En el tutorial anterior, introdujimos el diseño de memoria de sBPF y explicamos el propósito de cada registro durante la ejecución del programa.
En este tutorial, demostraremos cómo leer campos de entrada de instrucción como las claves de cuenta, el ID del programa y los datos de instrucción usando ensamblador sBPF. Al hacerlo, observaremos cómo están distribuidos en la memoria.
Escribiendo ensamblador para leer datos de la memoria sBPF
Cuando se ejecuta un programa de Solana, el entorno de ejecución (runtime) serializa las entradas de instrucción del programa (cuentas, datos de instrucción, ID del programa) y las carga en la región de memoria de entrada que comienza en 0x400000000.
Escribiremos programas simples en ensamblador que lean datos desde esta región de memoria de entrada hacia los registros.
Configuración
Crea una nueva carpeta llamada assembly-experiment. Abre una terminal en esta carpeta y ejecuta solana-test-validator. Esto inicia un clúster local de Solana y crea un directorio test-ledger para almacenar los datos del libro mayor (ledger).
Crea las siguientes carpetas y archivos en el directorio assembly-experiment:
- Una carpeta
srcpara alojar tu programa en ensamblador y la salida de la traza - Un archivo
src/inputs.asmpara tu código en ensamblador - Un archivo
src/instructions.jsonpara los datos de la transacción que se serializan y se envían al programa
Después de crear la carpeta y los archivos, la carpeta assembly-experiment debería verse así:
assembly-experiment/
├── test-ledger/
└── src/
├── inputs.asm
└── instructions.json
Diagrama de referencia del diseño de serialización de instrucciones
¿Recuerdas el diagrama de serialización de instrucciones del tutorial anterior? Este mapea el desplazamiento de bytes (byte offset) para cada campo serializado en la memoria. Usaremos estos desplazamientos para leer datos específicos de la región de entrada en nuestro código en ensamblador.

Usando la instrucción ldxdw para cargar datos desde la memoria a los registros
En nuestro programa en ensamblador, usaremos la instrucción sBPF ldxdw para cargar datos desde la memoria. Esta instrucción realiza una carga indexada, donde la dirección final se calcula a partir de un registro base más un desplazamiento.
Esto es lo que significa cada parte de la instrucción:
ldxsignifica cargar desde la memoria usando un registro más un desplazamiento para calcular la dirección (carga indexada). Por ejemplo:[r1 + offset]. La variableoffsetserá reemplazada por el desplazamiento del campo específico dentro de la entrada serializada.dwsignifica que el ancho de la carga es de una palabra doble (double-word), que son 64 bits o 8 bytes.
Cada experimento debe usar un programa en ensamblador estructurado como el código a continuación para cargar un valor desde la memoria a un registro. Los registros usados en este ejemplo son arbitrarios; cualquier registro funcionaría. Aquí usamos r1 porque contiene la entrada de la instrucción al inicio, mientras que r2 no tiene un significado especial y se usa solo para demostración.
ldxdw r2, [r1 + offset]
exit
Este programa carga 8 bytes desde la dirección de memoria [r1 + offset] al registro r2, y luego termina. El registro r1 apunta al inicio de la entrada de instrucción serializada en 0x400000000. Reemplazaremos offset con el desplazamiento de bytes real de cualquier campo en la memoria que estemos leyendo.
Para ver cómo la instrucción ldxdw carga valores desde la memoria, considera esta parte del diseño de serialización de entrada de instrucción que se muestra a continuación:

En este diseño, el conteo de cuentas (Num Accounts) comienza en el desplazamiento 0x00, y la bandera de duplicado (duplicate flag) comienza en el desplazamiento 0x08. Para cargar cada valor, reemplaza offset con el desplazamiento de bytes del campo, y la VM lee de esa ubicación relativa a la base de entrada almacenada en r1.
A diferencia de la EVM, donde se accede a las entradas de instrucción desde calldata, Solana carga las entradas de instrucción en la memoria antes de que comience la ejecución. Así es como funciona en la práctica:
- Para leer el conteo de cuentas, usa el desplazamiento
0x00y cárgalo de la memoria ar2conldxdw r2, [r1 + 0x00]. Esto lee desde la dirección0x400000000(0x400000000 + 0). Si la instrucción contiene dos cuentas,r2contendrá2. - Para leer la bandera de duplicado, usa el desplazamiento
0x08y cárgalo conldxdw r2, [r1 + 0x08]. Esto lee desde la dirección0x400000008(0x400000000 + 8), que es donde comienza el campo de la bandera.
A lo largo de este artículo, usaremos diferentes valores de desplazamiento para inspeccionar varias partes de la región de memoria donde el entorno de ejecución almacenó las entradas de instrucción serializadas.
Ahora que hemos sentado las bases para entender cómo leer de la memoria usando la instrucción ldxdw, vamos a crear nuestros datos de prueba.
Configurando la entrada de prueba
Crearemos una instrucción de transacción de prueba con una sola cuenta en el arreglo de cuentas, propiedad del BPF Loader. Esto nos permitirá ilustrar cómo la VM lee la entrada de instrucción serializada.
Los datos de prueba a continuación incluyen:
- Un arreglo de cuentas con el siguiente formato:
- clave pública
- propietario (owner)
- Banderas de la cuenta: no es firmante, escribible, no ejecutable
- Saldo de 1,000 lamports
- 4 bytes de datos de cuenta:
[0, 0, 0, 3]
- Un ID del programa
- 4 bytes de datos de instrucción:
[2, 0, 0, 0]
Aquí están los datos de prueba, pégalos en src/instructions.json. El entorno de ejecución utilizará esto para cargar la instrucción en la memoria. A lo largo de este tutorial, examinaremos cómo la VM de sBPF lee la instrucción desde la memoria.
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
"program_id": "HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC",
"instruction_data": [2, 0, 0, 0]
}
A continuación, un recordatorio rápido de cómo ejecutar el agave-ledger-tool.
Ejecutando nuestro código en ensamblador
Usaremos agave-ledger-tool para ejecutar nuestro código en ensamblador y rastrear los estados de los registros después de cada instrucción. Esta herramienta viene preinstalada con tu instalación de desarrollo de Solana.
El agave-ledger-tool genera trazas de ejecución que muestran las transiciones de estado de los registros. Dado que no podemos ver directamente el contenido de la memoria, copiaremos valores de la memoria a los registros e inspeccionaremos esos registros en la salida de la traza.
A continuación, el comando agave-ledger-tool que usaremos para ejecutar nuestros programas en ensamblador. Ejecutará nuestro programa con un límite de 200,000 unidades de cómputo (compute units), escribirá un archivo de traza mostrando los estados de los registros, usará nuestro libro mayor de prueba local y tomará la entrada de nuestro archivo instructions.json:
agave-ledger-tool program run inputs/inputs.asm --limit 200000 --trace inputs/trace.txt --ledger test-ledger --input inputs/instructions.json
Leyendo el conteo de cuentas en nuestra entrada de prueba
Según el diagrama del formato de serialización que mostramos anteriormente, los primeros 8 bytes contienen el número de cuentas con un desplazamiento de 0x00. Nuestro parámetro de entrada contiene solo una cuenta en la lista de accounts:
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
... // other input parameters
}
Para demostrar esto, reemplaza offset con 0x00 en tu programa en ensamblador. Esto carga 8 bytes desde la dirección r1 + 0x00 (es decir, 0x400000000) en r2. La elección de r2 es arbitraria, cualquier otro registro de argumento podría usarse aquí.
ldxdw r2, [r1 + 0x00]
exit
Ejecuta el programa utilizando el comando agave-ledger-tool, luego abre inputs/trace.txt para ver la traza de ejecución:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x0]
1 [0000000000000000, 0000000400000000, 0000000000000001, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
La traza muestra los estados de los registros antes y después de cada instrucción. El arreglo muestra los registros en orden: [r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10].

La línea 0 muestra el estado inicial: r1 contiene 0x400000000 (la dirección base de entrada) y r2 es cero.
La línea 1 muestra el estado después de la ejecución de la instrucción ldxdw r2, [r1+0x0] : r2 ahora contiene 1 (0000000000000001), que es el número de cuentas en nuestra entrada de transacción.
Leyendo banderas de cuenta y la región de relleno (padding)
Los siguientes 8 bytes, comenzando en el desplazamiento 0x08, contienen 4 banderas de un byte seguidas de 4 bytes de relleno (padding) como se muestra en el diagrama a continuación. Dado que los registros almacenan 8 bytes, cargaremos todas las banderas y el relleno de una vez en un registro.
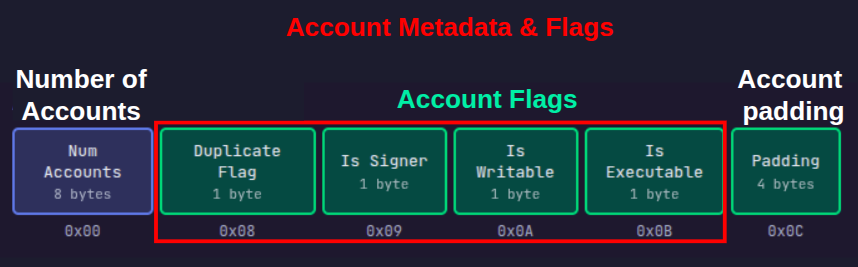
La bandera de duplicado es un solo byte en el desplazamiento 0x08 con las siguientes propiedades:
- si la cuenta es única, la bandera de duplicado será el byte
0xFF. - si la cuenta es un duplicado de una cuenta anterior en el arreglo de cuentas, la bandera de duplicado debe ser el índice de la cuenta original.
Los datos de nuestra transacción de prueba solo tienen una cuenta, por lo que no puede ser un duplicado.
Podemos ver el contenido de estas banderas en la memoria cargándolas en registros utilizando la instrucción ldxdw r2, [r1 + offset]. Reemplazando la variable offset con el desplazamiento desde el que tenemos la intención de comenzar a leer.
Vamos a mostrar que la bandera de duplicado tiene el valor 0xFF (indicando una cuenta única):
ldxdw r2, [r1 + 0x08]
exit
Recuerda que ldxdw carga 8 bytes, no solo 1 byte. Así que, aunque la bandera de duplicado es solo el primer byte en el desplazamiento 0x08, esta instrucción cargará la bandera de duplicado más los 7 bytes que le siguen en r2. Esto significa que también veremos las otras banderas de la cuenta y el relleno que ocupan los desplazamientos desde 0x08 hasta 0x0F.
Ejecuta el programa y revisa src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x8]
1 [0000000000000000, 0000000400000000, **00000000000100FF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
La traza muestra que el registro r2 ahora contiene 00000000000100FF (en formato little-endian—el byte más a la derecha FF está en la dirección de memoria más baja 0x08), por lo tanto, leeremos los bytes resaltados a la inversa, lo que significa:
FF(byte 0, desplazamiento0x08): bandera de duplicado,0xFFsignifica que no es un duplicado00(byte 1, desplazamiento0x09): la cuenta no es firmante. En nuestra transacción, establecimos esto enfalse, lo que se traduce en001(byte 2, desplazamiento0x0A): la cuenta es escribible. En nuestra transacción, establecimos esto entrue, lo que se traduce en100(byte 3, desplazamiento0x0B): la cuenta no es ejecutable. No establecimos esto, por defecto esfalse00000000(bytes 4-7, desplazamientos0x0C-0x0F): relleno de la cuenta
Leyendo la clave pública de la cuenta
Los siguientes 32 bytes de la entrada de instrucción serializada contienen la clave pública de la cuenta, seguidos por otros 32 bytes para la clave pública del propietario (que se discutirá en la próxima sección).
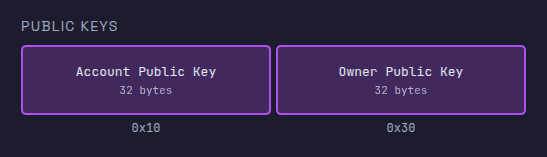
Un registro almacena 8 bytes. Ya que estamos intentando cargar más de 8 bytes, tenemos que usar múltiples registros. Cargaremos la clave pública de la cuenta en cuatro fragmentos a través de los registros r2, r3, r4 y r5.
El programa a continuación carga cuatro fragmentos de 8 bytes desde la memoria a los registros. Reemplaza el contenido de src/inputs.asm con el siguiente código:
ldxdw r2, [r1+16] ; Load bytes 16-23 (first 8 bytes of public key) into r2
ldxdw r3, [r1+24] ; Load bytes 24-31 (next 8 bytes) into r3
ldxdw r4, [r1+32] ; Load bytes 32-39 (next 8 bytes) into r4
ldxdw r5, [r1+40] ; Load bytes 40-47 (last 8 bytes) into r5
exit
Ejecuta el programa con el agave-ledger-tool. El archivo de traza ahora debería tener este contenido:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x10]
1 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x18]
2 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x20]
3 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x28]
4 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 1B20575E7D084725, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
Recuerda que la cadena a continuación es la clave pública que tenemos en el archivo instructions.json que se está almacenando en la memoria y cargando en los registros.
524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca
Si convertimos la clave pública de su formato original en base58 a hexadecimal, tendremos esto:
3BB40A1B35AE44FAB6C5407D140DF5823FD193BD415214352547087D5E57201B
La dividiremos en fragmentos de 8 bytes para cada registro, ya que eso es lo que cada registro puede almacenar. Tendremos esto:
0x3bb40a1b35ae44fa 0xb6c5407d140df582 0x3fd193bd41521435 0x2547087d5e57201b
Los valores de los registros se muestran/interpretan en orden little-endian, por lo que los fragmentos de 8 bytes aparecen como se muestra a continuación.
FA44AE351B0AB43B 82F50D147D40C5B6 35145241BD93D13F 1B20575E7D084725
Vamos a rastrear cada paso:

- Línea 0: Estado inicial antes de cualquier carga. Se muestran todos los registros (
r0-r10), conr1conteniendo0000000400000000(MM_INPUT_START). - Línea 1: Después de ejecutar
ldxdw r2, [r1+16], el registror2(tercera posición) ahora contieneFA44AE351B0AB43B(los primeros 8 bytes de la clave pública en formato little-endian). - Línea 2: Después de ejecutar
ldxdw r3, [r1+24], el registror3(cuarta posición) ahora contiene82F50D147D40C5B6(los siguientes 8 bytes). - Línea 3: Después de ejecutar
ldxdw r4, [r1+32], el registror4(quinta posición) ahora contiene35145241BD93D13F(los siguientes 8 bytes). - Línea 4: Después de ejecutar
ldxdw r5, [r1+40], el registror5(sexta posición) ahora contiene1B20575E7D084725(los últimos 8 bytes).
Al comparar cada registro (r2, r3, r4, r5) con nuestros valores hexadecimales esperados, vemos que coinciden perfectamente.
Leyendo la clave pública del propietario
La clave pública del propietario comienza en el desplazamiento 0x30 (48 en decimal) después de la clave pública de la cuenta y abarca 32 bytes. Dado que cada instrucción ldxdw carga 8 bytes, necesitas cuatro cargas para leer toda la clave. El propietario en nuestro ejemplo es BPFLoaderUpgradeab1e11111111111111111111111
Vamos a demostrarlo con el código a continuación. Actualiza src/inputs.asm:
ldxdw r2, [r1+48] ; Load bytes 48-55 (first 8 bytes of owner public key) into r2
ldxdw r3, [r1+56] ; Load bytes 56-63 (next 8 bytes) into r3
ldxdw r4, [r1+64] ; Load bytes 64-71 (next 8 bytes) into r4
ldxdw r5, [r1+72] ; Load bytes 72-79 (last 8 bytes) into r5
exit
Ejecuta el código. La traza muestra que cada registro carga su fragmento de 8 bytes:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x30]
1 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x38]
2 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x40]
3 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x48]
4 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 00008004107A53C0, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
Cuando conviertes la dirección del propietario BPFLoaderUpgradeab1e11111111111111111111111 a hexadecimal y la divides en fragmentos de 8 bytes little-endian, obtienes:
B0A1884E91F6A802 2BAE63F73E1510E2 D224C1163DB9C200 00008004107A53C0
Estos valores coinciden con los que aparecen en los registros desde r2 hasta r5 en la traza.
Leyendo lamports
Los siguientes 8 bytes después de la clave pública del propietario contienen el saldo de lamports de la cuenta. El campo de lamports está ubicado en el desplazamiento 0x50 (80 en decimal) en la memoria.
Carguemos el campo de lamports en un registro y examinémoslo. Usa 0x50 como el desplazamiento en nuestro programa en ensamblador:
ldxdw r2, [r1 + 0x50]
exit
Ejecuta el programa y revisa src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x50]
1 [0000000000000000, 0000000400000000, **00000000000003E8**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
Vemos que el Registro r2 contiene 00000000000003E8, que es la representación hexadecimal de 1,000 lamports. Esto coincide con el valor lamports: 1000 en nuestro archivo de instrucciones.
Leyendo la longitud de los datos de la cuenta
Los siguientes 8 bytes después del campo de lamports corresponden a la longitud de los datos de la cuenta, ubicados en el desplazamiento 0x58. Actualiza src/inputs.asm para leer desde el desplazamiento 0x58:
ldxdw r2, [r1 + 0x58]
exit
Ejecuta el programa y revisa src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x58]
1 [0000000000000000, 0000000400000000, **0000000000000004**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
El registro r2 contiene 0000000000000004, indicando que nuestra cuenta tiene 4 bytes de datos. Esto coincide con el arreglo de 4 elementos en el campo data: [0, 0, 0, 3] de nuestro archivo instructions.json.
Leyendo los datos de la cuenta
Los datos de la cuenta comienzan en el desplazamiento 0x60, inmediatamente después de la longitud de los datos de la cuenta. Nuestra cuenta de prueba tiene 4 bytes de datos que abarcan los desplazamientos 0x60-0x63. Para mostrar esto, carguemos los datos en el offset 0x60:
ldxdw r2, [r1 + 0x60]
exit
Ejecuta el programa. La traza muestra:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x60]
1 [0000000000000000, 0000000400000000, **0000000003000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
El registro r2 contiene 0000000003000000. La instrucción carga 8 bytes, pero solo los primeros 4 bytes contienen tus datos reales. Al leer esos 4 bytes de derecha a izquierda (little-endian) se obtiene [00, 00, 00, 03], lo que coincide con data: [0, 0, 0, 3] del archivo de instrucciones.
Leyendo el relleno de reasignación (realloc padding)
Después de los datos de la cuenta, el entorno de ejecución reserva 10,240 bytes (10 KiB) de espacio lleno de ceros para un posible crecimiento de los datos de la cuenta durante la ejecución del programa (mediante reasignación, o reallocation).
Este relleno comienza en el desplazamiento 0x64 (donde terminan nuestros 4 bytes de datos de cuenta) y se extiende hasta el desplazamiento 0x2864 (10,340 en decimal).
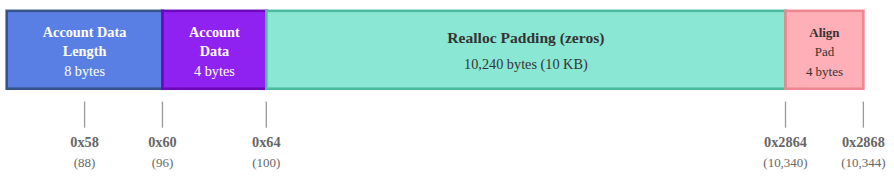
Podemos mostrar esto cargando un desplazamiento aleatorio dentro de este rango desde la memoria hacia un registro. Verifiquemos el desplazamiento 0x1388:
ldxdw r2, [r1 + 0x1388]
exit
Ejecuta el programa. El registro r2 debería contener 0000000000000000, mostrando que esta región está llena de ceros.
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x1388]
1 [0000000000000000, 0000000400000000, **0000000000000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
Leyendo el relleno de alineación (alignment padding)
Después del relleno de reasignación de 10k, el siguiente campo debe comenzar en un límite de 8 bytes (8-byte boundary). El relleno de reasignación termina en el desplazamiento 0x2864 (10340). Debido a que este desplazamiento no está alineado a 8 bytes, el entorno de ejecución lo redondea hacia arriba a 10344, agregando 4 bytes de relleno de alineación.
Para examinar el contenido de la memoria en el límite entre el relleno de reasignación y el siguiente campo, carguemos desde el desplazamiento 0x2864 en r2 e inspeccionemos la traza.
ldxdw r2, [r1 + 0x2864]
exit
La traza debería mostrar FFFFFFFF00000000 en el registro r2:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2864]
1 [0000000000000000, 0000000400000000, FFFFFFFF00000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
FFFFFFFF00000000 en forma little-endian corresponde a los bytes 00 00 00 00 FF FF FF FF. Nuestra instrucción ldxdw lee a través de dos campos: los primeros cuatro bytes en cero son el relleno de alineación, y los siguientes cuatro bytes FF son el inicio del campo de epoch de renta (rent epoch). El cual discutiremos a continuación.
Leyendo la epoch de renta
Los siguientes 8 bytes después del relleno de alineación contienen la epoch de renta (rent epoch) para la cuenta.
En la práctica, las cuentas en Solana se crean exentas de renta (rent-exempt), por lo que el campo de la epoch de renta se establece en el valor exento de renta por defecto, codificado como FFFFFFFFFFFFFFFF.
Para mostrar esto, cargaremos la epoch de renta desde el desplazamiento 10344 (0x2868), que es el inicio de la región de la epoch de renta, en r2.
ldxdw r2, [r1 + 0x2868]
exit
Ejecutar esto debería mostrar:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2868]
1 [0000000000000000, 0000000400000000, **FFFFFFFFFFFFFFFF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
El registro r2 contiene FFFFFFFFFFFFFFFF.
Leyendo la longitud de los datos de instrucción
Los siguientes 8 bytes después de la epoch de renta contienen la longitud de los datos de instrucción en el desplazamiento 10352. Nuestra transacción de prueba incluye 4 bytes de datos de instrucción. Reemplaza offset con 10352:
ldxdw r2, [r1 + 10352]
exit
El código debería producir esta traza cuando lo ejecutes:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2870]
1 [0000000000000000, 0000000400000000, 0000000000000004, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
El registro r2 contiene 0000000000000004, lo cual muestra que el arreglo de datos de instrucción tiene 4 bytes como se especifica en nuestro archivo instructions.json.
Leyendo los datos de instrucción
Los siguientes bytes, comenzando en el desplazamiento 10360, contienen los datos de instrucción. Nuestra prueba incluye 4 bytes: [2, 0, 0, 0] (pero esta longitud varía por transacción). Reemplaza offset con 10360 (0x2878 en hexadecimal) para inspeccionarlo:
ldxdw r2, [r1 + 0x2878]
exit
El código produce esta traza cuando lo ejecutas:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2878]
1 [0000000000000000, 0000000400000000, **BA2D9AF400000002**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
El registro r2 contiene BA2D9AF400000002. Dado que ldxdw carga 8 bytes pero los datos de instrucción solo tienen 4 bytes de longitud, esta lectura también incluye los primeros 4 bytes del siguiente campo. Los 32 bits inferiores (00000002) representan nuestros datos de instrucción [2, 0, 0, 0] en formato little-endian.
Leyendo el ID del programa
Los últimos 32 bytes contienen el ID del programa que se está invocando. Ya que nuestros datos de instrucción tienen 4 bytes de longitud, ocupan los desplazamientos 10360- 10363. El ID del programa comienza inmediatamente después en el desplazamiento 10364 (0x287C en hexadecimal).
Para inspeccionarlo, podemos cargar los 32 bytes completos a través de cuatro registros:
ldxdw r2, [r1+10364]
ldxdw r3, [r1+10372]
ldxdw r4, [r1+10380]
ldxdw r5, [r1+10388]
exit
Ejecuta el programa y revisa el archivo de traza:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 29: ldxdw r2, [r1+0x287c]
1 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 30: ldxdw r3, [r1+0x2884]
2 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 31: ldxdw r4, [r1+0x288c]
3 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 32: ldxdw r5, [r1+0x2894]
4 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, B7CFB5A9E7B8C99A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 33: exit
Los cuatro registros contienen el ID completo del programa en formato little-endian. Para reconstruir el ID del programa, invertimos el orden de los bytes del valor de cada registro y los concatenamos:
- r2:
C512BA35BA2D9AF4→F49A2DBA35BA12C5 - r3:
08D0A2FB506C1A71→711A6C50FBA2D008 - r4:
93EAF43A2BD4867A→7A86D42B3AF4EA93 - r5:
B7CFB5A9E7B8C99A→9AC9B8E7A9B5CFB7
Concatenar estos nos da 0xf49a2dba35ba12c5711a6c50fba2d0087a86d42b3af4ea939ac9b8e7a9b5cfb7 en hexadecimal, lo cual se decodifica como HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC en base58. Esto coincide con el campo program_id en nuestro archivo instructions.json.
Probando con un arreglo de cuentas o datos de instrucción vacíos
Cuando una transacción tiene un arreglo de cuentas vacío o no tiene datos de instrucción, la VM solo reserva espacio para los campos de conteo (conteo de cuentas y longitud de datos de instrucción), los cuales serán ambos 0. Demostraremos esto con ejemplos reales en el próximo artículo, donde discutiremos las llamadas al sistema (syscalls).
Este artículo es parte de una serie de tutoriales sobre desarrollo en Solana