यह ट्यूटोरियल Solana BPF (sBPF) मेमोरी लेआउट और इसके वर्चुअल मशीन रजिस्टर्स की भूमिकाओं का परिचय देता है। हम यह प्रदर्शित करेंगे कि sBPF VM के भीतर प्रोग्राम्स मेमोरी से रजिस्टर्स में डेटा कैसे पढ़ते और लिखते हैं, इसके क्या conventions हैं।
Solana BPF मेमोरी लेआउट
sBPF VM की मेमोरी को 5 अलग-अलग रीजन्स (regions) में विभाजित किया गया है। इन पांचों रीजन्स में से प्रत्येक का एक विशिष्ट उद्देश्य है। इन रीजन्स के बाहर मेमोरी को एक्सेस करने का कोई भी प्रयास, या किसी रीजन की परमिशन का उल्लंघन करना जैसे रीड-ओनली डेटा पर लिखना, एक एक्सेस-वॉयलेशन एरर (access-violation error) को ट्रिगर करता है। हम इसे आगे दिखाएंगे।
प्रत्येक रीजन का वर्णन करने से पहले, हम इस बात पर जोर देना चाहते हैं कि जहाँ EVM अपना बाइटकोड सीधे कॉन्ट्रैक्ट कोड से पढ़ता है, वहीं SVM अपने बाइटकोड को रन करने से पहले मेमोरी में लोड करता है।
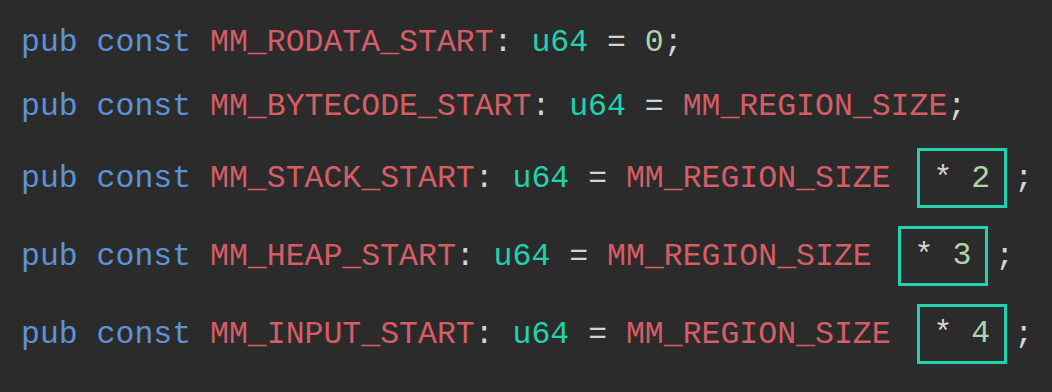
नीचे दिए गए एड्रेस प्रत्येक मेमोरी रीजन की शुरुआत हैं और इन्हें Solana source code में u64 स्थिरांक (constants) के रूप में परिभाषित किया गया है। MM_BYTECODE_START, MM_RODATA_START जैसे नाम, प्रत्येक रीजन के शुरुआती एड्रेस की Rust constants परिभाषाएँ हैं। यहाँ MM का अर्थ “memory map” है जबकि RO का अर्थ “read-only” है। Solana रीजन्स के बीच एड्रेस कॉलिजन (address collision) को रोकने के लिए इनमें से प्रत्येक मेमोरी रीजन के लिए 4GiB रिज़र्व करता है, लेकिन वास्तव में प्रत्येक रीजन को जितनी आवश्यकता होती है उतना ही साइज़ आवंटित करता है।
0x000000000:MM_RODATA_START— रीड-ओनली ELF डेटा (constants, static data) के लिए 4 GiB0x100000000:MM_BYTECODE_START— प्रोग्राम बाइटकोड रीजन के लिए 4 GiB0x200000000:MM_STACK_START— एग्जीक्यूशन स्टैक के लिए 4 GiB0x300000000:MM_HEAP_START— हीप (heap) मेमोरी रीजन के लिए 4 GiB रिज़र्व्ड0x400000000:MM_INPUT_START— वर्तमान ट्रांज़ैक्शन में सीरियलाइज़्ड इनपुट डेटा (program id, accounts, और instruction data) के लिए 4 GiB। इसे प्रोग्राम की शुरुआत में रनटाइम द्वारा पॉप्युलेट किया जाता है।
Solana BPF मेमोरी लेआउट को नीचे दिखाए गए चित्र के अनुसार विज़ुअलाइज़ किया जा सकता है:

Solana क्लाइंट नीचे दिए गए स्निपेट के अनुसार constants को परिभाषित करता है:
pub const MM_RODATA_START: u64 = 0;
pub const MM_BYTECODE_START: u64 = MM_REGION_SIZE; // = MM_REGION_SIZE * 1
pub const MM_STACK_START: u64 = MM_REGION_SIZE * 2;
pub const MM_HEAP_START: u64 = MM_REGION_SIZE * 3;
pub const MM_INPUT_START: u64 = MM_REGION_SIZE * 4;
MM_REGION_SIZE एक वर्चुअल मेमोरी ब्लॉक के साइज़ को परिभाषित करता है, जिसकी गणना 1 << VIRTUAL_ADDRESS_BITS के रूप में की जाती है। sBPF source code में VIRTUAL_ADDRESS_BITS को 32 के रूप में परिभाषित किया गया है, इसका मतलब है कि प्रत्येक रीजन के भीतर, 2^32 अलग-अलग बाइट एड्रेस हैं, जो प्रत्येक रीजन को 4GiB का एड्रेसेबल स्पेस देते हैं।
मल्टीप्लायर्स (* 2, * 3, * 4) प्रत्येक रीजन के शुरुआती एड्रेस को MM_REGION_SIZE के गुणकों (multiples) से आगे बढ़ाते हैं।
मेमोरी में डेटा का उपयोग करने के लिए, हमें पहले इसे एक रजिस्टर में लोड करना होगा। VM प्रत्येक रजिस्टर को एक विशिष्ट भूमिका (role) सौंपता है, जिसका डेवलपर्स से कन्वेंशन के अनुसार पालन करने की अपेक्षा की जाती है। अगला सेक्शन न्यूनतम उदाहरणों के साथ इन भूमिकाओं का वर्णन करता है।
Solana BPF VM रजिस्टर्स को भूमिकाएँ कैसे सौंपता है
sBPF VM में 12 registers होते हैं, जिन्हें r0 से r11 तक नाम दिया गया है। रजिस्टर्स r0–r10 प्रोग्राम्स के लिए एक्सपोज़ किए गए हैं, जबकि r11 प्रोग्राम काउंटर रखता है और यह Solana प्रोग्राम्स द्वारा न तो पढ़ने योग्य (readable) है और न ही लिखने योग्य (writable) है।
r0 रिटर्न वैल्यूज़ रखता है, r1–r5 आर्गुमेंट रजिस्टर्स हैं, r6–r9 जनरल-परपज़ स्क्रैच रजिस्टर्स हैं जिन्हें callee-saved रजिस्टर्स के रूप में भी जाना जाता है (कॉल्स के दौरान अस्थायी वैल्यूज़ को स्टोर करने के लिए उपयोग किया जाता है), और r10 वर्तमान कॉल स्टैक के लिए फ्रेम पॉइंटर रजिस्टर है।

प्रत्येक रजिस्टर की जांच करने से पहले, आइए यह देखने के लिए एक वातावरण (environment) सेट करें कि एग्जीक्यूशन के दौरान रजिस्टर की वैल्यूज़ कैसे बदलती हैं।
रजिस्टर एक्सपेरिमेंट सेटअप
एक नया फोल्डर बनाएँ जिसका नाम register-experiment हो। इस फोल्डर के अंदर एक टर्मिनल खोलें और solana-test-validator कमांड रन करें। यह एक लोकल Solana क्लस्टर शुरू करेगा और register-experiment के अंदर एक test-ledger डायरेक्टरी बनाएगा।
एक बार जब लोकल वैलिडेटर रन हो जाए:
register-experimentडायरेक्टरी मेंsrcनामक एक फोल्डर बनाएँ। यह फोल्डर हमारे असेंबली प्रोग्राम और एक ट्रेस फ़ाइल को रखेगा जो यह दिखाती है कि प्रत्येक इंस्ट्रक्शन के एग्जीक्यूट होने के बाद रजिस्टर की स्थिति कैसे बदलती है।- हमारे असेंबली कोड के लिए एक
src/inputs.asmफ़ाइल बनाएँ।
आपकी डायरेक्टरी इस तरह दिखनी चाहिए:
register-experiment
├── src
└── inputs.asm
हम अपने असेंबली कोड को रन करने और रजिस्टर ट्रेसेज़ बनाने के लिए agave-ledger-tool (जो आपके Solana इंस्टॉलेशन के साथ आता है) का उपयोग करेंगे।
निम्नलिखित उदाहरणों को रन करने के लिए नीचे दिए गए कमांड का उपयोग करें। यह हमारे लोकल टेस्ट लेजर के विरुद्ध चलता है, असेंबली प्रोग्राम को 200,000 कंप्यूट-यूनिट लिमिट के साथ एग्जीक्यूट करता है, और एक ट्रेस फ़ाइल उत्पन्न करता है जो दिखाती है कि एग्जीक्यूशन के दौरान रजिस्टर की वैल्यूज़ कैसे बदलती हैं।
agave-ledger-tool program run src/inputs.asm --limit 200000 --trace src/trace.txt --ledger test-ledger
नोट: कुछ आर्किटेक्चर पर, जैसे कि Apple Silicon, इस कमांड को रन करने पर JitNotCompiled एरर ट्रिगर हो सकता है। इसे हल करने के लिए, JIT कंपाइलेशन के बजाय इंटरप्रिटेशन (interpretation) को बाध्य (force) करने के लिए --mode interpreter फ़्लैग जोड़ें।
चूंकि अब हमारा सेटअप पूरा हो गया है, हम प्रदर्शित करेंगे कि एग्जीक्यूशन के दौरान r0 से लेकर r11 तक के प्रत्येक रजिस्टर का उपयोग कैसे किया जाता है। हमारे प्रदर्शन उनके व्यवहार को अलग (isolate) करने के लिए रजिस्टर्स में वैल्यूज़ को हार्डकोड करते हैं। हम अगले लेख में दिखाएंगे कि मेमोरी से कैसे पढ़ें और रजिस्टर्स में वैल्यूज़ कैसे लोड करें।
रजिस्टर r0
प्रोग्राम्स r0 में लिखकर रनटाइम को सफलता या विफलता की सूचना देते हैं। जब एग्जीक्यूशन पूरा हो जाता है तो VM इस वैल्यू को पढ़ता है। संभावित परिणाम इस प्रकार हैं:
- एक सफल एग्जीक्यूशन
0रिटर्न करता है। - एक कंट्रोल्ड एरर एक नॉन-ज़ीरो एरर कोड रिटर्न करता है (हम कस्टम एरर कोड लिखते हैं)।
- यदि पैनिक (panic) होता है, तो प्रोग्राम exit इंस्ट्रक्शन तक पहुँचने से पहले ही समाप्त हो जाता है, इसलिए रनटाइम
r0को नज़रअंदाज़ (ignore) कर देता है।
आइए प्रदर्शित करें कि प्रोग्राम ऊपर सूचीबद्ध तीन संभावित परिणामों के आधार पर r0 का उपयोग करके सफलता या विफलता कैसे संप्रेषित करते हैं।
1/3 एक उदाहरण जो दिखाता है कि सफल एग्जीक्यूशन 0 रिटर्न करता है
src/inputs.asm में एक सरल exit इंस्ट्रक्शन लिखें:
exit
इसे agave-ledger-tool कमांड के साथ रन करें, आपको 0 रिटर्न करते हुए एक सफल exit मिलेगा:
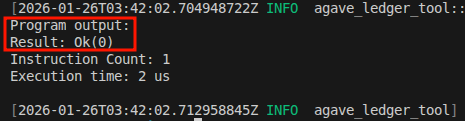
निम्नलिखित ट्रेस trace.txt में बनाया जाएगा जो दर्शाता है कि r0 0000000000000000 है (ट्रेस में पहला कॉलम r0 है, दूसरा r1 है …):
Frame 0
0 [0000000000000000, 0000000400000000, ...] 0: exit
उपरोक्त प्रदर्शन से पता चलता है कि यदि कोई फ़ंक्शन सफलतापूर्वक रिटर्न करता है तो r0 में 0 होता है।
2/3 एक उदाहरण जो यह दर्शाता है कि एक कंट्रोल्ड विफलता एक नॉन-ज़ीरो वैल्यू रिटर्न करती है।
हम कंट्रोल्ड विफलता के मामले में r0 में लिख सकते हैं। यदि हम किसी कारण से 600 (0x0000000000000258) जैसा कस्टम एरर कोड रिटर्न करना चाहते हैं, तो प्रोग्राम अभी भी स्पष्ट रूप से बाहर निकलता है (exits cleanly), लेकिन r0 ज़ीरो के बजाय एरर कोड रखता है:
mov r0, 600 ; Set custom error code
exit
असेंबली कोड उदाहरणों में कमेंट्स को सीधे कॉपी करने पर पार्स एरर (parse error) आ सकता है, क्योंकि यदि कमेंट्स मौजूद हों तो agave-ledger-tool एरर फेंकता है। यदि ऐसा होता है तो ; Set custom error code कमेंट हटा दें।
agave-ledger-tool का उपयोग करके उपरोक्त कोड चलाएँ, आपको यह आउटपुट मिलेगा:
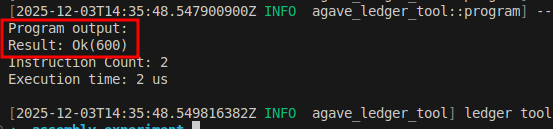
ट्रेस दिखाता है कि r0 0 से शुरू हुआ था और इसकी वर्तमान स्थिति हेक्स में 0000000000000258 है जो डेसिमल में 600 है:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: lddw r0, 0x258
1 [0000000000000258, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: exit
3/3 एक उदाहरण जो यह दर्शाता है कि पैनिक या ट्रैप एग्जीक्यूशन को समाप्त कर देता है और r0 में नहीं लिखता है
एक पैनिक या ट्रैप एग्जीक्यूशन को समाप्त कर देता है और इसे अनरिकवरेबल (unrecoverable) माना जाता है। यह परिणाम को r0 में स्टोर नहीं करता है, इसलिए वहां पहले से स्टोर की गई किसी भी वैल्यू को नज़रअंदाज़ कर दिया जाता है।
नीचे दिया गया कोड रीड-ओनली मेमोरी रीजन में 42 लिखने के प्रयास को प्रदर्शित करता है।
lddw r1, 0x000000000 ;Load MM_RODATA_START address into r1
stdw [r1 + 0], 42 ;Attempt to store 42 into the MM_RODATA_START
exit
उपरोक्त कोड में:
lddwएक रजिस्टर में 64-बिट इमीडिएट (immediate) वैल्यू लोड करता है। हम इसका उपयोग रीड-ओनली रीजन के शुरुआती एड्रेस (0x000000000) कोr1में लोड करने के लिए करते हैं।stdw64-बिट इमीडिएट वैल्यू को सीधे मेमोरी में स्टोर करता है। हम इस इंस्ट्रक्शन का उपयोग करके रीड-ओनली मेमोरी रीजन में 42 लिखने का प्रयास करते हैं, जो इसे रन करने पर एक एक्सेस वॉयलेशन एरर ट्रिगर करता है।

ट्रेस में, आप देखेंगे कि ट्रेस लाइन 1 (stxdw लाइन) पर समाप्त होता है क्योंकि हम एक अमान्य मेमोरी ऑपरेशन का प्रयास कर रहे हैं, जिसके कारण यह ट्रैप हो गया। प्रोग्राम कभी भी exit इंस्ट्रक्शन तक नहीं पहुंचा।
Frame 0
0 [0000000000000000, 0000000400000000, ...] 0: lddw r1, 0x100000000
1 [0000000000000000, 0000000100000000, ...] 2: stxdw [r1+0x0], r2
अब तक, हमने कवर किया है कि r0 विभिन्न परिदृश्यों में कैसे व्यवहार करता है और VM इसका उपयोग कैसे करता है। Rust लेयर पर, रिटर्न वैल्यू Ok(u64) या Err(...) के रूप में दिखाई देती है, लेकिन VM में यह केवल एक एकल u64 स्टेटस कोड है जिसे r0 में स्टोर किया जाता है और पढ़ा जाता है।
नीचे दी गई तालिका दिखाती है कि प्रत्येक परिदृश्य में क्या होता है और उस परिदृश्य में r0 में क्या वैल्यू होती है:
| स्थिति | क्या होता है | r0 में वैल्यू |
|---|---|---|
| नॉर्मल रिटर्न | प्रोग्राम समाप्त होता है और लोडर पर वापस लौटता है | 0 |
| कंट्रोल्ड एरर (Anchor या मैनुअल एरर हैंडलिंग) | प्रोग्राम एक एरर कोड सेट करता है, और रिटर्न करता है | नॉन-ज़ीरो एरर कोड (जैसे; 2, 600, 1, 5, आदि) |
| असर्शन फेल्योर या एबॉर्ट | प्रोग्राम समाप्त हो जाता है | r0 को नज़रअंदाज़ कर दिया जाता है क्योंकि प्रोग्राम exit इंस्ट्रक्शन तक नहीं पहुँचता है |
रजिस्टर r1
प्रोग्राम की शुरुआत में, r1 में MM_INPUT_START (0x400000000) होता है, जो मेमोरी में सीरियलाइज़्ड इनपुट पैरामीटर्स की शुरुआत को पॉइंट करता है।
मान लीजिए कि हमारे पास एक फ़ंक्शन है जो दो आर्गुमेंट्स, a और b लेता है:
fn add_constant(a: u64, b: u64)
जब प्रोग्राम एग्जीक्यूशन शुरू करता है, तो रनटाइम a और b की सीरियलाइज़्ड वैल्यूज़ को मेमोरी लोकेशन MM_INPUT_START में स्टोर करता है। इस स्तर पर, रजिस्टर r1, MM_INPUT_START को पॉइंट करता है (अर्थात, r1 में MM_INPUT_START का एड्रेस होता है)।
एग्जीक्यूशन के दौरान, r1 की भूमिका एक आर्गुमेंट रजिस्टर में बदल जाती है और इसके कंटेंट को प्रोग्राम द्वारा ओवरराइट (overwrite) किया जा सकता है।
रजिस्टर्स r1-r5
यदि आपके प्रोग्राम के फ़ंक्शंस को एग्जीक्यूशन के दौरान आर्गुमेंट्स की आवश्यकता होती है, तो रनटाइम अपेक्षा करता है कि आपका प्रोग्राम उन आर्गुमेंट्स को r1 से लेकर r5 तक में स्टोर करे। यदि किसी फ़ंक्शन को पांच से अधिक आर्गुमेंट्स की आवश्यकता है, तो आपको अतिरिक्त वैल्यूज़ को स्टैक पर स्टोर करना होगा और इन रजिस्टर्स में से किसी एक का उपयोग करके उनके लिए एक पॉइंटर पास करना होगा।
जब कोई फ़ंक्शन रिटर्न करता है, तो आर्गुमेंट रजिस्टर्स में मौजूद वैल्यूज़ को डर्टी (dirty) माना जाता है। अगला फ़ंक्शन जो एग्जीक्यूट होता है वह स्वतंत्र रूप से r1–r5 को ओवरराइट कर सकता है।
आइए एक add_numbers फ़ंक्शन को कॉल करके आर्गुमेंट पासिंग को प्रदर्शित करें जो दो आर्गुमेंट्स लेता है।
fn add_numbers(a: u64, b: u64) -> u64 {
a + b
}
सरलता के लिए, हम मैन्युअली उपरोक्त कोड का sBPF असेंबली में अनुवाद करते हैं और कंपाइलर को बायपास करते हैं। स्निपेट नीचे दिखाया गया है। आइए पहले आर्गुमेंट के रूप में 10 और दूसरे के रूप में 25 पास करें, उन्हें फ़ंक्शन बॉडी में जोड़ें, और परिणाम को r0 में रिटर्न करें:
mov r1, 10 ; Simulate passing a=10 as first argument
mov r2, 25 ; Simulate passing b=25 as second argument
add64 r1, r2 ; Function body: add first and second argument
mov r3, r1 ; Copy the result to r3
exit ; exit successfuly with 0 in r0
agave-ledger-tool रन करें और trace.txt फ़ाइल चेक करें। आप देखेंगे कि परिणाम 23 (डेसिमल में 35) है:

अगले रजिस्टर्स r6-r9 हैं, लेकिन वे r10 (स्टैक पॉइंटर) पर निर्भर करते हैं। आइए पहले r10 की व्याख्या करें, फिर r6-r9 पर लौटें।
स्टैक पॉइंटर रजिस्टर (r10)
r10 स्टैक फ्रेम पॉइंटर है। यह एक वर्चुअल एड्रेस रखता है जो वर्तमान स्टैक रीजन को पॉइंट करता है।
जब आपका प्रोग्राम शुरू होता है, तो रनटाइम r10 को MM_STACK_START + stack_frame_size पर इनिशियलाइज़ करता है, जहाँ MM_STACK_START 0x200000000 है जबकि stack_frame_size = 4096 (हेक्स में 1000) बाइट्स (4KiB) है — ट्रेसेज़ में, आप r10 को 0x200001000 के रूप में इनिशियलाइज़ होता देखेंगे। यह r10 को आपके स्टैक फ्रेम के शीर्ष (top) पर रखता है और इसके नीचे 4096 बाइट्स का प्रयोग करने योग्य स्पेस होता है।
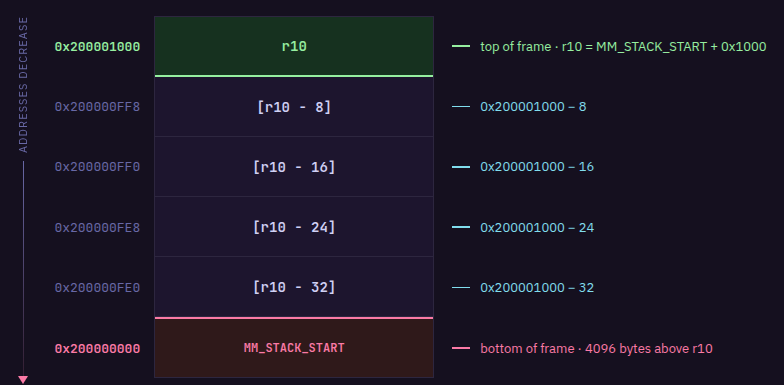
स्टैक नीचे की ओर बढ़ता है (grows downward), जिसका अर्थ है कि आप स्टैक स्पेस को क्रमशः कम (lower) मेमोरी एड्रेस पर आवंटित करते हैं। चूँकि r10 = MM_STACK_START + stack_frame_size, किसी भी स्टैक लोकेशन से पढ़ने या लिखने के लिए इस सूत्र का पालन किया जाता है:
[r10 - offset] = MM_STACK_START + stack_frame_size - offset
जहाँ offset खपत किए गए स्टैक स्पेस के बाइट्स की संख्या है। इसका मतलब है कि [r10 - 8] रिज़ॉल्व होकर MM_STACK_START + stack_frame_size - 8 हो जाता है, आप उस स्थान को रेफर कर रहे हैं जो r10 द्वारा पॉइंट किए गए स्थान से 8 बाइट्स नीचे है।
इसलिए जैसे-जैसे आपका प्रोग्राम एग्जीक्यूट होता है r10 की वैल्यू कभी नहीं बदलती है। अधिक स्टैक स्पेस का उपयोग करने के लिए, आप बस बड़े ऑफसेट्स का उपयोग करते हैं जैसे कि [r10 - 16], [r10 - 24], और इसी तरह। प्रत्येक फ़ंक्शन कॉल 4KiB (4096 बाइट्स) के उपयोग योग्य स्पेस तक सीमित है।
मान लीजिए आपको स्टैक पर मौजूद डेटा को किसी फ़ंक्शन में पास करना है। आप r10 से कुछ नेगेटिव ऑफसेट पर स्टैक फ्रेम में एक स्थान चुनते हैं, वहां अपना डेटा लिखते हैं, फिर कॉल करने से पहले उस स्थान का एड्रेस (उदाहरण के लिए, r10 - 8) किसी एक आर्गुमेंट रजिस्टर (r1 से r5) में रख देते हैं।
उदाहरण के लिए, यदि आपको पहले आर्गुमेंट के रूप में 64-बाइट बफर की आवश्यकता है:
- आप डेटा को मेमोरी रीजन
[r10 - 64]से[r10 - 1]में स्टोर कर सकते हैं - आप शुरुआती एड्रेस
r10 - 64कोr1में मूव करते हैं

- फिर आप अपना फ़ंक्शन कॉल करते हैं
हम प्रदर्शित करेंगे कि जब हम “Registers 6-9” कवर करेंगे तो r10 स्टैक पॉइंटर का उपयोग कैसे करें।
r10 पर लिखने के प्रतिबंध (Write restrictions)
आप r10 रजिस्टर में लिख नहीं सकते। mov के साथ r10 में लिखने पर एरर आता है:
mov r10, 999 # Error: cannot write to r10
exit

add r10, -64 के साथ r10 में लिखने का प्रयास करने से कोई एरर नहीं आता है, लेकिन VM चुपचाप इसे नज़रअंदाज़ कर देता है और इस इंस्ट्रक्शन को 64-बिट बिटवाइज़ OR इंस्ट्रक्शन (or64 r0, 0) में फिर से लिख देता है जो कुछ नहीं करता है:
add r10, -64
exit
यदि हम उपरोक्त कोड चलाते हैं और ट्रेस फ़ाइल देखते हैं, तो हम देखेंगे कि r10 अपरिवर्तित रहता है:

Callee-saved रजिस्टर्स (r6-r9)
Solana BPF में, रजिस्टर्स r6-r9 ‘callee-saved’ (जिन्हें ‘preserved’ भी कहा जाता है) होते हैं। इसका मतलब है कि यदि कोई फ़ंक्शन (callee) इन रजिस्टर्स को संशोधित करता है, तो उसे कॉलर पर लौटने से पहले उन्हें उनकी मूल वैल्यूज़ पर रीस्टोर करना होगा।
उदाहरण के लिए, यदि फ़ंक्शन A r6 में एक वैल्यू स्टोर करता है और फ़ंक्शन B को कॉल करता है, और फ़ंक्शन B अपने स्वयं के कंप्यूटेशन के लिए r6 का उपयोग करना चाहता है, तो फ़ंक्शन B को इसका उपयोग करने से पहले r6 में जो कुछ भी था उसे रिज़र्व (preserve) करना होगा। फ़ंक्शन B ऐसा r6 को स्टैक में कॉपी करके, अपने स्वयं के कंप्यूटेशन के लिए r6 का उपयोग करके, फिर लौटने से पहले स्टैक से मूल वैल्यू को वापस r6 में कॉपी करके करता है। जब फ़ंक्शन B बाहर निकलता है, तब भी फ़ंक्शन A के पास r6 में उसकी मूल वैल्यू बरकरार रहती है।
नीचे दिया गया कोड दो फ़ंक्शंस के बीच डेटा प्रिजर्वेशन कन्वेंशन (data preservation convention) को प्रदर्शित करता है:
- फ़ंक्शन A (CALLER)
r6में 999 स्टोर करता है - फ़ंक्शन A फ़ंक्शन B (
function_b) को कॉल करता है, यह अपेक्षा करते हुए किr6प्रिजर्व्ड रहेगा - फ़ंक्शन B
r6(999) को[r10 - 8]पर स्टैक में कॉपी करता है - फ़ंक्शन B अपने स्वयं के कंप्यूटेशन के लिए
r6का उपयोग करता है: 42 लोड करता है और 10 जोड़ता है (परिणाम 52) - फ़ंक्शन B लौटने से पहले स्टैक से
r6को वापस 999 पर रीस्टोर करता है - जब फ़ंक्शन B बाहर निकलता है, तब भी फ़ंक्शन A के पास
r6में 999 होता है - फ़ंक्शन A प्रिजर्व्ड वैल्यू का उपयोग करने के लिए
r6कोr2में मूव करता है
; === Function A: CALLER ===
mov r6, 999 ; Store value we want preserved across call
call function_b ; function_b MUST preserve r6 per convention
mov r2, r6 ; r6 still contains 999 (preserved by callee)
exit
; === Function B: CALLEE ===
function_b:
; Save callee-saved registers we'll modify
stxdw [r10 - 8], r6 ; copy caller's r6 value to stack
; FUNCTION BODY: We can freely use r6 now
mov r6, 42 ; Temporary use of r6
add64 r6, 10 ; r6 = 52 (will be discarded)
; Restore callee-saved registers
ldxdw r6, [r10 - 8] ; Restore original r6 value (999)
exit
नीचे दिया गया एनिमेशन इन चरणों को स्पष्ट करता है:
उपरोक्त कोड को रन करने पर नीचे दिया गया ट्रेस उत्पन्न होता है:
Frame 0
0 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 0000000000000000, ..., ..., ..., 0000000200001000] 0: mov64 r6, 999
1 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 1: call function_b
2 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 4: stxdw [r10-0x8], r6
3 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 5: mov64 r6, 42
4 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 000000000000002A, ..., ..., ..., 0000000200003000] 6: add64 r6, 10
5 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 0000000000000034, ..., ..., ..., 0000000200003000] 7: ldxdw r6, [r10-0x8]
6 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 8: exit
7 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 2: mov64 r2, r6
8 [..., 0000000400000000, 00000000000003E7, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 3: exit
ट्रेस से प्रमुख अवलोकन (Key observations):
- लाइन 1: कॉल से पहले
r6में0x3E7(999) होता है - लाइन 2:
callइंस्ट्रक्शनfunction_bमें ट्रांज़िशन करता है और0x200003000पर एक नए स्टैक फ्रेम को पॉइंट करने के लिएr10को अपडेट करता है - लाइन 4:
mov64 r6, 42के बाद,r6में0x2A(42) होता है - लाइन 5:
add64 r6, 10के बाद,r6में0x34(52) होता है - लाइन 6:
ldxdw r6, [r10-0x8]के बाद,r6को0x3E7(999) पर रीस्टोर कर दिया जाता है - लाइन 7: कॉलर पर लौटने के बाद,
r10वापस0x200001000हो जाता है औरr6में अभी भी0x3E7(999) होता है - लाइन 8:
mov64 r2, r6के बाद,r2औरr6दोनों में0x3E7(999) होता है
नीचे दिया गया एनिमेशन उपरोक्त चरणों की व्याख्या करता है:
इस लेख के अगले भाग में, हम सरल रॉ (raw) असेंबली प्रोग्राम्स लिखकर मेमोरी में इंस्ट्रक्शन इनपुट्स को पढ़ना और लिखना प्रदर्शित करेंगे जो सीधे मेमोरी कंटेंट्स का निरीक्षण करते हैं।
यह लेख Solana development पर एक ट्यूटोरियल सीरीज़ का हिस्सा है