता और तेज हो जाता है, और Cairo के भीतर सामान्य हैशिंग, Merkle trees, और commitments के लिए अनुशंसित (recommended) विकल्प है। यह
felt252आउटपुट उत्पन्न करता है।
Note: यदि आपको लेगेसी contracts के साथ इंटरैक्ट करने की आवश्यकता है, तो “Pedersen” का उपयोग करें। यदि आप एफिशिएंसी (दक्षता) के लिए सबसे अच्छा विकल्प चुनने के लिए स्वतंत्र हैं, तो आप “Poseidon” का उपयोग करें। यदि आपको Ethereum कम्पैटिबिलिटी चाहिए, तो “Keccak” का उपयोग करें।
Cairo में Hash Functions का उपयोग कैसे करें
अब जब हम समझ गए हैं कि ये hash functions क्या हैं और इनका उद्देश्य क्या है, तो आइए देखें कि व्यवहार में इनका उपयोग कैसे किया जाए। Cairo अपनी core library में इन hash functions को प्रदान करता है। Pedersen और Poseidon जैसे functions के लिए, उनके preimage (हेश किए जाने वाला इनपुट मान) प्रकार को Hash नामक एक trait को इम्प्लीमेंट (implement) करना होगा।
Hash Trait
यह trait किसी प्रकार (type) को हैशेबल (hashable) के रूप में चिह्नित करता है। इसे Cairo के प्रिमिटिव प्रकारों (felt252, bool u8, आदि) के लिए इम्प्लीमेंट किया गया है जिन्हें सभी felt252 मानों के रूप में दर्शाया जा सकता है। structs और enums जैसे जटिल प्रकारों के लिए, Hash (#[derive(Hash)]) डिराइव करने से उन्हें किसी भी समर्थित hash function (Poseidon या Pedersen) का उपयोग करके हैशेबल बनाया जा सकता है, बशर्ते कि प्रत्येक field या variant स्वयं हैशेबल हो।
दूसरी ओर Collection प्रकार Hash trait को डिराइव नहीं करते हैं और नहीं कर सकते हैं; इसलिए वे अनहैशेबल (unhashable) हैं। निम्नलिखित उदाहरण दर्शाते हैं कि कौन से प्रकार Hash डिराइव कर सकते हैं और कौन से नहीं (हम कोड ब्लॉक के बाद देखेंगे कि ऐसा क्यों है):
// ✅ All fields are hashable
// Primitive types can be hashed
#[derive(Hash)]
struct A {
f1: felt252,
f2: u256, // u256 is actually a struct { low: u128, high: u128 }
// but derives Hash by default since both fields are hashable
}
// ❌ Cannot derive Hash: STORAGE collections
// Vectors and Maps in storage cannot be hashed because they don't implement `Hash`.
struct B {
f1: Vec<felt252>,
f2: Map<felt252, u128>,
}
// ❌ Cannot derive Hash: MEMORY collections
// Arrays and Dictionaries in memory cannot be hashed because they don't implement `Hash`.
struct C {
f1: Array<felt252>,
f2: Felt252Dict<u128>,
}
Struct A, Hash डिराइव कर सकता है क्योंकि दोनों fields हैशेबल हैं। जबकि felt252 स्पष्ट रूप से एक प्रिमिटिव प्रकार है, u256 वास्तव में एक struct { low: u128, high: u128 } है। हालाँकि, चूंकि u256 स्वयं Hash डिराइव करता है (दोनों u128 fields हैशेबल हैं), यह हैशिंग उद्देश्यों के लिए एक प्रिमिटिव प्रकार की तरह व्यवहार करता है। अन्य structs Hash डिराइव नहीं कर सकते क्योंकि:
Array और Felt252Dict जैसे Memory collections डिज़ाइन के अनुसार Hash को इम्प्लीमेंट नहीं करते हैं, इसलिए उन्हें शामिल करने वाले structs derive(Hash) का उपयोग नहीं कर सकते क्योंकि इसके लिए सभी fields का हैशेबल होना आवश्यक है।
Map और Vec जैसे प्रकार विशेष रूप से storage के लिए होते हैं, जिसका अर्थ है कि उनका डेटा Cairo की execution memory के बजाय contract के परसिस्टेंट स्टोरेज (persistent storage) में रहता है। चूँकि Hash trait को इन-मेमोरी (in-memory) मानों की आवश्यकता होती है, ये प्रकार इसे इम्प्लीमेंट नहीं कर सकते।
Cairo में मानों को हैश करने के लिए, आपको दो घटकों (components) की आवश्यकता होती है: Hash trait (जो प्रकारों को हैशेबल के रूप में चिह्नित करता है) और एक hasher state (जो वास्तविक हैशिंग ऑपरेशन करता है)।
Hasher State
Hasher state प्रगतिशील (progressively) रूप से मानों को हैश करता है और फिर एक digest (अंतिम हैश आउटपुट) उत्पन्न करने के लिए इसे अंतिम रूप (finalize) देता है। यह डिज़ाइन कितनी भी संख्या (arbitrary number) में इनपुट्स को हैश करना संभव बनाता है।
वैचारिक (conceptually) रूप से, मानों की एक सूची को हैश करने के बारे में इस प्रकार सोचें:
hashFunc(x1, x2, x3, …, xn)
इसे एक ही चरण में गणना करने के बजाय, हैशर इंक्रीमेंटल (incrementally) रूप से काम करता है:
-
hasher state को इनिशियलाइज़ करें
State एक पूर्वनिर्धारित (predefined) constant मान से शुरू होती है जो hash function के स्पेसिफिकेशन में हार्डकोड की गई होती है।
-
पहले इनपुट को हैश करें
state₁ = h(state₀, x1) -
अगले इनपुट को हैश करें
state₂ = h(state₁, x2) -
इनपुट्स को हैश करना जारी रखें
यह प्रक्रिया प्रत्येक इनपुट के लिए तब तक दोहराई जाती है जब तक कि सभी मानों को हैश नहीं कर लिया जाता:
stateₙ = h(stateₙ₋₁, xn) -
state को फाइनलाइज़ करें
अंतिम state ही digest है:
digest = finalize(stateₙ)
Cairo hasher state के साथ काम करने के लिए दो traits को एक्सपोज़ करता है:
-
HashStateTrait: यह trait Cairo के नेटिव फील्ड एलिमेंट्स (
felt252) को हैश करने के लिए डिज़ाइन किया गया है।यह दो मुख्य विधियाँ (methods) प्रदान करता है:
.update: केवलfelt252प्रकार के मान के साथ hash state को अपडेट करता है।.finalize: state को फाइनलाइज़ करता है और hash digest कोfelt252के रूप में लौटाता है।

-
HashStateExTrait: यह trait HashStateTrait को “एक्सटेंड” करता है।
यह एक विधि (method) प्रदान करता है:
.update_with: hash state को “किसी भी प्रकार” के मान के साथ अपडेट करता है जोHashtraits को इम्प्लीमेंट करता है।

अगला कदम यह देखना है कि व्यवहार में Hash trait और hasher state कैसे एक साथ आते हैं। हम प्रदर्शित करेंगे कि Pedersen और Poseidon के साथ मानों को हैश करने के लिए उनका उपयोग कैसे किया जाए।
Pedersen और Poseidon
Pedersen और Poseidon दोनों Cairo में समान हैशिंग वर्कफ़्लो प्रस्तुत करते हैं:
- एक hash state को Initialize करें
- इसे एक या अधिक मानों के साथ Update करें
- एक
felt252digest उत्पन्न करने के लिए Finalize करें
यह उपयोग करने में उन्हें लगभग समान बनाता है, बस एक मुख्य अंतर है: Pedersen को “base” (आधार) मान की आवश्यकता होती है।
यहाँ एक उदाहरण दिया गया है कि हम Poseidon का उपयोग करके दो fields को कैसे हैश करेंगे:
PoseidonTrait::new()
.update(a)
.update(b)
.finalize()
Pedersen का उपयोग करके:
PedersenTrait::new(<*base_value*>) // base
.update(a)
.update(b)
.finalize()
उपयोग के दृष्टिकोण से, दोनों के बीच एकमात्र दिखाई देने वाला अंतर PedersenTrait::new में पास किया गया अतिरिक्त आर्ग्यूमेंट (argument) है, जिसे base कहा जाता है।
Pedersen “base” वास्तव में क्या है
Pedersen base केवल felt252 प्रकार का एक प्रारंभिक मान (initial value) है।
Pedersen एक 2-इनपुट hash function है (यह हमेशा दो felt252 मानों को हैश करता है), जिसका अर्थ है कि कोई नेटिव “एक मान को हैश करें” ऑपरेशन नहीं है। किसी एकल मान को हैश करने के लिए, base को पहले इनपुट के रूप में और हैश किए जाने वाले वास्तविक मान (preimage) को दूसरे इनपुट के रूप में प्रदान किया जाता है।
वैचारिक रूप से:
final_hash = pedersen(base, a)
कई मानों को हैश करते समय, पहला हैश आउटपुट अगली state बन जाता है और इसे आगे चेन (chain) किया जाता है। उदाहरण के लिए, base के साथ तीन मानों a, b और c को हैश करना इस तरह दिखता है:
initial_state = pedersen(base, a)
state1 = pedersen(initial_state, b)
final_hash = pedersen(state1, c)
ध्यान दें कि कैसे पिछली state अगले हैश ऑपरेशन में पहला इनपुट बन जाती है, ठीक यही इसे एक चेन बनाता है।
Base का उपयोग domain separator के रूप में भी किया जा सकता है। विभिन्न base मानों का उपयोग करने से हैश अलग-अलग तार्किक डोमेन (logical domains) में आ जाते हैं, भले ही समान मानों को समान क्रम में हैश किया गया हो। उदाहरण के लिए, कल्पना करें कि आपका contract एयरड्रॉप क्लेम (airdrop claim) और ट्रांसफर अप्रूवल (transfer approval) दोनों के लिए एक (user, amount) पेयर को हैश करता है। डोमेन सेपरेशन के बिना, दोनों ऑपरेशन्स समान इनपुट्स के लिए समान हैश उत्पन्न करेंगे। प्रत्येक ऑपरेशन के लिए अलग base मान का उपयोग करके, दोनों हैश को अलग-अलग लॉजिकल डोमेन में रखा जाता है और समान इनपुट दिए जाने पर भी हमेशा अलग आउटपुट उत्पन्न करेंगे:
// Base 0: airdrop claim domain
let claim_hash = PedersenTrait::new(0)
.update(user)
.update(amount)
.finalize();
// Base 1: transfer approval domain
let approval_hash = PedersenTrait::new(1)
.update(user)
.update(amount)
.finalize();
// claim_hash != approval_hash, even though inputs are identical
Poseidon: Base पहले से ही मौजूद है
दूसरी ओर Poseidon को किसी स्पष्ट (explicit) base मान की आवश्यकता नहीं है क्योंकि इसमें पहले से ही एक आंतरिक निश्चित state होती है। जब PoseidonTrait::new() को कॉल किया जाता है, तो यह उस पूर्वनिर्धारित (predefined) state से शुरू होता है।
तो वैचारिक रूप से, Poseidon में एक एकल (single) मान को हैश करना इस तरह दिखता है:
initial_state = PREDEFINED_STATE
hash = poseidon(initial_state, a)
दो इनपुट a और b के साथ:
initial_state = PREDEFINED_STATE
state1 = poseidon(initial_state, a)
hash = poseidon(state1, b)
आइए एक contract में Poseidon और Pedersen का उपयोग करने के कुछ उदाहरण देखें।
उदाहरण 1: .update के साथ दो Field Elements को हैश करना
नीचे दिया गया कोड उदाहरण दर्शाता है कि Poseidon का उपयोग करके दो felt252 मानों को कैसे हैश किया जाए:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_poseidon(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_felts_poseidon(self: @ContractState, a: felt252, b: felt252) {
let digest = PoseidonTrait::new() // initialize a hash state
.update(a) // takes first felt252
.update(b) // takes second felt252
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Pedersen के लिए भी समान विचार; केवल अंतर यह है कि state बनाते समय आप एक base पास करते हैं। 0 एक सामान्य विकल्प है और इसका उपयोग पूरे लेख में किया जाएगा:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_felts_pedersen(self: @TContractState, a: felt252, b: felt252);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait // .update(felt252) AND .finalize()
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_felts_pedersen(self: @ContractState, a: felt252, b: felt252) {
let digest = PedersenTrait::new(0) // 0 as the base for the running hash
.update(a)
.update(b)
.finalize();
println!("Digest: {:?}", digest);
}
}
}
उदाहरण 2: .update_with के साथ हैशिंग
अब तक, हमने केवल .update का उपयोग करके felt252 मानों को हैश किया है। लेकिन व्यवहार में, हम अक्सर अन्य प्रकारों के मानों को हैश करना चाहेंगे।
इसके लिए ही .update_with है। यह HashStateExTrait से आता है और इसका उपयोग किसी भी प्रकार को हैश करने के लिए किया जाता है जो Hash trait को इम्प्लीमेंट (या डिराइव) करता है।
Poseidon का उपयोग करके ContractAddress को हैश करना
नीचे दिए गए कोड में, हम दो ContractAddress मानों, a और b को हैश करते हैं। चूँकि ContractAddress, Hash trait को इम्प्लीमेंट करता है, हम उन्हें .update_with() का उपयोग करके सीधे hasher state में पास कर सकते हैं।
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_poseidon(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Poseidon` HASH FUNCTION
use core::poseidon::PoseidonTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE POSEIDON HASH ***//
fn hash_two_addresses_poseidon(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PoseidonTrait::new() // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Pedersen का उपयोग करके ContractAddress को हैश करना
नीचे दिया गया यह contract Pedersen hash function का उपयोग करके दो एड्रेस (addresses) को हैश करता है:
use starknet::ContractAddress;
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_two_addresses_pedersen(
self: @TContractState,
a: ContractAddress,
b: ContractAddress
);
}
#[starknet::contract]
mod HelloStarknet {
use starknet::ContractAddress;
// IMPORT `Pedersen` HASH FUNCTION
use core::pedersen::PedersenTrait;
// IMPORT THE TRAIT
use core::hash::{
HashStateTrait,
HashStateExTrait // .update_with(<T>) *** NEWLY ADDED ***
};
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
//*** FUNCTION THAT IMPLEMENTS THE PEDERSEN HASH ***//
fn hash_two_addresses_pedersen(self: @ContractState, a: ContractAddress, b: ContractAddress) {
let digest = PedersenTrait::new(0) // initialize a hash state
.update_with(a) // takes first address
.update_with(b) // takes second address
.finalize(); // produce the digest
println!("Digest: {:?}", digest);
}
}
}
Poseidon का उपयोग करके एक struct को हैश करना
नीचे दिए गए कोड में, चूँकि MyStruct का उपयोग इंटरफ़ेस (interface) में पैरामीटर के रूप में किया जाता है, हम इसे contract मॉड्यूल के बाहर परिभाषित करते हैं ताकि इंटरफ़ेस और contract इम्प्लीमेंटेशन दोनों इसे एक्सेस कर सकें।
#[starknet::interface] में प्रदर्शित होने वाले किसी भी struct को अनिवार्य रूप से:
- contract मॉड्यूल के बाहर परिभाषित होना चाहिए
Serdeडिराइव करना चाहिए ताकि इसेfelt252s के अनुक्रम (sequence) में सीरियलाइज़ किया जा सके, और उनसे वापस डीसीरियलाइज़ किया जा सकेDropडिराइव करना चाहिए ताकि scope से बाहर जाने पर मान को सुरक्षित रूप से डिस्कार्ड किया जा सके
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_poseidon(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::poseidon::PoseidonTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_poseidon(self: @ContractState, my_struct: MyStruct) {
let digest = PoseidonTrait::new().update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
Pedersen का उपयोग करके एक struct को हैश करना
यह Pedersen के साथ भी उसी तरह काम करता है, बस इंपोर्ट को Pedersen hash function से और state को PedersenTrait::new(0) से बदलें और बाकी को अपरिवर्तित रखें:
// DEFINE OUR STRUCT
#[derive(Hash, Serde, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(self: @TContractState, my_struct: MyStruct);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{ HashStateTrait, HashStateExTrait };
use core::pedersen::PedersenTrait;
//*** IMPORT THE STRUCT WE DEFINED OUTSIDE THE CONTRACT ***//
use super::MyStruct;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, my_struct: MyStruct) {
let digest = PedersenTrait::new(0) // *** REPLACEMENT HERE *** //
.update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
यदि किसी struct का उपयोग केवल contract के भीतर आंतरिक रूप से किया जाता है और इंटरफ़ेस के माध्यम से एक्सपोज़ नहीं किया जाता है, तो उसे Serde डिराइव करने की आवश्यकता नहीं है।
नीचे contract के भीतर परिभाषित और उपयोग किए गए हैशेबल struct का एक उदाहरण दिया गया है:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_struct_pedersen(
self: @TContractState,
value1: u256,
value2: felt252
);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::{HashStateExTrait, HashStateTrait};
use core::pedersen::PedersenTrait;
// *** DEFINE STRUCT INSIDE THE CONTRACT *** //
#[derive(Hash, Drop)]
struct MyStruct {
a: u256,
b: felt252,
}
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_struct_pedersen(self: @ContractState, value1: u256, value2: felt252) {
// *** INITIALIZE THE STRUCT *** //
let my_struct = MyStruct { a: value1, b: value2 };
let digest = PedersenTrait::new(0).update_with(my_struct).finalize();
println!("Digest: {:?}", digest);
}
}
}
उदाहरण 3: Arrays को हैश करना
हम अन्य प्रकारों की तरह किसी ऐरे (array) को सीधे हैश नहीं कर सकते, क्योंकि ऐरे स्वयं Hash trait को इम्प्लीमेंट नहीं करता है। किसी ऐरे को हैश करने के लिए आपको प्रत्येक एलिमेंट के माध्यम से लूप (loop) करना होगा, आगे बढ़ते हुए hash state को अपडेट करना होगा, और फिर अंत में .finalize() को कॉल करना होगा।
Poseidon का उपयोग करके Array<felt252> को हैश करना:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::poseidon::PoseidonTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_poseidon(self: @ContractState, values: Array<felt252>) {
let mut state = PoseidonTrait::new(); // The hash state
let mut i = 0;
let len = values.len();
// The loop
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// Finalize the state
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
Cairo में एक अंतर्निहित (built-in) Poseidon हेल्पर है जो आंतरिक रूप से लूपिंग को संभालता है और स्वचालित रूप से state अपडेट्स को प्रबंधित करता है: poseidon_hash_span।
felt252 के ऐरे को हैश करने के लिए बिल्ट-इन Poseidon हेल्पर का उपयोग करना
poseidon_hash_span फंक्शन एक इनपुट के रूप में Span<felt252> लेता है, hash state बनाने के लिए प्रत्येक एलिमेंट के माध्यम से इटरेट (iterate) करता है, फिर फाइनलाइज़ करता है और एक सिंगल felt252 digest लौटाता है।
नीचे एक उदाहरण दिया गया है। मैनुअल Poseidon हैशिंग के विपरीत जहां हमें PoseidonTrait और HashStateTrait को इंपोर्ट करने की आवश्यकता होती है, poseidon_hash_span एक स्टैंडअलोन फंक्शन है जो सब कुछ आंतरिक रूप से संभालता है। हमें केवल इसे इंपोर्ट करने और उपयोग करने की आवश्यकता है:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_builtin_poseidon(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
// IMPORT `poseidon_hash_span`
use core::poseidon::poseidon_hash_span;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_builtin_poseidon(self: @ContractState, values: Array<felt252>) {
// Convert Array<felt252> to Span<felt252>
let span = values.span();
// USE `poseidon_hash_span`
let digest = poseidon_hash_span(span);
println!("Digest: {:?}", digest);
}
}
}
चूंकि poseidon_hash_span फंक्शन इनपुट के रूप में Span<felt252> लेता है, हम सबसे पहले अपने ऐरे को .span() का उपयोग करके span में परिवर्तित करते हैं, फिर इसे बिल्ट-इन फंक्शन में पास करते हैं, जो एक सिंगल felt252 digest लौटाता है।
यदि हम एक ही ऐरे को hash_array_manual_poseidon और hash_array_builtin_poseidon दोनों फंक्शन्स में पास करते हैं, तो वे एक समान (identical) Poseidon हैश उत्पन्न करेंगे, क्योंकि poseidon_hash_span आंतरिक रूप से केवल मैनुअल लूप ही करता है।
Pedersen का उपयोग करके Array<felt252> को हैश करना:
Pedersen के साथ felts के ऐरे को हैश करने के चरण Poseidon के समान हैं: आप मैन्युअल रूप से ऐरे के माध्यम से लूप करते हैं और प्रत्येक एलिमेंट को क्रमिक रूप से (sequentially) हैश करते हैं। हालाँकि, Pedersen के साथ arrays को हैश करते समय Starknet में एक कन्वेंशन (परंपरा/नियम) है कि ऐरे की लंबाई को अंतिम एलिमेंट के रूप में शामिल किया जाना चाहिए। यह पैटर्न पूरे Starknet इकोसिस्टम में लगातार अपनाया जाता है, जिसमें protocol implementation और starknet.js जैसी स्टैंडर्ड लाइब्रेरी शामिल हैं।
नीचे दिया गया hash_array_manual_pedersen फंक्शन इस पैटर्न को कार्य करते हुए दिखाता है। ऐरे के सभी एलिमेंट्स को हैश करने के बाद, हम hash state को फाइनलाइज़ करने से पहले अंतिम एलिमेंट के रूप में ऐरे की लंबाई को हैश करते हैं:
#[starknet::interface]
pub trait IHelloStarknet<TContractState> {
fn hash_array_manual_pedersen(self: @TContractState, values: Array<felt252>);
}
#[starknet::contract]
mod HelloStarknet {
use core::hash::HashStateTrait;
use core::pedersen::PedersenTrait;
#[storage]
struct Storage {}
#[abi(embed_v0)]
impl HelloStarknetImpl of super::IHelloStarknet<ContractState> {
fn hash_array_manual_pedersen(self: @ContractState, values: Array<felt252>) {
let mut state = PedersenTrait::new(0);
let mut i = 0;
let len = values.len();
while i != len {
state = state.update(*values.at(i));
i += 1;
}
// FOCUS HERE: Include the array length
state = state.update(len.into());
let digest = state.finalize();
println!("Digest: {:?}", digest);
}
}
}
मुख्य बातें (Takeaways):
- जब कस्टम लॉजिक की आवश्यकता हो (जैसे अन्य डेटा प्रकारों का मिश्रण या कंडीशनल अपडेट्स) तो मैनुअल लूप का उपयोग करें।
felt252ऐरे के Poseidon हैश की गणना करने के लिएposeidon_hash_spanका उपयोग करें। यह स्पष्ट (cleaner) है और इसमें कम कोड की आवश्यकता होती है।- Pedersen के साथ arrays को हैश करने का मानक (standard) पैटर्न hash state को फाइनलाइज़ करने से पहले ऐरे की लंबाई को अंतिम एलिमेंट के रूप में शामिल करना है।
Keccak256
Cairo का core::keccak मॉड्यूल चार फंक्शन्स प्रदान करता है:
compute_keccak_byte_array: एकByteArrayको हैश करता है।keccak_u256s_be_inputs: बिग-एंडियन (big-endian) फॉर्मेट में एन्कोड किए गएu256मानों के एक ऐरे को हैश करता है।keccak_u256s_le_inputs: लिटिल-एंडियन (little-endian) फॉर्मेट में एन्कोड किए गएu256मानों के एक ऐरे को हैश करता है।cairo_keccak: कस्टम पैडिंग के साथ बाइट अनुक्रम (byte sequence) को हैश करता है (Solidity केkeccak256(abi.encodePacked(val))के समतुल्य)।
ये सभी एक u256 लौटाते हैं जो Solidity के keccak256 द्वारा उत्पन्न समान 32-बाइट digest का प्रतिनिधित्व करता है। अंतर इस बात में है कि मान को कैसे दर्शाया जाता है: Solidity बिग-एंडियन फॉर्मेट में bytes32 के रूप में digest लौटाता है, जबकि Cairo इसे लिटिल-एंडियन u256 के रूप में लौटाता है।
उदाहरण के लिए, मान लीजिए कि किसी मान के Solidity के keccak हैश ने 0x1234...5678 उत्पन्न किया है। Cairo का keccak उसी digest को लिटिल-एंडियन u256 के रूप में दर्शाएगा, इसलिए इसका बाइट क्रम उलट (reversed) जाएगा: 0x7856...3412। हम अंतिम खंड में देखेंगे कि Cairo और Solidity के keccak के बीच मेल खाने वाले परिणाम कैसे प्राप्त करें।
Cairo के Keccak Functions और उनके Solidity समतुल्य
-
compute_keccak_byte_array→ एकByteArrayको हैश करता है।Solidity contract:
contract Example { function hashHello() external pure returns (bytes32) { return keccak256(abi.encodePacked("Hello RareSkills")); } }Cairo समतुल्य (Equivalent):
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash_hello(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::compute_keccak_byte_array; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash_hello(self: @ContractState) { // Perform the hash let digest = compute_keccak_byte_array(@"Hello RareSkills"); println!("Digest: {:?}", digest); } } } -
keccak_u256s_be_inputs→ बिग-एंडियन क्रम मेंu256मानों के एक ऐरे को हैश करता है, जो Solidity की डिफ़ॉल्ट एन्कोडिंग से मेल खाता है।Solidity contract:
contract Example { function hash() external pure returns (bytes32) { return keccak256(abi.encode(1,2)); } }Cairo समतुल्य (Equivalent):
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_be_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_be_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
keccak_u256s_le_inputs→ लिटिल-एंडियन क्रम मेंu256मानों के एक ऐरे को हैश करता है। Solidity हैशिंग से पहले इनपुट को मैन्युअल रूप से लिटिल-एंडियन में परिवर्तित करके इसे दोहरा (replicate) सकता है।Solidity contract:
contract Example { function hash() external pure returns (bytes32) { // Convert 1_u256 and 2_u256 to little endian uint256 one_le = 0x0100000000000000000000000000000000000000000000000000000000000000; uint256 two_le = 0x0200000000000000000000000000000000000000000000000000000000000000; return keccak256(abi.encode(one_le,two_le)); } }Cairo समतुल्य (Equivalent):
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::keccak_u256s_le_inputs; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { // Perform the hash let digest = keccak_u256s_le_inputs([1, 2].span()); println!("Digest: {:?}", digest); } } } -
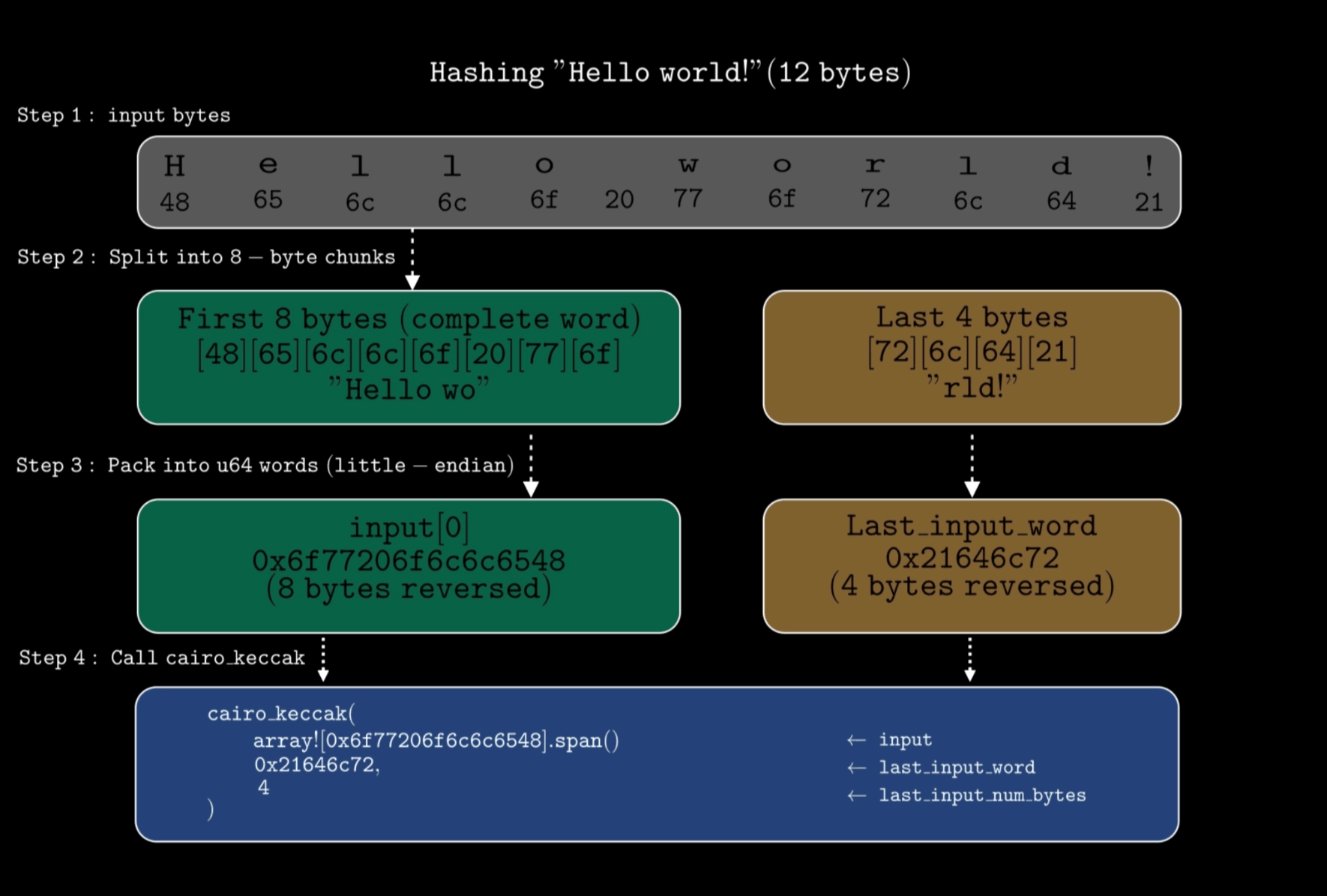
cairo_keccak→ यह तीन आर्ग्यूमेंट्स (arguments) लेता है:input- लिटिल-एंडियन फॉर्मेट में पूर्ण 64-बिट वर्ड्स का ऐरेlast_input_word-inputसे शेष बचे बाइट्स जो 8-बाइट के पूर्ण वर्ड को नहीं भरते हैं। उदाहरण के लिए, यदि आप कुल 12 बाइट्स को हैश कर रहे हैं, तो पहले 8 बाइट्सinputमें एक पूर्ण वर्ड के रूप में जाते हैं, और अंतिम 4 बाइट्सlast_input_wordमें जाते हैं। यदि आपका इनपुट 8 से पूरी तरह से विभाज्य (divisible) है (उदा., 8, 16, या 32 बाइट्स), तोlast_input_word,0होता है।last_input_num_bytes-last_input_wordमें बाइट्स की संख्या।0और7के बीच (0 और 7 सहित) एक इंटीजर (integer) होना चाहिए।
नीचे दिया गया आरेख (diagram) दिखाता है कि ये पैरामीटर्स एक साथ कैसे काम करते हैं:
उदाहरण 1 – उस डेटा को हैश करना जो u64 या 8bytes का गुणज (multiple) है
Solidity contract:
contract Example { function hash() external pure returns (bytes32) { uint64 one = 1; // 0x0000000000000001 return keccak256(abi.encodePacked(one)); } }Cairo समतुल्य (Equivalent):
#[starknet::interface] pub trait IHelloStarknet<TContractState> { fn hash(self: @TContractState); } #[starknet::contract] mod HelloStarknet { // IMPORTS use core::keccak::cairo_keccak; #[storage] struct Storage {} #[abi(embed_v0)] impl HelloStarknetImpl of super::IHelloStarknet<ContractState> { fn hash(self: @ContractState) { let mut input = array![0x0100000000000000]; // 1_u64 as little-endian let digest = cairo_keccak(ref input, 0, 0); // no extra bytes println!("Digest: {:?}", digest); } } }cairo_keccakके अंतिम दो आर्ग्यूमेंट्स;last_input_wordऔरlast_input_num_bytes0 हैं क्योंकि हमारे पास हैश करने के लिए अतिरिक्त बाइट्स नहीं हैं।उदाहरण 2 – उस डेटा को हैश करना जो u64 या 8bytes का गुणज (multiple) नहीं है
मान लीजिए कि हम
0x48656c6c6f20776f726c6421को हैश करना चाहते हैं जो “Hello world!” (12 बाइट्स) का प्रतिनिधित्व करता है। चूँकि 12, 8 से विभाज्य नहीं है, इसलिए हमेंlast_input_wordपैरामीटर का उपयोग करने की आवश्यकता होगी।Solidity contract:
contract Example { function hash() external pure returns (bytes32) { bytes12 input = 0x48656c6c6f20776f726c6421; return keccak256(abi.encodePacked(input)); } }Cairo समतुल्य (Equivalent):
fn hash(self: @ContractState) { // bytes to hash - 0x48656c6c6f20776f726c6421 (12 bytes) // first 8 bytes (48656c6c6f20776f), reversed to little-endian let mut input = array![0x6f77206f6c6c6548]; // Perform the hash // the remaining 4 bytes (726c6421) to little-endian - 0x21646c72 let digest = cairo_keccak(ref input, 0x21646c72, 4); println!("Digest: {:?}", digest); }यहाँ:
0x6f77206f6c6c6548उलटे (reversed) गए पहले 8 बाइट्स हैं।0x21646c72उलटे गए शेष 4 बाइट्स हैं।4उन शेष बाइट्स की संख्या को इंगित करता है।
ये उदाहरण दिखाते हैं कि Cairo के Keccak फंक्शन्स Solidity के keccak256 के साथ कैसे मेल खाते हैं, लेकिन उनके आउटपुट बाइट क्रम (byte order) में भिन्न होते हैं। Cairo एक लिटिल-एंडियन u256 लौटाता है, जबकि Solidity एक बिग-एंडियन bytes32 उत्पन्न करता है। Solidity हैश से तुलना करने से पहले Cairo के परिणाम के बाइट क्रम को उलट दें।
लिटिल-एंडियन को बिग-एंडियन में बदलना और इसके विपरीत
नीचे दिया गया एनीमेशन लिटिल-एंडियन से बिग-एंडियन में बाइट्स रूपांतरण (conversion) दिखाता है:
Cairo में भी ऐसा करने के लिए, हम प्रत्येक 128-बिट वाले आधे हिस्से (half) को उलट कर और उनके स्थानों को स्वैप (swap) करके एक u256 मान के बाइट क्रम को उलट देते हैं। बाइट्स को उलटने के लिए Cairo अपने core::integer मॉड्यूल से एक बिल्ट-इन फंक्शन u128_byte_reverse प्रदान करता है।
निम्नलिखित कोड उदाहरण दिखाता है कि कैसे एक u256 मान को लिटिल-एंडियन से बिग-एंडियन प्रतिनिधित्व (और इसके विपरीत) में इसके बाइट क्रम को उलट कर बदला जाए:
fn u256_reverse_bytes(x: u256) -> u256 {
u256 {
// Take the high 128 bits, reverse their byte order, put in low position
low: core::integer::u128_byte_reverse(x.high),
// Take the low 128 bits, reverse their byte order, put in high position
high: core::integer::u128_byte_reverse(x.low),
}
}
चूंकि Cairo में u256 दो u128 मानों (low और high) से बना है, 256-बिट इंटीजर के बाइट क्रम को उलटने के लिए निम्नलिखित की आवश्यकता होती है:
- प्रत्येक 128-बिट वाले आधे हिस्से (half) के भीतर बाइट क्रम को उलटना।
- दोनों हिस्सों (halves) को स्वैप करना।
core::integer::u128_byte_reverse फंक्शन प्रत्येक u128 के लिए बाइट-लेवल को उलटता (reversal) है। इसे दोनों हिस्सों पर लागू करके और उनके स्थानों को स्वैप करके, हम पूरे 256-बिट मान के बाइट क्रम को उलट देते हैं।
चूँकि बाइट रिवर्सल (byte reversal) सममित (symmetric) है, इसी फंक्शन का उपयोग निम्न को परिवर्तित करने के लिए किया जा सकता है:
- लिटिल-एंडियन → बिग-एंडियन
- बिग-एंडियन → लिटिल-एंडियन
इसे दो बार लागू करने पर मूल मान (original value) वापस आ जाता है।