在上一篇教程中,我们介绍了 sBPF 内存布局,并解释了程序执行期间各个寄存器的用途。
在本教程中,我们将演示如何使用 sBPF 汇编读取账户公钥 (account keys)、程序 ID (program ID) 和指令数据 (instruction data) 等指令输入字段。在此过程中,我们将观察它们在内存中的布局方式。
编写汇编代码从 sBPF 内存中读取数据
当 Solana 程序运行时,运行时 (runtime) 会将程序的指令输入(账户、指令数据、程序 ID)序列化,并将它们加载到从 0x400000000 开始的输入内存区域中。
我们将编写简单的汇编程序,将数据从该输入内存区域读取到寄存器中。
环境准备
创建一个名为 assembly-experiment 的新文件夹。在该文件夹中打开终端并运行 solana-test-validator。这会启动一个本地 Solana 集群,并创建一个 test-ledger 目录来存储账本数据。
在 assembly-experiment 目录中创建以下文件夹和文件:
- 一个
src文件夹,用于存放你的汇编程序和追踪输出 (trace output) - 一个
src/inputs.asm文件,用于编写汇编代码 - 一个
src/instructions.json文件,用于存放将被序列化并发送到程序的交易数据
创建好文件夹和文件后,assembly-experiment 文件夹的结构应如下所示:
assembly-experiment/
├── test-ledger/
└── src/
├── inputs.asm
└── instructions.json
指令序列化布局参考图
还记得上一篇教程中的指令序列化图吗?它映射了内存中每个序列化字段的字节偏移量。我们将使用这些偏移量在汇编代码中从输入区域读取特定的数据。

使用 ldxdw 指令将数据从内存加载到寄存器
在我们的汇编程序中,我们将使用 sBPF 指令 ldxdw 从内存加载数据。该指令执行索引加载 (indexed load),其中最终地址由基址寄存器加上偏移量计算得出。
以下是该指令各部分的含义:
ldx表示使用寄存器加偏移量来计算地址以从内存中加载(索引加载)。例如:[r1 + offset]。offset变量将被替换为序列化输入中特定字段的偏移量。dw表示加载的宽度为双字 (double-word),即 64 位或 8 字节。
每次实验都必须使用结构类似于下方代码的汇编程序,将值从内存加载到寄存器中。本示例中使用的寄存器是任意的;任何寄存器都可以。我们在这里使用 r1,因为它在入口处包含指令输入,而 r2 没有特殊含义,仅用于演示。
ldxdw r2, [r1 + offset]
exit
该程序将 8 个字节从内存地址 [r1 + offset] 加载到寄存器 r2 中,然后退出。寄存器 r1 指向位于 0x400000000 的序列化指令输入的起始位置。我们将把 offset 替换为我们要读取的内存中任何字段的实际字节偏移量。
要了解 ldxdw 指令如何从内存中加载值,请参考如下所示的指令输入序列化布局的一部分:

在此布局中,账户数量 (Num Accounts) 从偏移量 0x00 开始,重复标志 (duplicate flag) 从偏移量 0x08 开始。要加载每个值,请将 offset 替换为对应字段的字节偏移量,VM 就会相对于存储在 r1 中的输入基址从该位置进行读取。
与 EVM 中从 calldata 访问指令输入不同,Solana 在执行开始之前将指令输入加载到内存中。以下是实际操作中的工作原理:
- 要读取账户数量,请使用偏移量
0x00,并通过ldxdw r2, [r1 + 0x00]将其从内存加载到r2。这会从地址0x400000000(0x400000000 + 0)读取数据。如果指令包含两个账户,r2将包含2。 - 要读取重复标志,请使用偏移量
0x08,并通过ldxdw r2, [r1 + 0x08]进行加载。这会从地址0x400000008(0x400000000 + 8)读取,这也是标志字段开始的位置。
在本文中,我们将使用不同的偏移量值来检查运行时存储序列化指令输入的内存区域的各个部分。
既然我们已经奠定了使用 ldxdw 指令从内存中读取数据的基础,接下来让我们创建测试数据。
设置测试输入
我们将创建一个测试交易指令,该指令的账户数组中包含一个由 BPF Loader 拥有的账户。这将帮助我们说明 VM 是如何读取序列化指令输入的。
下方的测试数据包括:
- 一个具有以下格式的账户数组:
- 公钥 (public key)
- 所有者 (owner)
- 账户标志 (Account flags):不是签名者 (not a signer)、可写 (writable)、不可执行 (not executable)
- 1,000 lamports 的余额
- 4 字节的账户数据:
[0, 0, 0, 3]
- 一个程序 ID (program ID)
- 4 字节的指令数据:
[2, 0, 0, 0]
这是测试数据,将其粘贴到 src/instructions.json 中。运行时将使用它把指令加载到内存中。在本教程中,我们将研究 sBPF VM 是如何从内存中读取该指令的。
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
"program_id": "HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC",
"instruction_data": [2, 0, 0, 0]
}
下面是关于如何运行 agave-ledger-tool 的快速提示。
运行我们的汇编代码
我们将使用 agave-ledger-tool 来运行我们的汇编代码,并在每条指令执行后追踪寄存器状态。该工具在你的 Solana 开发环境安装中已经预装。
agave-ledger-tool 会生成显示寄存器状态转换的执行追踪记录。由于我们无法直接查看内存内容,我们将把内存中的值复制到寄存器中,并在追踪输出中检查这些寄存器的状态。
下面是我们将用于执行汇编程序的 agave-ledger-tool 命令。它将以 200,000 计算单元的限制来执行我们的程序,写入一个显示寄存器状态的追踪文件,使用我们的本地测试账本,并从 instructions.json 文件中获取输入:
agave-ledger-tool program run inputs/inputs.asm --limit 200000 --trace inputs/trace.txt --ledger test-ledger --input inputs/instructions.json
读取测试输入中的账户数量
根据我们前面展示的序列化格式图,前 8 个字节包含了账户数量,其偏移量为 0x00。我们的输入参数在 accounts 列表中仅包含一个账户:
{
"accounts": [
{
"key": "524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca",
"owner": "BPFLoaderUpgradeab1e11111111111111111111111",
"is_signer": false,
"is_writable": true,
"lamports": 1000,
"data": [0, 0, 0, 3]
}
],
... // other input parameters
}
为了演示这一点,请在汇编程序中将 offset 替换为 0x00。这会将地址 r1 + 0x00(即 0x400000000)处的 8 个字节加载到 r2 中。选择 r2 是任意的,这里可以使用任何其他参数寄存器。
ldxdw r2, [r1 + 0x00]
exit
使用 agave-ledger-tool 命令运行程序,然后打开 inputs/trace.txt 以查看执行追踪记录:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x0]
1 [0000000000000000, 0000000400000000, 0000000000000001, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
追踪记录显示了每条指令执行前后的寄存器状态。该数组按顺序显示了各个寄存器:[r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10]。

第 0 行显示了初始状态: r1 保存着 0x400000000(输入基址),而 r2 为零。
第 1 行显示了 ldxdw r2, [r1+0x0] 指令执行后的状态: r2 现在包含 1(0000000000000001),即我们交易输入中的账户数量。
读取账户标志和填充区域
接下来的 8 个字节(从偏移量 0x08 开始)包含 4 个单字节标志,紧接着是 4 个字节的填充 (padding),如下图所示。由于寄存器能够容纳 8 字节,我们将把所有的标志和填充一次性加载到一个寄存器中。
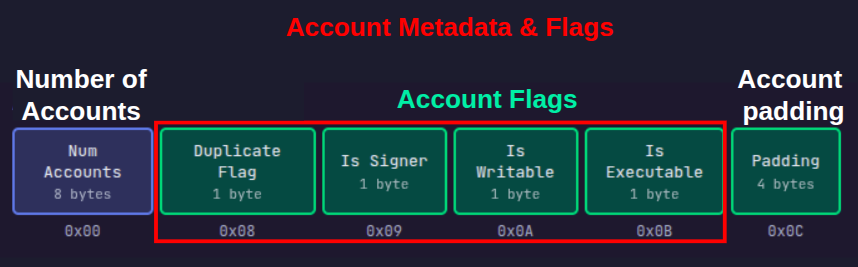
重复标志是偏移量为 0x08 处的单个字节,具有以下属性:
- 如果该账户是唯一的,重复标志将是
0xFF字节。 - 如果该账户是账户数组中较早前账户的重复项,则重复标志应为原始账户的索引。
我们的测试交易数据只有一个账户,因此它不可能是重复的。
我们可以通过使用 ldxdw r2, [r1 + offset] 指令将这些标志加载到寄存器中来查看它们在内存中的内容。将 offset 变量替换为我们打算开始读取的偏移量。
让我们来证明重复标志的值为 0xFF(表示唯一的账户):
ldxdw r2, [r1 + 0x08]
exit
请记住,ldxdw 加载的是 8 个字节,而不仅仅是 1 个字节。所以,即使重复标志仅仅是偏移量 0x08 处的第一个字节,该指令也会将重复标志及其后面的 7 个字节加载到 r2 中。这意味着我们也将看到占据偏移量 0x08 到 0x0F 的其他账户标志和填充。
运行程序并检查 src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x8]
1 [0000000000000000, 0000000400000000, **00000000000100FF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
追踪记录显示寄存器 r2 现在包含 00000000000100FF(小端格式——最右侧的字节 FF 位于最低的内存地址 0x08 处),因此我们将倒序读取高亮显示的字节,这意味着:
FF(字节 0,偏移量0x08):重复标志,0xFF表示它不是重复项00(字节 1,偏移量0x09):账户不是签名者。在我们的交易中,我们将其设置为false,这转换为001(字节 2,偏移量0x0A):账户是可写的。在我们的交易中,我们将其设置为true,这转换为100(字节 3,偏移量0x0B):账户不可执行。我们没有设置此项,它默认为false00000000(字节 4-7,偏移量0x0C-0x0F):账户填充
读取账户公钥
序列化指令输入的接下来的 32 个字节包含了账户的公钥,紧接着的 32 个字节是所有者 (owner) 的公钥(将在下一节中讨论)。
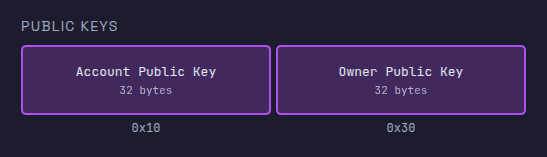
一个寄存器可容纳 8 个字节。由于我们要加载的内容超过 8 个字节,因此必须使用多个寄存器。我们将分四个块把账户公钥分别加载到寄存器 r2、r3、r4 和 r5 中。
下面的程序将四个 8 字节块从内存加载到寄存器中。用以下代码替换 src/inputs.asm 的内容:
ldxdw r2, [r1+16] ; Load bytes 16-23 (first 8 bytes of public key) into r2
ldxdw r3, [r1+24] ; Load bytes 24-31 (next 8 bytes) into r3
ldxdw r4, [r1+32] ; Load bytes 32-39 (next 8 bytes) into r4
ldxdw r5, [r1+40] ; Load bytes 40-47 (last 8 bytes) into r5
exit
使用 agave-ledger-tool 运行该程序。此时,追踪文件应该有以下内容:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x10]
1 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x18]
2 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x20]
3 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x28]
4 [0000000000000000, 0000000400000000, FA44AE351B0AB43B, 82F50D147D40C5B6, 35145241BD93D13F, 1B20575E7D084725, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
记住,下面的字符串就是我们在 instructions.json 文件中公钥,它已被存储到内存中并被加载到各个寄存器。
524HMdYYBy6TAn4dK5vCcjiTmT2sxV6Xoue5EXrz22Ca
如果我们将公钥从原始的 base58 格式转换为十六进制 (hex),我们会得到:
3BB40A1B35AE44FAB6C5407D140DF5823FD193BD415214352547087D5E57201B
我们将把它按每份 8 字节进行拆分,以对应每个寄存器可以存储的大小。我们将得到:
0x3bb40a1b35ae44fa 0xb6c5407d140df582 0x3fd193bd41521435 0x2547087d5e57201b
寄存器值以小端 (little-endian) 顺序显示和解释,因此 8 字节块的呈现方式如下所示。
FA44AE351B0AB43B 82F50D147D40C5B6 35145241BD93D13F 1B20575E7D084725
让我们逐个步骤进行追踪:

- 第 0 行:任何加载操作之前的初始状态。显示了所有寄存器(
r0-r10),其中r1包含0000000400000000(MM_INPUT_START)。 - 第 1 行:执行
ldxdw r2, [r1+16]后,寄存器r2(第三个位置)现在包含FA44AE351B0AB43B(公钥前 8 个字节的小端格式)。 - 第 2 行:执行
ldxdw r3, [r1+24]后,寄存器r3(第四个位置)现在包含82F50D147D40C5B6(接下来的 8 个字节)。 - 第 3 行:执行
ldxdw r4, [r1+32]后,寄存器r4(第五个位置)现在包含35145241BD93D13F(接下来的 8 个字节)。 - 第 4 行:执行
ldxdw r5, [r1+40]后,寄存器r5(第六个位置)现在包含1B20575E7D084725(最后的 8 个字节)。
将各个寄存器(r2、r3、r4、r5)与我们预期的十六进制值进行对比,可以看到它们完全匹配。
读取所有者公钥
所有者公钥紧随账户公钥之后,从偏移量 0x30(十进制 48)开始,占据 32 个字节。由于每条 ldxdw 指令加载 8 个字节,因此你需要进行四次加载才能读取完整的公钥。本示例中的所有者是 BPFLoaderUpgradeab1e11111111111111111111111
让我们用下面的代码来演示这一点。更新 src/inputs.asm:
ldxdw r2, [r1+48] ; Load bytes 48-55 (first 8 bytes of owner public key) into r2
ldxdw r3, [r1+56] ; Load bytes 56-63 (next 8 bytes) into r3
ldxdw r4, [r1+64] ; Load bytes 64-71 (next 8 bytes) into r4
ldxdw r5, [r1+72] ; Load bytes 72-79 (last 8 bytes) into r5
exit
运行该代码。追踪记录会显示每个寄存器分别加载了其对应的 8 字节块:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x30]
1 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: ldxdw r3, [r1+0x38]
2 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 2: ldxdw r4, [r1+0x40]
3 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 3: ldxdw r5, [r1+0x48]
4 [0000000000000000, 0000000400000000, B0A1884E91F6A802, 2BAE63F73E1510E2, D224C1163DB9C200, 00008004107A53C0, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 4: exit
将所有者地址 BPFLoaderUpgradeab1e11111111111111111111111 转换为十六进制并将其分成多个 8 字节小端格式块后,你会得到:
B0A1884E91F6A802 2BAE63F73E1510E2 D224C1163DB9C200 00008004107A53C0
这些值与追踪记录中寄存器 r2 到 r5 中显示的值相匹配。
读取 lamports
所有者公钥之后的接下来 8 个字节包含了该账户的 lamport 余额。lamports 字段位于内存偏移量 0x50(十进制 80)处。
让我们把 lamports 字段加载到寄存器中并进行检查。在我们的汇编程序中使用 0x50 作为偏移量:
ldxdw r2, [r1 + 0x50]
exit
运行程序并检查 src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x50]
1 [0000000000000000, 0000000400000000, **00000000000003E8**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
我们看到寄存器 r2 存放的是 00000000000003E8,它是 1,000 lamports 的十六进制表示。这与我们指令文件中的 lamports: 1000 值相符。
读取账户数据长度
lamports 字段之后接下来的 8 个字节是账户数据的长度,位于偏移量 0x58 处。更新 src/inputs.asm 以从偏移量 0x58 处进行读取:
ldxdw r2, [r1 + 0x58]
exit
运行程序并检查 src/trace.txt:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x58]
1 [0000000000000000, 0000000400000000, **0000000000000004**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
寄存器 r2 包含 0000000000000004,表明我们的账户拥有 4 个字节的数据。这与我们 instructions.json 文件中 data: [0, 0, 0, 3] 字段代表的 4 元素数组相匹配。
读取账户数据
账户数据从偏移量 0x60 开始,紧跟在账户数据长度之后。我们的测试账户包含 4 个字节的数据,占据偏移量 0x60-0x63。为了说明这一点,让我们加载位于 offset 0x60 处的数据:
ldxdw r2, [r1 + 0x60]
exit
运行该程序。追踪记录显示:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x60]
1 [0000000000000000, 0000000400000000, **0000000003000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
寄存器 r2 包含 0000000003000000。该指令加载了 8 个字节,但只有前 4 个字节包含你实际的数据。从右向左读取这 4 个字节(小端格式)可得到 [00, 00, 00, 03],与指令文件中的 data: [0, 0, 0, 3] 匹配。
读取 realloc 填充区域
在账户数据之后,运行时保留了 10,240 字节 (10 KiB) 的零填充空间,以便在程序执行期间支持潜在的账户数据增长(通过重新分配)。
该填充从偏移量 0x64(我们 4 字节账户数据的结束处)开始,一直延伸到偏移量 0x2864(十进制 10,340)。
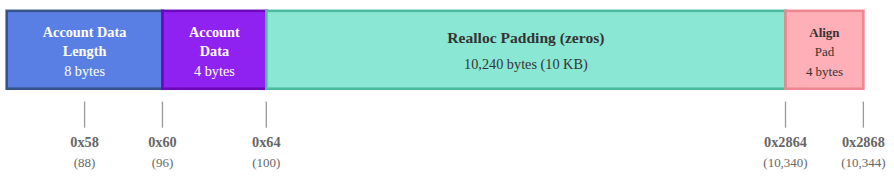
我们可以通过将此范围内的随机偏移量从内存加载到寄存器中来展示这一点。让我们检查偏移量 0x1388:
ldxdw r2, [r1 + 0x1388]
exit
运行程序。寄存器 r2 应该包含 0000000000000000,这表明该区域被零填充。
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x1388]
1 [0000000000000000, 0000000400000000, **0000000000000000**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
读取对齐填充区域
在 10k 的 realloc 填充之后,下一个字段必须从 8 字节的边界开始。realloc 填充在偏移量 0x2864 (10340) 处结束。因为该偏移量不是 8 字节对齐的,运行时会将其向上舍入至 10344,从而添加 4 个字节的对齐填充 (alignment padding)。
要检查 realloc 填充与下一个字段之间边界处的内存内容,让我们从偏移量 0x2864 将数据加载到 r2 中并检查追踪记录。
ldxdw r2, [r1 + 0x2864]
exit
追踪记录应当在寄存器 r2 中显示 FFFFFFFF00000000:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2864]
1 [0000000000000000, 0000000400000000, FFFFFFFF00000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
FFFFFFFF00000000 在小端形式下对应于字节 00 00 00 00 FF FF FF FF。我们的 ldxdw 指令跨越了两个字段读取:前四个零字节是对齐填充,后四个 FF 字节是租金纪元 (rent epoch) 字段的开始。接下来我们将讨论这一点。
读取租金纪元
对齐填充之后的接下来 8 个字节包含该账户的租金纪元 (rent epoch)。
在实践中,Solana 中的账户创建时是免租金的 (rent-exempt),因此租金纪元字段被设置为默认的免租金值,编码为 FFFFFFFFFFFFFFFF。
为了说明这一点,我们将从偏移量 10344(0x2868)也就是租金纪元区域开始的地方将租金纪元加载到 r2 中。
ldxdw r2, [r1 + 0x2868]
exit
运行该代码应该会显示:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2868]
1 [0000000000000000, 0000000400000000, **FFFFFFFFFFFFFFFF**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
寄存器 r2 包含 FFFFFFFFFFFFFFFF。
读取指令数据长度
租金纪元之后的接下来的 8 个字节包含位于偏移量 10352 处的指令数据长度。我们的测试交易包含 4 个字节的指令数据。将 offset 替换为 10352:
ldxdw r2, [r1 + 10352]
exit
运行该代码时将生成如下追踪记录:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2870]
1 [0000000000000000, 0000000400000000, 0000000000000004, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
寄存器 r2 包含 0000000000000004,这表明指令数据数组像我们在 instructions.json 文件中指定的那样有 4 个字节。
读取指令数据
从偏移量 10360 开始的后续字节包含了指令数据。我们的测试包含了 4 个字节:[2, 0, 0, 0](但此长度因交易而异)。将 offset 替换为 10360(十六进制 0x2878)来进行检查:
ldxdw r2, [r1 + 0x2878]
exit
运行该代码时生成此追踪记录:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 0: ldxdw r2, [r1+0x2878]
1 [0000000000000000, 0000000400000000, **BA2D9AF400000002**, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 1: exit
寄存器 r2 包含 BA2D9AF400000002。因为 ldxdw 加载 8 个字节,但指令数据只有 4 字节长,所以此次读取也包含了下一个字段的前 4 个字节。低 32 位(00000002)代表了我们以小端格式显示的指令数据 [2, 0, 0, 0]。
读取程序 ID
最后的 32 个字节包含了正在被调用的程序的程序 ID。由于我们的指令数据长度为 4 字节,它占据了偏移量 10360- 10363。程序 ID 紧随其后从偏移量 10364(十六进制 0x287C)开始。
为了检查它,我们可以跨四个寄存器加载完整的 32 个字节:
ldxdw r2, [r1+10364]
ldxdw r3, [r1+10372]
ldxdw r4, [r1+10380]
ldxdw r5, [r1+10388]
exit
运行程序并检查追踪文件:
Frame 0
0 [0000000000000000, 0000000400000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 29: ldxdw r2, [r1+0x287c]
1 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 30: ldxdw r3, [r1+0x2884]
2 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 31: ldxdw r4, [r1+0x288c]
3 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 32: ldxdw r5, [r1+0x2894]
4 [0000000000000000, 0000000400000000, C512BA35BA2D9AF4, 08D0A2FB506C1A71, 93EAF43A2BD4867A, B7CFB5A9E7B8C99A, 0000000000000000, 0000000000000000, 0000000000000000, 0000000000000000, 0000000200001000] 33: exit
这四个寄存器包含了以小端格式存储的完整程序 ID。为了重构程序 ID,我们将颠倒每个寄存器值的字节顺序,并将它们连接起来:
- r2:
C512BA35BA2D9AF4→F49A2DBA35BA12C5 - r3:
08D0A2FB506C1A71→711A6C50FBA2D008 - r4:
93EAF43A2BD4867A→7A86D42B3AF4EA93 - r5:
B7CFB5A9E7B8C99A→9AC9B8E7A9B5CFB7
将这些连接起来可以得到十六进制的 0xf49a2dba35ba12c5711a6c50fba2d0087a86d42b3af4ea939ac9b8e7a9b5cfb7,解码为 base58 即为 HTpqQdG7f44su3QsV3HHurraR1ZNjHAdArCy3qHKyKBC。这与我们 instructions.json 文件中的 program_id 字段一致。
使用空账户数组或无指令数据进行测试
当一笔交易的账户数组为空或没有指令数据时,VM 仅为计数类型的字段(账户数量和指令数据长度)保留空间,并且它们的值都将为 0。我们将在下一篇讨论 syscalls(系统调用)的文章中通过实际示例来演示这一点。
本文是 Solana 开发教程系列的一部分