本教程介绍了 Solana BPF (sBPF) 的内存布局及其虚拟机寄存器的作用。我们将演示程序在 sBPF VM 中如何将数据从内存读取和写入寄存器的约定。
Solana BPF 内存布局
sBPF VM 的内存被划分为 5 个不同的区域。这五个区域各自具有特定的用途。任何试图访问这些区域之外的内存,或违反区域权限(例如向只读数据区写入)的行为,都会触发访问冲突(access-violation)错误。我们稍后将展示这一点。
在描述每个区域之前,我们要强调的是:虽然 EVM 直接从合约代码中读取其字节码,但 SVM 在运行之前会将其字节码加载到内存中。
以下地址是每个内存区域的起始位置,并在 Solana source code 中定义为 u64 常量。诸如 MM_BYTECODE_START、MM_RODATA_START 等名称是 Rust 常量定义,表示每个区域的起始地址。这里的 MM 代表“内存映射(memory map)”,而 RO 代表“只读(read-only)”。Solana 为这些内存区域各保留了 4GiB 以防止区域之间的地址冲突,但会根据每个区域实际需要的大小进行分配。
0x000000000:MM_RODATA_START— 4 GiB 用于只读的 ELF 数据(常量、静态数据)0x100000000:MM_BYTECODE_START— 4 GiB 用于程序字节码区域0x200000000:MM_STACK_START— 4 GiB 用于执行栈0x300000000:MM_HEAP_START— 4 GiB 保留用于堆内存区域0x400000000:MM_INPUT_START— 4 GiB 用于当前交易中序列化的输入数据(program id、accounts 和 instruction data)。这是由运行时(runtime)在程序启动时填充的。
Solana BPF 内存布局的可视化如下所示:

Solana 客户端定义的常量如下面的代码片段所示:
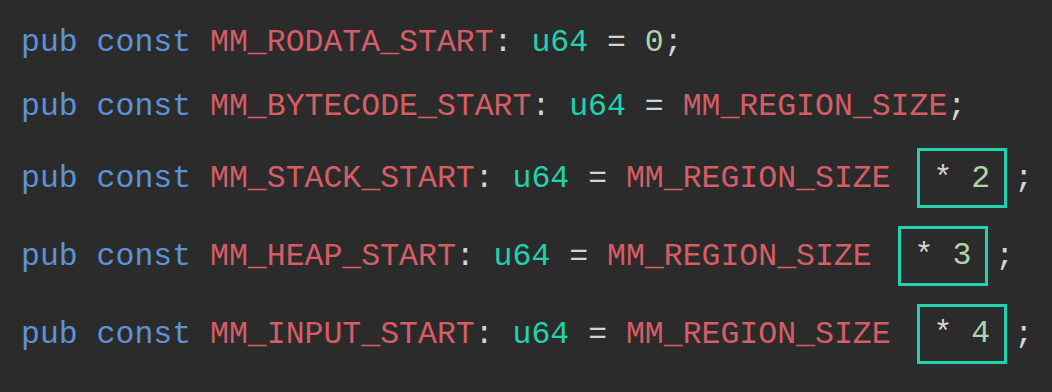
pub const MM_RODATA_START: u64 = 0;
pub const MM_BYTECODE_START: u64 = MM_REGION_SIZE; // = MM_REGION_SIZE * 1
pub const MM_STACK_START: u64 = MM_REGION_SIZE * 2;
pub const MM_HEAP_START: u64 = MM_REGION_SIZE * 3;
pub const MM_INPUT_START: u64 = MM_REGION_SIZE * 4;
MM_REGION_SIZE 定义了一个虚拟内存块的大小,计算方式为 1 << VIRTUAL_ADDRESS_BITS。在 sBPF source code 中,VIRTUAL_ADDRESS_BITS 被定义为 32,这意味着在每个区域内有 2^32 个不同的字节地址,从而为每个区域提供了 4GiB 的可寻址空间。
乘数(* 2、* 3、* 4)将每个区域的起始地址按 MM_REGION_SIZE 的倍数向后推移。
要在内存中使用数据,我们必须首先将其加载到寄存器中。VM 为每个寄存器分配了一个特定角色,开发者应按照约定遵循这些角色分配。下一节将通过极简示例来描述这些角色。
Solana BPF VM 如何为寄存器分配角色
sBPF VM 有 12 registers,命名为 r0 到 r11。寄存器 r0–r10 对程序公开,而 r11 用于保存程序计数器(program counter),并且对 Solana 程序来说既不可读也不可写。
r0 保存返回值,r1–r5 是参数寄存器,r6–r9 是通用暂存寄存器,也称为被调用者保存(callee-saved)寄存器(用于在函数调用之间存储临时值),而 r10 是当前调用栈的帧指针(frame pointer)寄存器。

在检查每个寄存器之前,让我们先设置一个环境来观察执行期间寄存器值是如何变化的。
寄存器实验环境设置
创建一个名为 register-experiment 的新文件夹。在该文件夹中打开终端并运行 solana-test-validator 命令。这将启动一个本地 Solana 集群并在 register-experiment 内创建一个 test-ledger 目录。
本地验证器运行后:
- 在
register-experiment目录中创建一个名为src的文件夹。此文件夹将存放我们的汇编程序以及一个追踪文件(trace file),用于显示每条指令执行后寄存器状态的变化。 - 为我们的汇编代码创建一个
src/inputs.asm文件。
你的目录结构应如下所示:
register-experiment
├── src
└── inputs.asm
我们将使用 agave-ledger-tool(随 Solana 安装附带)来运行我们的汇编代码并创建寄存器追踪。
使用以下命令运行下面的示例。它将在我们的本地测试账本上运行,以 200,000 计算单元(compute-unit)的限制执行汇编程序,并生成一个追踪文件,显示执行期间寄存器值是如何变化的。
agave-ledger-tool program run src/inputs.asm --limit 200000 --trace src/trace.txt --ledger test-ledger
注意:在某些架构(如 Apple Silicon)上,运行此命令可能会触发 JitNotCompiled 错误。要解决此问题,请添加 --mode interpreter 标志以强制使用解释器模式而不是 JIT 编译。
现在环境设置已完成,我们将演示在执行期间如何使用从 r0 到 r11 的每个寄存器。我们的演示将硬编码值到寄存器中以隔离它们的行为。我们将在下一篇文章中展示如何从内存中读取值并加载到寄存器中。
寄存器 r0
程序通过向 r0 写入数据来向运行时传达成功或失败的状态。VM 在执行完成时读取该值。可能的结果有:
- 成功执行返回
0。 - 受控错误返回非零错误代码(我们写入自定义的错误代码)。
- 如果发生 panic,程序在到达 exit 指令前终止,因此运行时会忽略
r0。
让我们基于上述三种可能的结果,演示程序如何使用 r0 传达成功或失败状态。
1/3 演示成功执行返回 0 的示例
在 src/inputs.asm 中编写一条简单的 exit 指令:
exit
使用 agave-ledger-tool 命令运行它,你将获得一个返回 0 的成功退出:
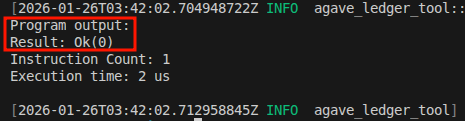
将在 trace.txt 中创建以下追踪记录,显示 r0 的值为 0000000000000000(追踪记录中的第一列是 r0,第二列是 r1……):
Frame 0
0 [0000000000000000, 0000000400000000, ...] 0: exit
上述演示说明,如果函数成功返回,r0 会保存 0。
2/3 演示受控失败返回非零值的示例。
如果发生受控失败,我们可以向 r0 写入数据。如果由于某些原因我们希望返回一个自定义的错误代码,例如 600 (0x0000000000000258),程序依然会正常退出,但 r0 中保存的是该错误代码而非零:
mov r0, 600 ; Set custom error code
exit
汇编代码示例中的注释在直接复制时可能会导致解析错误,因为如果存在注释,agave-ledger-tool 会抛出错误。如果发生这种情况,请删除注释 ; Set custom error code。
使用 agave-ledger-tool 运行上述代码,你将得到以下输出:
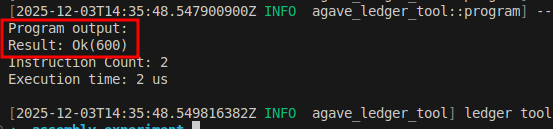
追踪记录显示 r0 从 0 开始,其当前状态的十六进制为 0000000000000258,即十进制的 600:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: lddw r0, 0x258
1 [0000000000000258, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: exit
3/3 演示 panic 或 trap 会终止执行且不写入 r0 的示例
panic 或 trap 会终止执行,并被视为不可恢复的错误。它不会将结果存储在 r0 中,因此之前存储在其中的任何值都会被忽略。
下面的代码演示了试图向只读内存区域写入 42 的操作。
lddw r1, 0x000000000 ;Load MM_RODATA_START address into r1
stdw [r1 + 0], 42 ;Attempt to store 42 into the MM_RODATA_START
exit
在上述代码中:
lddw将一个 64 位立即数(immediate value)加载到寄存器中。我们使用它将只读区域的起始地址(0x000000000)加载到r1中。stdw将一个 64 位立即数直接存储到内存中。我们试图使用此指令将 42 写入只读内存区域,在运行时这将触发访问冲突错误。

在追踪记录中,你会注意到追踪在第 1 行(即 stxdw 行)结束了,因为我们正在尝试进行无效的内存操作,从而导致了 trap。程序永远不会到达 exit 指令。
Frame 0
0 [0000000000000000, 0000000400000000, ...] 0: lddw r1, 0x100000000
1 [0000000000000000, 0000000100000000, ...] 2: stxdw [r1+0x0], r2
到目前为止,我们已经介绍了 r0 在不同场景中的行为以及 VM 如何使用它。在 Rust 层,返回值显示为 Ok(u64) 或 Err(...),但在 VM 中,它只是一个存储在 r0 中并从中读取的单一 u64 状态码。
下表显示了在每种场景下发生的情况以及 r0 在该场景中保存的值:
| 场景 | 发生的情况 | r0 中的值 |
|---|---|---|
| 正常返回 | 程序完成并返回到加载器(loader) | 0 |
| 受控错误(Anchor 或手动错误处理) | 程序设置错误代码并返回 | 非零错误代码(例如:2, 600, 1, 5 等) |
| 断言失败或中止 | 程序终止 | r0 被忽略,因为程序未到达 exit 指令 |
寄存器 r1
在程序启动时,r1 保存 MM_INPUT_START(0x400000000),它指向内存中序列化输入参数的起始位置。
假设我们有一个接受两个参数 a 和 b 的函数:
fn add_constant(a: u64, b: u64)
当程序开始执行时,运行时将 a 和 b 的序列化值存储在 MM_INPUT_START 的内存位置。在这个阶段,寄存器 r1 指向 MM_INPUT_START(也就是说,r1 包含了 MM_INPUT_START 的地址)。
在执行期间,r1 的角色会转变为参数寄存器,且其内容可被程序覆盖。
寄存器 r1-r5
如果你的程序函数在执行期间需要参数,运行时期望程序将这些参数存储在 r1 到 r5 中。如果一个函数需要超过五个参数,你必须将额外的值存储在栈中,并使用这些寄存器之一将指针传递给它们。
当函数返回时,参数寄存器中的值被认为是“脏(dirty)”的。接下来执行的函数可以随意覆盖 r1–r5。
让我们通过调用一个接受两个参数的 add_numbers 函数来演示参数传递。
fn add_numbers(a: u64, b: u64) -> u64 {
a + b
}
为了简单起见,我们绕过编译器,手动将上述代码转换为 sBPF 汇编。代码片段如下所示。让我们传递 10 作为第一个参数,25 作为第二个参数,在函数体内将它们相加,并在 r0 中返回结果:
mov r1, 10 ; Simulate passing a=10 as first argument
mov r2, 25 ; Simulate passing b=25 as second argument
add64 r1, r2 ; Function body: add first and second argument
mov r3, r1 ; Copy the result to r3
exit ; exit successfuly with 0 in r0
运行 agave-ledger-tool 并检查 trace.txt 文件。你会看到结果是 23(十进制的 35):

接下来的寄存器是 r6-r9,但它们依赖于 r10(栈指针)。让我们首先解释 r10,然后再回到 r6-r9。
栈指针寄存器(r10)
r10 是栈帧指针(stack frame pointer)。它保存一个指向当前栈区域的虚拟地址。
当你的程序启动时,运行时将 r10 初始化为 MM_STACK_START + stack_frame_size,其中 MM_STACK_START 为 0x200000000,而 stack_frame_size = 4096(十六进制的 1000)字节(4KiB)——在追踪记录中,你会看到 r10 初始化为 0x200001000。这使 r10 位于栈帧顶部,其下方有 4096 字节的可用空间。
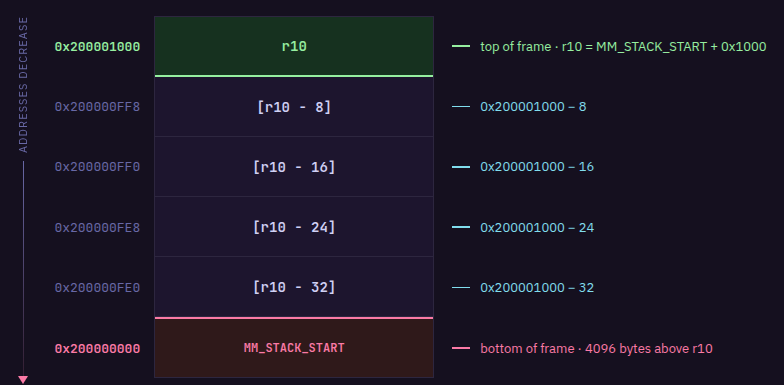
栈向下增长,这意味着你在逐渐减小的内存地址上分配栈空间。因为 r10 = MM_STACK_START + stack_frame_size,对任何栈位置的读写都遵循以下公式:
[r10 - offset] = MM_STACK_START + stack_frame_size - offset
其中 offset 是消耗的栈空间字节数。这意味着 [r10 - 8] 会解析为 MM_STACK_START + stack_frame_size - 8,你正在引用一个比 r10 所指位置低 8 字节的内存地址。
因此 r10 本身的值在程序执行期间永远不会改变。要使用更多的栈空间,你只需使用更大的偏移量,例如 [r10 - 16]、[r10 - 24] 等等。每个函数调用的可用空间被限制为 4KiB(4096 字节)。
假设你需要通过栈将数据传递给一个函数。你在栈帧中选择一个基于 r10 为负偏移量的位置,将数据写入该处,然后在调用前将该位置的地址(例如,r10 - 8)放入其中一个参数寄存器(r1 到 r5)中。
例如,如果你需要一个 64 字节的缓冲区作为第一个参数:
- 你可以将数据存储在
[r10 - 64]到[r10 - 1]的内存区域 - 将起始地址
r10 - 64移入r1中

- 然后你发起函数调用
我们将在介绍“寄存器 6-9”时演示如何使用 r10 栈指针。
r10 的写入限制
你无法对 r10 寄存器进行写入。使用 mov 向 r10 写入会返回错误:
mov r10, 999 # Error: cannot write to r10
exit

试图使用 add r10, -64 对 r10 进行写入操作虽然不会报错,但 VM 会静默忽略它,并将该指令重写为一个不做任何事情的 64 位按位或指令(or64 r0, 0):
add r10, -64
exit
如果我们运行上述代码并查看追踪文件,会看到 r10 保持不变:

被调用者保存的寄存器(r6-r9)
在 Solana BPF 中,寄存器 r6-r9 是“被调用者保存(callee-saved)”的(也称为“被保留的(preserved)”)。这意味着如果一个函数(被调用者)修改了这些寄存器,它必须在返回给调用者之前将它们恢复为原始值。
例如,如果函数 A 在 r6 中存储了一个值并调用了函数 B,而函数 B 希望使用 r6 进行自己的计算,函数 B 必须在使用 r6 之前保留它里边原有的任何内容。函数 B 的做法是:将 r6 复制到栈中,使用 r6 进行它自身的计算,然后在返回前将原始值从栈中复制回 r6。当函数 B 退出时,函数 A 在 r6 中仍保有它的原始值。
下面的代码演示了两个函数之间的数据保留约定:
- 函数 A(CALLER)在
r6中存储 999 - 函数 A 调用函数 B(
function_b),并期望r6被保留 - 函数 B 将
r6(999)复制到栈的[r10 - 8]处 - 函数 B 使用
r6进行其自身的计算:加载 42 并加上 10(结果为 52) - 函数 B 在返回前将
r6从栈中恢复为 999 - 当函数 B 退出时,函数 A 在
r6中依然保有 999 - 函数 A 将
r6移入r2以使用被保留的值
; === Function A: CALLER ===
mov r6, 999 ; Store value we want preserved across call
call function_b ; function_b MUST preserve r6 per convention
mov r2, r6 ; r6 still contains 999 (preserved by callee)
exit
; === Function B: CALLEE ===
function_b:
; Save callee-saved registers we'll modify
stxdw [r10 - 8], r6 ; copy caller's r6 value to stack
; FUNCTION BODY: We can freely use r6 now
mov r6, 42 ; Temporary use of r6
add64 r6, 10 ; r6 = 52 (will be discarded)
; Restore callee-saved registers
ldxdw r6, [r10 - 8] ; Restore original r6 value (999)
exit
下面的动画演示了这些步骤:
运行上述代码会生成如下追踪记录:
Frame 0
0 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 0000000000000000, ..., ..., ..., 0000000200001000] 0: mov64 r6, 999
1 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 1: call function_b
2 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 4: stxdw [r10-0x8], r6
3 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 5: mov64 r6, 42
4 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 000000000000002A, ..., ..., ..., 0000000200003000] 6: add64 r6, 10
5 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 0000000000000034, ..., ..., ..., 0000000200003000] 7: ldxdw r6, [r10-0x8]
6 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200003000] 8: exit
7 [..., 0000000400000000, 0000000000000000, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 2: mov64 r2, r6
8 [..., 0000000400000000, 00000000000003E7, ..., ..., ..., 00000000000003E7, ..., ..., ..., 0000000200001000] 3: exit
从追踪记录中得出的关键观察:
- 第 1 行:调用之前,
r6包含0x3E7(999) - 第 2 行:
call指令跳转到function_b,并更新r10以指向0x200003000处的新栈帧 - 第 4 行:在
mov64 r6, 42后,r6包含0x2A(42) - 第 5 行:在
add64 r6, 10后,r6包含0x34(52) - 第 6 行:在
ldxdw r6, [r10-0x8]后,r6被恢复为0x3E7(999) - 第 7 行:返回调用者后,
r10恢复为0x200001000,并且r6依然包含0x3E7(999) - 第 8 行:在
mov64 r2, r6后,r2和r6都包含0x3E7(999)
下面的动画解释了上述步骤:
在本文的下一部分中,我们将通过编写简单的裸汇编程序以直接检查内存内容,进一步演示如何对指令输入进行内存读写。
本文是 Solana development 系列教程的一部分