पिछले ट्यूटोरियल में, हमने sBPF memory layout का परिचय दिया था और प्रोग्राम निष्पादन (execution) के दौरान प्रत्येक रजिस्टर के उद्देश्य को समझाया था।
इस ट्यूटोरियल में, हम प्रदर्शित करेंगे कि sBPF assembly का उपयोग करके account keys, program ID और instruction data जैसे instruction input fields को कैसे पढ़ा जाए। ऐसा करते समय, हम देखेंगे कि उन्हें मेमोरी में कैसे व्यवस्थित किया गया है।
sBPF memory से डेटा पढ़ने के लिए Assembly लिखना
जब कोई Solana प्रोग्राम चलता है, तो रनटाइम प्रोग्राम के instruction inputs (accounts, instruction data, program ID) को सीरियलाइज़ (serialize) करता है और उन्हें 0x400000000 से शुरू होने वाले इनपुट मेमोरी रीजन (input memory region) में लोड करता है।
हम सरल assembly प्रोग्राम लिखेंगे जो इस इनपुट मेमोरी रीजन से डेटा को रजिस्टरों में पढ़ते हैं।
सेटअप (Setup)
assembly-experiment नाम का एक नया फोल्डर बनाएं। इस फोल्डर में एक टर्मिनल खोलें और solana-test-validator चलाएं। यह एक लोकल Solana क्लस्टर शुरू करता है और लेज़र डेटा स्टोर करने के लिए एक test-ledger डायरेक्टरी बनाता है।
assembly-experiment डायरेक्टरी में निम्नलिखित फोल्डर और फाइलें बनाएं:
- आपके assembly प्रोग्राम और ट्रेस आउटपुट (trace output) को रखने के लिए एक
srcफोल्डर - आपके assembly कोड के लिए एक
src/inputs.asmफाइल - ट्रांजेक्शन डेटा के लिए एक
src/instructions.jsonफाइल जो सीरियलाइज़ होकर प्रोग्राम को भेजी जाती है
फोल्डर और फाइलें बनाने के बाद, assembly-experiment फोल्डर कुछ इस तरह दिखना चाहिए:
assembly-experiment/
├── test-ledger/
└── src/
├── inputs.asm
└── instructions.json
Instruction serialization layout संदर्भ आरेख (reference diagram)
क्या आपको पिछले ट्यूटोरियल से instruction serialization आरेख याद है? यह मेमोरी में प्रत्येक सीरियलाइज़्ड फील्ड के लिए बाइट ऑफ़सेट (byte offset) को मैप करता है। हम अपने assembly कोड में इनपुट रीजन से विशिष्ट डेटा पढ़ने के लिए इन ऑफ़सेट्स का उपयोग करेंगे।

मेमोरी से रजिस्टरों में डेटा लोड करने के लिए ldxdw instruction का उपयोग करना
हमारे assembly प्रोग्राम में, हम मेमोरी से डेटा लोड करने के लिए sBPF instruction ldxdw का उपयोग करेंगे। यह instruction एक इंडेक्स्ड लोड (indexed load) करता है, जहाँ अंतिम एड्रेस की गणना एक बेस रजिस्टर (base register) और एक ऑफ़सेट (offset) को जोड़कर की जाती है।
instruction के प्रत्येक भाग का अर्थ यहाँ दिया गया है:
ldxका अर्थ है एड्रेस की गणना करने के लिए एक रजिस्टर और एक ऑफ़सेट का उपयोग करके मेमोरी से लोड करना (indexed load)। उदाहरण के लिए:[r1 + offset]।offsetवेरिएबल को सीरियलाइज़्ड इनपुट के भीतर विशिष्ट फील्ड के ऑफ़सेट से बदल दिया जाएगा।dwका अर्थ है कि लोड की चौड़ाई एक डबल-वर्ड (double-word) है, जो 64 बिट्स या 8 बाइट्स होती है।
प्रत्येक प्रयोग में मेमोरी से रजिस्टर में वैल्यू लोड करने के लिए नीचे दिए गए कोड की तरह संरचित एक assembly प्रोग्राम का उपयोग करना चाहिए। इस उदाहरण में उपयोग किए गए रजिस्टर स्वैच्छिक (arbitrary) हैं; कोई भी रजिस्टर काम करेगा। हम यहाँ r1 का उपयोग करते हैं क्योंकि इसमें एंट्री के समय instruction input होता है, जबकि r2 का कोई विशेष अर्थ नहीं है और इसका उपयोग केवल प्रदर्शन (demonstration) के लिए किया जाता है।
ldxdw r2, [r1 + offset]
exit
यह प्रोग्राम मेमोरी एड्रेस [r1 + offset] से 8 बाइट्स को रजिस्टर r2 में लोड करता है, और फिर बाहर (exit) निकल जाता है। रजिस्टर r1, 0x400000000 पर सीरियलाइज़्ड instruction input की शुरुआत को इंगित करता है। हम उस offset को उस वास्तविक बाइट ऑफ़सेट से बदल देंगे जिसे हम मेमोरी में पढ़ रहे हैं।
यह देखने के लिए कि ldxdw instruction मेमोरी से वैल्यू कैसे लोड करता है, नीचे दिखाए गए instruction input serialization layout के इस हिस्से पर विचार करें:

इस लेआउट में, account count (Num Accounts) ऑफ़सेट 0x00 से शुरू होता है, और duplicate flag ऑफ़सेट 0x08 से शुरू होता है। प्रत्येक वैल्यू को लोड करने के लिए, offset को फील्ड के बाइट ऑफ़सेट से बदलें, और VM उस स्थान से पढ़ता है जो r1 में संग्रहीत इनपुट बेस (input base) के सापेक्ष (relative) होता है।
EVM के विपरीत जहाँ instruction inputs को calldata से एक्सेस किया जाता है, Solana निष्पादन (execution) शुरू होने से पहले instruction inputs को मेमोरी में लोड करता है। व्यवहार में यह इस प्रकार काम करता है:
- Account count पढ़ने के लिए, ऑफ़सेट
0x00का उपयोग करें और इसेldxdw r2, [r1 + 0x00]के साथ मेमोरी सेr2में लोड करें। यह एड्रेस0x400000000(0x400000000 + 0) से पढ़ता है। यदि instruction में दो accounts हैं, तोr2में2होगा। - Duplicate flag पढ़ने के लिए, ऑफ़सेट
0x08का उपयोग करें और इसेldxdw r2, [r1 + 0x08]के साथ लोड करें। यह एड्रेस0x400000008(0x400000000 + 8) से पढ़ता है, जहाँ से फ्लैग फील्ड शुरू होता है।
इस पूरे लेख में, हम मेमोरी रीजन के विभिन्न हिस्सों का निरीक्षण करने के लिए अलग-अलग ऑफ़सेट वैल्यूज़ का उपयोग करेंगे जहाँ रनटाइम ने सीरियलाइज़्ड instruction inputs को संग्रहीत किया है।
अब जब हमने यह समझने की नींव रख दी है कि ldxdw instruction का उपयोग करके मेमोरी से कैसे पढ़ा जाए, तो आइए अपना टेस्ट डेटा (test data) बनाएं।
टेस्ट इनपुट सेट करना (Setting up test input)
हम accounts array में एक ही account के साथ एक टेस्ट ट्रांजेक्शन instruction बनाएंगे, जिसका ओनर (owner) BPF Loader है। इससे हमें यह दर्शाने में मदद मिलेगी कि VM सीरियलाइज़्ड instruction input को कैसे पढ़ता है।
नीचे दिए गए टेस्ट डेटा में शामिल हैं:
- निम्नलिखित प्रारूप (format) के साथ एक accounts array:
- public key
- owner
- Account flags: not a signer, writable, not executable
- 1,000 lamports बैलेंस
- account data के 4 बाइट्स:
[0, 0, 0, 3]
- एक program ID
- instruction data के 4 बाइट्स:
[2, 0, 0, 0]
यहाँ टेस्ट डेटा दिया गया है, इसे src/instructions.json में पेस्ट करें। रनटाइम इसका उपयोग instruction को मेमोरी में लोड करने के लिए करेगा। इस पूरे ट्यूटोरियल में, हम जांचेंगे कि sBPF VM मेमोरी से instruction को कैसे पढ़ता है।
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
"program_id": "HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC",
"instruction_data": [2, 0, 0, 0]
}
नीचे एक त्वरित अनुस्मारक (quick reminder) है कि agave-ledger-tool को कैसे चलाया जाए।
हमारा assembly कोड चलाना
हम अपने assembly कोड को चलाने और प्रत्येक instruction के बाद रजिस्टर स्टेट्स (register states) को ट्रेस करने के लिए agave-ledger-tool का उपयोग करेंगे। यह टूल आपके Solana development installation के साथ पहले से इंस्टॉल आता है।
agave-ledger-tool निष्पादन ट्रेसेस (execution traces) उत्पन्न करता है जो रजिस्टर स्टेट ट्रांज़िशन (register state transitions) दिखाते हैं। चूंकि हम सीधे मेमोरी सामग्री (memory contents) नहीं देख सकते हैं, इसलिए हम मेमोरी से वैल्यूज़ को रजिस्टरों में कॉपी करेंगे और ट्रेस आउटपुट (trace output) में उन रजिस्टरों का निरीक्षण करेंगे।
नीचे agave-ledger-tool कमांड दी गई है जिसका उपयोग हम अपने assembly प्रोग्राम्स को निष्पादित करने के लिए करेंगे। यह हमारे प्रोग्राम को 200,000 compute unit लिमिट के साथ निष्पादित करेगा, रजिस्टर स्टेट्स दिखाने वाली एक ट्रेस फाइल (trace file) लिखेगा, हमारे लोकल टेस्ट लेज़र (test ledger) का उपयोग करेगा, और हमारी instructions.json फाइल से इनपुट लेगा:
agave-ledger-tool program run inputs/inputs.asm --limit 200000 --trace inputs/trace.txt --ledger test-ledger --input inputs/instructions.json
हमारे टेस्ट इनपुट में account count पढ़ना
हमारे द्वारा पहले दिखाए गए serialization format आरेख के अनुसार, पहले 8 बाइट्स में 0x00 के ऑफ़सेट के साथ accounts की संख्या होती है। हमारे इनपुट पैरामीटर की accounts सूची में केवल एक account है:
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
... // other input parameters
}
इसे प्रदर्शित करने के लिए, अपने assembly प्रोग्राम में offset को 0x00 से बदलें। यह एड्रेस r1 + 0x00 (यानी, 0x400000000) से 8 बाइट्स को r2 में लोड करता है। r2 का चुनाव स्वैच्छिक है, यहाँ किसी भी अन्य आर्गुमेंट रजिस्टर (argument register) का उपयोग किया जा सकता है।
ldxdw r2, [r1 + 0x00]
exit
agave-ledger-tool कमांड का उपयोग करके प्रोग्राम चलाएं, फिर निष्पादन ट्रेस (execution trace) देखने के लिए inputs/trace.txt खोलें:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x0]
1 [0000000000000000, 0000000400000000, 0000000000000001, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
ट्रेस प्रत्येक instruction से पहले और बाद में रजिस्टर स्टेट्स दिखाता है। ऐरे (array) रजिस्टरों को क्रम में प्रदर्शित करता है: [r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10]।

Line 0 प्रारंभिक अवस्था (initial state) दिखाती है: r1 में 0x400000000 (इनपुट बेस एड्रेस) है और r2 शून्य (zero) है।
Line 1 ldxdw r2, [r1+0x0] instruction निष्पादन के बाद की स्थिति दिखाती है: r2 में अब 1 (0000000000000001) है, जो हमारे ट्रांजेक्शन इनपुट में accounts की संख्या है।
Account flags और padding region पढ़ना
अगले 8 बाइट्स, जो ऑफ़सेट 0x08 से शुरू होते हैं, में 4 वन-बाइट (one-byte) फ्लैग्स और उसके बाद 4 बाइट्स की पैडिंग (padding) होती है जैसा कि नीचे दिए गए आरेख में दिखाया गया है। चूंकि रजिस्टर 8 बाइट्स धारण करते हैं, इसलिए हम सभी फ्लैग्स और पैडिंग को एक साथ एक रजिस्टर में लोड करेंगे।
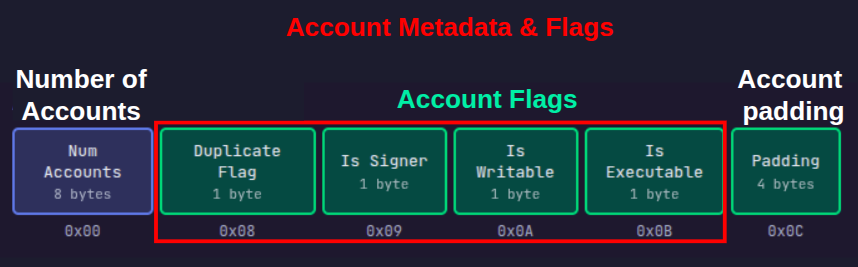
Duplicate flag ऑफ़सेट 0x08 पर एक सिंगल बाइट है जिसके निम्नलिखित गुण हैं:
- यदि account यूनिक (unique) है, तो duplicate flag
0xFFबाइट होगा। - यदि account, accounts array में किसी पहले के account का डुप्लिकेट है, तो duplicate flag मूल (original) account का इंडेक्स (index) होना चाहिए।
हमारे टेस्ट ट्रांजेक्शन डेटा में केवल एक ही account है, इसलिए यह डुप्लिकेट नहीं हो सकता।
हम ldxdw r2, [r1 + offset] instruction का उपयोग करके इन फ्लैग्स को रजिस्टरों में लोड करके मेमोरी में इनकी सामग्री देख सकते हैं। offset वेरिएबल को उस ऑफ़सेट से बदल दें जहाँ से हम पढ़ना शुरू करना चाहते हैं।
आइए दिखाएं कि duplicate flag की वैल्यू 0xFF है (जो एक यूनिक account को दर्शाता है):
ldxdw r2, [r1 + 0x08]
exit
याद रखें कि ldxdw 8 बाइट्स लोड करता है, न कि केवल 1 बाइट। इसलिए भले ही duplicate flag ऑफ़सेट 0x08 पर केवल पहला बाइट है, यह instruction duplicate flag के साथ-साथ उसके बाद आने वाले 7 बाइट्स को भी r2 में लोड करेगा। इसका मतलब है कि हम अन्य account flags और पैडिंग भी देखेंगे जो 0x08 से 0x0F तक के ऑफ़सेट पर स्थित हैं।
प्रोग्राम चलाएं और src/trace.txt चेक करें:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x8]
1 [0000000000000000, 0000000400000000, **00000000000100FF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
ट्रेस दिखाता है कि रजिस्टर r2 में अब 00000000000100FF है (little-endian प्रारूप में—सबसे दायां बाइट FF सबसे निचले मेमोरी एड्रेस 0x08 पर है), इसलिए हम हाइलाइट किए गए बाइट्स को उल्टे क्रम (reverse) में पढ़ेंगे, जिसका अर्थ है:
FF(बाइट 0, ऑफ़सेट0x08): duplicate flag,0xFFका अर्थ है कि यह डुप्लिकेट नहीं है00(बाइट 1, ऑफ़सेट0x09): account एक signer नहीं है। हमारे ट्रांजेक्शन में, हमने इसेfalseपर सेट किया है जिसका अनुवाद0में होता है01(बाइट 2, ऑफ़सेट0x0A): account رائटेबल (writable) है। हमारे ट्रांजेक्शन में, हमने इसेtrueपर सेट किया है जिसका अनुवाद1में होता है00(बाइट 3, ऑफ़सेट0x0B): account एक्जीक्यूटेबल (executable) नहीं है। हमने इसे सेट नहीं किया है, यह डिफ़ॉल्ट रूप सेfalseहोता है00000000(बाइट्स 4-7, ऑफ़सेट0x0C-0x0F): account padding
Account public key पढ़ना
सीरियलाइज़्ड instruction input के अगले 32 बाइट्स में account की public key होती है, जिसके बाद owner की public key के लिए अगले 32 बाइट्स होते हैं (जिनकी चर्चा अगले भाग में की गई है)।
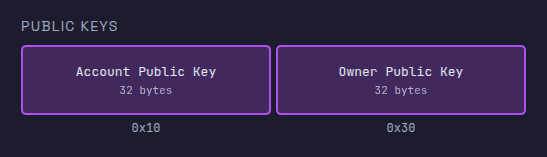
एक रजिस्टर में 8 बाइट्स होते हैं। चूंकि हम 8 बाइट्स से अधिक लोड करने का प्रयास कर रहे हैं, इसलिए हमें कई रजिस्टरों का उपयोग करना होगा। हम account public key को रजिस्टरों r2, r3, r4 और r5 में चार चंक्स (chunks) में लोड करेंगे।
नीचे दिया गया प्रोग्राम मेमोरी से रजिस्टरों में चार 8-बाइट चंक्स लोड करता है। src/inputs.asm की सामग्री को निम्नलिखित कोड से बदलें:
ldxdw r2, [r1+16] ; Load bytes 16-23 (first 8 bytes of public key) into r2
ldxdw r3, [r1+24] ; Load bytes 24-31 (next 8 bytes) into r3
ldxdw r4, [r1+32] ; Load bytes 32-39 (next 8 bytes) into r4
ldxdw r5, [r1+40] ; Load bytes 40-47 (last 8 bytes) into r5
exit
agave-ledger-tool के साथ प्रोग्राम चलाएं। ट्रेस फाइल में अब यह सामग्री होनी चाहिए:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x10]
1 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x18]
2 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x20]
3 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x28]
4 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 1B20575E7D084725, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
याद रखें कि नीचे दी गई स्ट्रिंग (string) वह public key है जो हमारे पास instructions.json फाइल में है, जिसे मेमोरी में स्टोर किया जा रहा है और रजिस्टरों में लोड किया जा रहा है।
524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca
यदि हम public key को उसके मूल base58 प्रारूप से हेक्स (hex) में परिवर्तित करते हैं, तो हमारे पास यह होगा:
3BB40A1B35AE44FAB6C5407D140DF5823FD193BD415214352547087D5E57201B
हम इसे प्रत्येक रजिस्टर के लिए 8-बाइट्स में विभाजित करेंगे क्योंकि प्रत्येक रजिस्टर यही स्टोर कर सकता है। हमें यह मिलेगा:
0x3bb40a1b35ae44fa 0xb6c5407d140df582 0x3fd193bd41521435 0x2547087d5e57201b
रजिस्टर वैल्यूज़ को little-endian क्रम में प्रदर्शित/व्याख्यायित (displayed/interpreted) किया जाता है, इसलिए 8-बाइट चंक्स नीचे दिखाए गए अनुसार दिखाई देते हैं।
FA44AE351B0AB43B 82F50D147D40C5B6 35145241BD93D13F 1B20575E7D084725
आइए प्रत्येक चरण (step) को ट्रेस करें:

- Line 0: किसी भी लोड से पहले की प्रारंभिक अवस्था। सभी रजिस्टर (
r0-r10) दिखाए गए हैं, जिसमेंr1में0000000400000000(MM_INPUT_START) है। - Line 1:
ldxdw r2, [r1+16]निष्पादित करने के बाद, रजिस्टरr2(तीसरे स्थान पर) में अबFA44AE351B0AB43B(little-endian प्रारूप में public key के पहले 8 बाइट्स) है। - Line 2:
ldxdw r3, [r1+24]निष्पादित करने के बाद, रजिस्टरr3(चौथे स्थान पर) में अब82F50D147D40C5B6(अगले 8 बाइट्स) है। - Line 3:
ldxdw r4, [r1+32]निष्पादित करने के बाद, रजिस्टरr4(पांचवें स्थान पर) में अब35145241BD93D13F(अगले 8 बाइट्स) है। - Line 4:
ldxdw r5, [r1+40]निष्पादित करने के बाद, रजिस्टरr5(छठे स्थान पर) में अब1B20575E7D084725(अंतिम 8 बाइट्स) है।
प्रत्येक रजिस्टर (r2, r3, r4, r5) की हमारे अपेक्षित हेक्स (hex) वैल्यूज़ से तुलना करने पर पता चलता है कि वे पूरी तरह से मेल खाते हैं।
Owner public key पढ़ना
Owner public key account public key के बाद ऑफ़सेट 0x30 (डेसिमल में 48) से शुरू होती है और 32 बाइट्स तक फैली होती है। चूंकि प्रत्येक ldxdw instruction 8 बाइट्स लोड करता है, इसलिए आपको पूरी key पढ़ने के लिए चार लोड्स की आवश्यकता होती है। हमारे उदाहरण में owner BPFLoaderUpgradeab1e11111111111111111111111 है।
आइए इसे नीचे दिए गए कोड से प्रदर्शित करें। src/inputs.asm को अपडेट करें:
ldxdw r2, [r1+48] ; Load bytes 48-55 (first 8 bytes of owner public key) into r2
ldxdw r3, [r1+56] ; Load bytes 56-63 (next 8 bytes) into r3
ldxdw r4, [r1+64] ; Load bytes 64-71 (next 8 bytes) into r4
ldxdw r5, [r1+72] ; Load bytes 72-79 (last 8 bytes) into r5
exit
कोड चलाएं। ट्रेस दिखाता है कि प्रत्येक रजिस्टर अपना 8-बाइट चंक लोड कर रहा है:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x30]
1 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x38]
2 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x40]
3 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x48]
4 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 00008004107A53C0, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
जब आप owner एड्रेस BPFLoaderUpgradeab1e11111111111111111111111 को हेक्स (hex) में बदलते हैं और इसे 8-बाइट little-endian चंक्स में विभाजित करते हैं, तो आपको मिलता है:
B0A1884E91F6A802 2BAE63F73E1510E2 D224C1163DB9C200 00008004107A53C0
ये वैल्यूज़ ट्रेस में रजिस्टर r2 से r5 में दिखाई देने वाली वैल्यूज़ से मेल खाती हैं।
Lamports पढ़ना
Owner public key के बाद अगले 8 बाइट्स में account का lamport बैलेंस होता है। lamports फील्ड मेमोरी में ऑफ़सेट 0x50 (डेसिमल में 80) पर स्थित होता है।
आइए lamports फील्ड को एक रजिस्टर में लोड करें और इसका निरीक्षण करें। हमारे assembly प्रोग्राम में ऑफ़सेट के रूप में 0x50 का उपयोग करें:
ldxdw r2, [r1 + 0x50]
exit
प्रोग्राम चलाएं और src/trace.txt चेक करें:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x50]
1 [0000000000000000, 0000000400000000, **00000000000003E8**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
हम देखते हैं कि रजिस्टर r2 में 00000000000003E8 है, जो 1,000 lamports का हेक्स प्रतिनिधित्व (hex representation) है। यह हमारी instructions फाइल में lamports: 1000 वैल्यू से मेल खाता है।
Account data length पढ़ना
Lamports फील्ड के बाद अगले 8 बाइट्स account data की लंबाई (length) होती है, जो ऑफ़सेट 0x58 पर स्थित होती है। ऑफ़सेट 0x58 से पढ़ने के लिए src/inputs.asm को अपडेट करें:
ldxdw r2, [r1 + 0x58]
exit
प्रोग्राम चलाएं और src/trace.txt चेक करें:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x58]
1 [0000000000000000, 0000000400000000, **0000000000000004**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
रजिस्टर r2 में 0000000000000004 है, जो दर्शाता है कि हमारे account में 4 बाइट्स का डेटा है। यह हमारी instructions.json फाइल के data: [0, 0, 0, 3] फील्ड में 4-एलिमेंट ऐरे से मेल खाता है।
Account data पढ़ना
Account data, account data length के तुरंत बाद ऑफ़सेट 0x60 से शुरू होता है। हमारे टेस्ट account में 4 बाइट्स का डेटा है जो 0x60-0x63 ऑफ़सेट्स तक फैला है। इसे दिखाने के लिए, आइए offset 0x60 पर डेटा लोड करें:
ldxdw r2, [r1 + 0x60]
exit
प्रोग्राम चलाएं। ट्रेस दिखाता है:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x60]
1 [0000000000000000, 0000000400000000, **0000000003000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
रजिस्टर r2 में 0000000003000000 है। instruction 8 बाइट्स लोड करता है, लेकिन केवल पहले 4 बाइट्स में आपका वास्तविक डेटा होता है। उन 4 बाइट्स को दाएं से बाएं (little-endian) पढ़ने पर [00, 00, 00, 03] प्राप्त होता है, जो instruction फाइल से data: [0, 0, 0, 3] से मेल खाता है।
Realloc padding पढ़ना
Account data के बाद, रनटाइम प्रोग्राम निष्पादन (पुनः आवंटन या reallocation के माध्यम से) के दौरान संभावित account data वृद्धि के लिए शून्य से भरे (zero-filled) स्थान के 10,240 बाइट्स (10 KiB) आरक्षित करता है।
यह पैडिंग ऑफ़सेट 0x64 (जहाँ हमारा 4-बाइट account data समाप्त होता है) से शुरू होती है और ऑफ़सेट 0x2864 (डेसिमल में 10,340) तक फैली होती है।
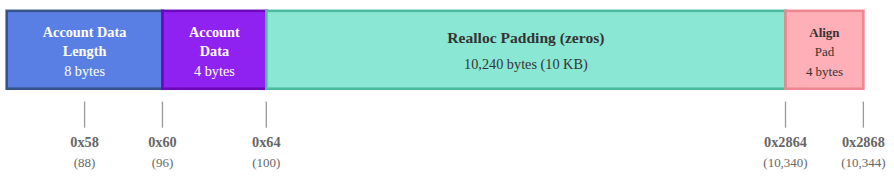
हम मेमोरी से इस रेंज के भीतर एक रैंडम (random) ऑफ़सेट को रजिस्टर में लोड करके इसे दिखा सकते हैं। आइए ऑफ़सेट 0x1388 की जांच करें:
ldxdw r2, [r1 + 0x1388]
exit
प्रोग्राम चलाएं। रजिस्टर r2 में 0000000000000000 होना चाहिए, जो यह दर्शाता है कि यह रीजन शून्य (zeros) से भरा है।
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x1388]
1 [0000000000000000, 0000000400000000, **0000000000000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
Alignment padding पढ़ना
10k realloc पैडिंग के बाद, अगला फील्ड 8-बाइट बाउंड्री (boundary) पर शुरू होना चाहिए। realloc पैडिंग ऑफ़सेट 0x2864 (10340) पर समाप्त होती है। क्योंकि यह ऑफ़सेट 8-बाइट अलाइन (aligned) नहीं है, रनटाइम 4 बाइट्स की alignment padding जोड़कर इसे 10344 तक राउंड अप (round up) करता है।
Realloc पैडिंग और अगले फील्ड के बीच की बाउंड्री पर मेमोरी सामग्री (memory contents) की जांच करने के लिए, आइए ऑफ़सेट 0x2864 से r2 में लोड करें और ट्रेस का निरीक्षण करें।
ldxdw r2, [r1 + 0x2864]
exit
ट्रेस को रजिस्टर r2 में FFFFFFFF00000000 दिखाना चाहिए:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2864]
1 [0000000000000000, 0000000400000000, FFFFFFFF00000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
Little-endian रूप में FFFFFFFF00000000, बाइट्स 00 00 00 00 FF FF FF FF से मेल खाता है। हमारा ldxdw instruction दो फील्ड्स के पार (across) पढ़ता है: पहले चार शून्य बाइट्स alignment padding हैं, और अगले चार FF बाइट्स rent epoch फील्ड की शुरुआत हैं। जिसकी चर्चा हम आगे करेंगे।
Rent epoch पढ़ना
Alignment padding के बाद अगले 8 बाइट्स में account के लिए rent epoch होता है।
व्यवहार में, Solana में accounts rent-exempt (किराया-मुक्त) बनाए जाते हैं, इसलिए rent epoch फील्ड को FFFFFFFFFFFFFFFF के रूप में एन्कोड की गई डिफ़ॉल्ट rent-exempt वैल्यू पर सेट किया जाता है।
इसे दिखाने के लिए, हम ऑफ़सेट 10344 (0x2868) से rent epoch को लोड करेंगे, जो r2 में rent epoch रीजन की शुरुआत है।
ldxdw r2, [r1 + 0x2868]
exit
इसे चलाने पर यह दिखना चाहिए:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2868]
1 [0000000000000000, 0000000400000000, **FFFFFFFFFFFFFFFF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
रजिस्टर r2 में FFFFFFFFFFFFFFFF है।
Instruction data length पढ़ना
Rent epoch के बाद अगले 8 बाइट्स में ऑफ़सेट 10352 पर instruction data की लंबाई (length) होती है। हमारे टेस्ट ट्रांजेक्शन में instruction data के 4 बाइट्स शामिल हैं। offset को 10352 से बदलें:
ldxdw r2, [r1 + 10352]
exit
जब आप कोड चलाते हैं तो इसे यह ट्रेस उत्पन्न करना चाहिए:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2870]
1 [0000000000000000, 0000000400000000, 0000000000000004, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
रजिस्टर r2 में 0000000000000004 है, जो दर्शाता है कि instruction data ऐरे (array) में 4 बाइट्स हैं जैसा कि हमारी instructions.json फाइल में निर्दिष्ट है।
Instruction data पढ़ना
ऑफ़सेट 10360 से शुरू होने वाले अगले बाइट्स में instruction data होता है। हमारे टेस्ट में 4 बाइट्स शामिल हैं: [2, 0, 0, 0], (लेकिन यह लंबाई प्रति ट्रांजेक्शन भिन्न होती है)। इसका निरीक्षण करने के लिए offset को 10360 (हेक्स में 0x2878) से बदलें:
ldxdw r2, [r1 + 0x2878]
exit
जब आप इसे चलाते हैं तो कोड यह ट्रेस उत्पन्न करता है:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2878]
1 [0000000000000000, 0000000400000000, **BA2D9AF400000002**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
रजिस्टर r2 में BA2D9AF400000002 है। चूंकि ldxdw 8 बाइट्स लोड करता है लेकिन instruction data केवल 4 बाइट्स लंबा है, इसलिए इस रीड (read) में निम्नलिखित फील्ड के पहले 4 बाइट्स भी शामिल हैं। निचले 32 बिट्स (00000002) little-endian प्रारूप में हमारे instruction data [2, 0, 0, 0] का प्रतिनिधित्व करते हैं।
Program ID पढ़ना
अंतिम 32 बाइट्स में इन्वोक (invoke) किए जा रहे प्रोग्राम की program ID होती है। चूंकि हमारा instruction data 4 बाइट्स लंबा है, यह 10360- 10363 ऑफ़सेट लेता है। Program ID इसके तुरंत बाद ऑफ़सेट 10364 (हेक्स में 0x287C) पर शुरू होती है।
इसका निरीक्षण करने के लिए, हम सभी 32 बाइट्स को चार रजिस्टरों में लोड कर सकते हैं:
ldxdw r2, [r1+10364]
ldxdw r3, [r1+10372]
ldxdw r4, [r1+10380]
ldxdw r5, [r1+10388]
exit
प्रोग्राम चलाएं और ट्रेस फाइल चेक करें:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 29: ldxdw r2, [r1+0x287c]
1 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 30: ldxdw r3, [r1+0x2884]
2 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 31: ldxdw r4, [r1+0x288c]
3 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 32: ldxdw r5, [r1+0x2894]
4 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, B7CFB5A9E7B8C99A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 33: exit
चारों रजिस्टरों में little-endian प्रारूप में संपूर्ण program ID होती है। Program ID के पुनर्निर्माण (reconstruct) के लिए, हम प्रत्येक रजिस्टर वैल्यू के बाइट क्रम को उलट देते हैं और उन्हें कॉन्कैटिनेट (concatenate/जोड़ते) करते हैं:
- r2:
C512BA35BA2D9AF4→F49A2DBA35BA12C5 - r3:
08D0A2FB506C1A71→711A6C50FBA2D008 - r4:
93EAF43A2BD4867A→7A86D42B3AF4EA93 - r5:
B7CFB5A9E7B8C99A→9AC9B8E7A9B5CFB7
इन्हें जोड़ने (Concatenating) पर हमें हेक्स में 0xf49a2dba35ba12c5711a6c50fba2d0087a86d42b3af4ea939ac9b8e7a9b5cfb7 मिलता है, जो base58 में HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC में डिकोड (decode) होता है। यह हमारी instructions.json फाइल के program_id फील्ड से मेल खाता है।
खाली accounts array या instruction data के साथ परीक्षण
जब किसी ट्रांजेक्शन में खाली accounts array होता है या कोई instruction data नहीं होता है, तो VM केवल काउंट फील्ड्स (account count और instruction data length) के लिए स्थान आरक्षित करता है, जो दोनों 0 होंगे। हम अगले लेख में वास्तविक उदाहरणों के साथ इसका प्रदर्शन करेंगे, जहाँ हम syscalls पर चर्चा करेंगे।
यह लेख Solana development पर एक ट्यूटोरियल श्रृंखला का हिस्सा है।